
데이터 베이스 요약 - 1. Introduction
1.1. 데이터베이스 시스템의 응용(Database-System Applications)
대학, 항공, 통신 등 거의 모든 기업들에서 데이터베이스가 사용된다.
1.2. 데이터베이스 시스템의 목적(Purpose of Database Systems)
초기에는 정보를 운영체제의 파일시스템에 저장하여 다음과 같은 문제가 있었다. 따라서 데이터베이스 시스템이 개발되었다.
(1) 데이터의 중복과 비일관성: 데이터가 여러 다른 형식의 파일에 중복되어 저장되고, 비일관성(동일한 데이터의 여러 사본이 서로 다른 값을 가짐)이 생길 수도 있다.
(2) 데이터 접근 시의 난점: 새로운 작업(예: 특정 조건으로 검색)을 위해 새로운 프로그램을 만들어야 함.
(3) 데이터의 고립: 데이터가 여러 파일에 흩어져 있는데다, 파일 형식이 다를 수 있음.
(4) 무결성(integrity) 문제: “계좌 잔고는 0 이상이어야 한다” 와 같은 무결성 제약조건(integrity constraints)이 명시적으로 언급되지 않고, 프로그램 코드에 작성되어 있음. 새로운 제약조건을 추가하거나 기존 제약조건을 수정하는 것이 어려움.
(5) 원자성 문제(Atomicity problems): 고장이 데이터베이스를 일관성 없는 상태(예: 부분적으로만 갱신됨)로 만들 수 있음.
(6) 동시 접근 문제: 동시 접근은 성능을 위해 필요함. 제어되지 않은 동시 접근은 비일관성을 야기할 수 있음.
(7) 보안 문제: 사용자에게 모든 데이터의 접근을 허용하지 않고 데이터의 일부분의 접근만 허용하는 것이 어려움.
1.3. 데이터의 관점(View of Data)
데이터베이스 시스템은 서로 연관된 데이터들과 사용자에게 데이터에 대한 접근/수정을 제공하는 프로그램의 집합이다. 데이터베이스 시스템의 목적 중 하나는 사용자들이 데이터들이 어떻게 저장되고 관리되는지 알 필요없도록 추상적인 관점을 제공하는 것이다.
1.3.1. 데이터 모델들(Data Models)
데이터 모델이란 데이터, 데이터 간의 관계, 데이터 의미, 데이터 제약조건 등을 표현하기 위한 도구들의 모음이다. 아래와 같은 모델들이 존재한다.
- Relational model
- Entity-Relationship data model (데이터베이스 설계에 주로 사용됨)
- Object-based data models (Object-oriented and Object-relational)
- Semi-structured data model (XML 사용)
오래된 모델인 Netwokr, Hierarchical model을 포함하여 여러 다른 모델들이 있다.
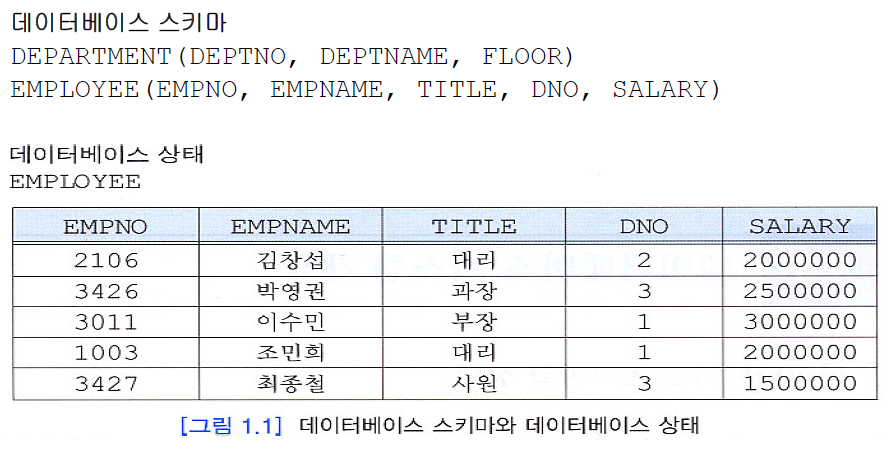
1.3.2. Relational Data Model
이 모델에서 데이터는 테이블 형태로 표현된다. 각 테이블은 여러 열(columns)이 있고, 각 열은 고유한 이름을 가진다. 테이블의 각 행은 하나의 정보를 나타낸다.
1.3.3. 데이터 추상화(Data Abstraction)
데이터베이스는 데이터를 효율적으로 사용하기 위해 복잡한 데이터 구조를 사용한다. 그리고 사용자가 사용하기 쉽게, 여러 단계의 추상화를 통해 복잡한 구조를 감춘다.
(1) 물리적 단계(physical level): 추상화 최하위 단계. 데이터가 실제로 어떻게(how) 저장되는지 기술한다.
(2) 논리적 단계(logical level): 다음 상위 단계. 어떤(what) 데이터가 저장되었는지, 데이터들 간의 관계를 기술한다.
(3) 뷰 단계(view level): 추상화 최상위 단계. 데이터베이스의 일부분만을 기술한다. 사용자는 데이터베이스의 일부분에만 관심이 있다. 한 데이터베이스에는 많은 뷰가 존재할 수 있다.
각 추상화 단계의 이해를 돕기 위해, 프로그래밍 언어의 데이터 타입(data type)의 개념에 유추하여 생각할 수 있다.
type instructor = record
ID : char (5);
name : char (20);
dept name : char (20);
salary : numeric (8,2);
end;
물리적 단계에서 위의 레코드는 연속된 바이트의 블록으로 표현될 수 있다. 컴파일러는 프로그래머에게 이러한 상세한 부분을 숨긴다.
논리적 단계에서 각 레코드는 타입 정의로 표현된다. 레코드들 사이의 관계도 이 단계에서 잘 정의되어야 한다.
뷰 단계에서 사용자는 데이터 타입의 상세한 부분을 알 필요없이 응용 프로그램을 사용한다.
1.3.4. 인스턴스와 스키마(Instances and Schemas)
프로그래밍 언어의 타입과 변수 개념과 유사하다.
논리적 스키마(logical schema)는 데이터베이스의 전체적인 논리구조이다. 예를 들어 한 데이터베이스는 은행의 계좌와 고객들, 그리고 이들 간의 관계에 대한 정보들로 구성된다. 변수의 타입 정보와 유사한 개념이다.
물리적 스키마(physical schema)는 데이터베이스의 전체적인 물리구조이다.
인스턴스(instance)는 특정 시점에서 데이터베이스의 실제 콘텐츠(content)이다. 변수의 값과 유사한 개념이다.
물리적 데이터 독립성(physical data independence)은 논리적 스키마를 수정할 필요 없이 물리적 스키마를 수정할 수 있는 능력이다. 애플리케이션은 논리적 스키마에 의존한다. 계층간의 인터페이스와 요소가 잘 정의되어, 한 쪽의 변화가 다른 쪽에 큰 영향을 주지 않아야 한다.
1.4. 데이터베이스 언어(Database Languages)
Data-definition language (DDL)와 data-manipulation language (DML)은 데이터베이스 언어(예: SQL)의 한 부분이다. DDL은 데이터베이스 스키마를 정의하기 위해 사용되고, DML은 데이터베이스 질의(queries)와 갱신을 위해 사용된다.