운영체제 요약 - 9. 가상 메모리
9.1. 배경(Background)
많은 경우에 프로그램 전체가 메모리에 늘 올라와 있어야 하는 것은 아니다. 프로그램에는 잘 사용되지 않는 기능들이 있으며, 전체 프로그램이 요구 되는 경우에도 모든 부분이 동시에 요구되지 않을 수 있다.
만약 프로그램의 일부분만 메모리에 올려놓고 실행한다면 다양한 이점을 얻을 수 있다. 각 프로그램이 더 작은 메모리를 차지하므로 더 많은 프로그램을 동시에 수행하며, 스왑 횟수도 줄어든다.
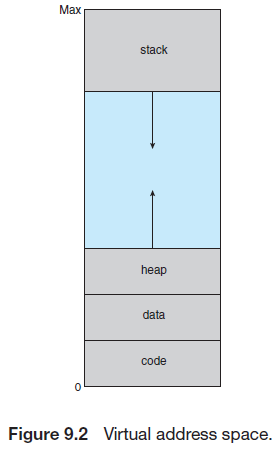
한 프로세스의 가상 주소 공간은 일반적으로 0번지에서 시작하여 연속적인 공간을 차지한다. 아래 부터 코드, 데이터 영역이 있다. 힙은 동적 할당 메모리를 사용함에 따라 가상 주소 공간상에서 위쪽으로 확장된다. 스택은 함수 호출을 거듭함에 따라 가상 주소 공간상에서 아래쪽으로 확장된다.
가상 메모리는 페이지 공유를 통해 파일이나 메모리의 공유를 더 쉽게 한다. 페이지는 fork() 시스템 호출을 통한 프로세스 생성 과정 중에 공유될 수 있기 때문에 프로세스 생성 속도도 높일 수 있다.
9.2. 요구 페이징(Demand Paging)
요구 페이징을 사용하는 가상 메모리에서는 페이지들이 실제로 필요해 질 때 메모리에 적재된다. 페이저(pager)는 프로세스 내의 개별 페이지들을 관리한다. 보조 메모리(보통 하드 디스크)에서 사용할 페이지를 가져온다.
9.2.1. 기본 개념
페이저는 프로세스의 어느 페이지가 디스크에 있고, 메모리에 있는지 알아야 한다. 여기서 하드웨어 지원이 필요한데, 8.4.3절의 페이지 테이블 유효-무효 비트가 사용될 수 있다.
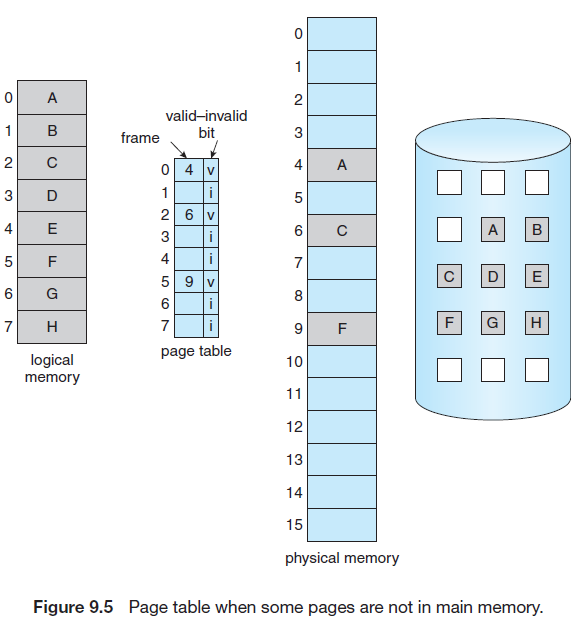
페이지 테이블 항목이 무효로 설정되있는 페이지를 접근하려고 하면 페이지 부재 트랩(page fault trap)이 발생한다.
- 프로세스에 대한 내부 테이블(일반적으로 프로세스 제어 블록(PCB))을 검사해서 그 메모리가 유효-무효인지를 알아낸다.
- 무효라면 프로세스를 중단시킨다. 유효이고 메모리에 없다면 디스크에서 가져온다.
- 빈 공간, 즉 자유 프레임에 해당 페이지를 올린다.
- 페이지 테이블과 프로세스 내부 테이블을 수정한다.
- 트랩에 의해 중단되었던 명령어를 다시 수행한다.
한 명령어가 여러 다른 장소를 수정할 때, 어려운 문제가 발생한다. 예를 들어, 256바이트를 한 장소에서 다른 장소(서로 겹칠 수도 있음)로 이동시키는 명령어가 있다. 원천 블록(source block)과 목적 블록(destination block)은 페이지 경계(page boundary)에 걸쳐 있을 수 있다. 이 경우, 이동이 다 끝나기도 전에 페이지 부재가 발생하여 명령어를 다시 실행시켜야 한다.
이러한 문제는 두 가지 방법으로 해결할 수 있다. 한 해결책은, 마이크로 코드(micro code)로 양 블록의 두 끝을 계산하여 겹치지 않는 것을 먼저 확인하는 것이다. 페이지 부재가 발생할 가능성이 있다면, 페이지 부재를 먼저 발생시킨다.
다른 방법은 이동에 의해 지워질 장소들의 값을 보관하기 위해 임시 레지스터들을 사용하는 것이다. 페이지 부재가 발생하면, 트랩 전에 이전 값을 복구한다. 그 후 명령어를 다시 수행한다.
9.2.2. 요구 페이징의 성능
페이지 부재는 인터럽트 처리, 페이지 읽기, 프로세스 재시작을 전부 처리해야 한다. 특히 하드 디스크에서 페이지를 읽어오는 시간이 메모리 접근에 비해 매우 느려서 컴퓨터 성능에 중요한 영향을 끼친다. 따라서 페이지 부재율을 낮게 유지하는 것이 중요하다.
요구 페이징의 또 다른 특성은 스왑 공간(swap space)의 관리와 사용이다. 스왑 공간에서의 디스크 입출력은 일반적인 파일 시스템보다 빠르다. 스왑 공간은 파일 시스템보다 더 큰 블록은 사용하고, 입출력을 할 때는 파일 찾기(lookup)나 간접 할당 방법 등을 사용하지 않기 때문이다(10장 내용).
어떤 시스템은 프로세스 시작 시 파일 이미지(file image) 전부를 스왑 공간으로 복사한 후, 스왑 공간에서 요구 페이징을 처리하기도 한다. 혹은 처음에는 파일 시스템으로부터 요구 페이징을 처리하지만, 교체할 때는 스왑 공간에 페이지를 기록할 수도 있다.
실행 파일(binary file, 이진 코드)을 스왑 공간에 넣지 않음으로써 스왑 공간의 크기를 줄이기도 한다. 실행 파일로부터 요구 페이징을 요청하면 파일 시스템으로부터 가져온다.
이 페이지들은 수정되지 않기 때문에(읽기 전용), 페이지의 교체가 필요하면 새 페이지의 내용을 그대로 덮어쓴다. 그러나 heap이나 stack처럼 원래 파일과 관계 없었던 페이지들은 스왑 공간이 여전히 필요하다.
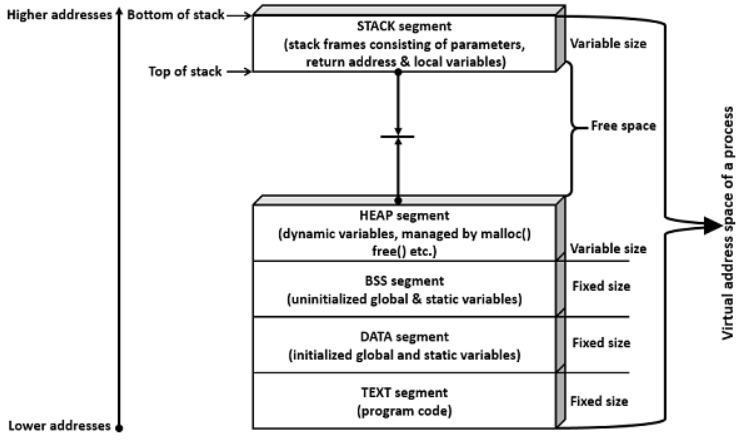
프로세스 이미지는 프로그램 실행에 필요한 실행 가능한 파일이다. 보통 코드, 데이터, 스택, 힙 세그먼트를 포함한다.
9.3. 쓰기 시 복사(Copy-on-Write)
부모 프로세스가 fork()로 자식 프로세스를 생성할 때 사용할 수 있는 방식이다. 자식 프로세스들은 대부분 exec() 시스템 호출을 하기 때문에, 부모로부터 복사해온 페이지들이 쓸모없어진다.
따라서 생성 시, 부모의 페이지를 다 복사하지 않고 잠시 공유한다. 자식이 페이지에 수정을 할 때에만 복사본을 생성하여 할당한다.
많은 운영체제에서 페이지 복사본을 만들 때, 빈 페이지는 빈 페이지 풀(pool)에서 가져온다. 빈 페이지는 쓰기 시 복사 혹은 스택, 힙 공간 확장할 때 사용된다. 운영체제는 보통 zero-fill-on-demand 기법으로 이전 내용을 다 0으로 채워 지운다.
9.4. 페이지 교체(Page Replacement)
프로세스의 페이지를 전부 메모리에 올리지 않음으로써, 더 많은 프로세스를 동시에 수행할 수 있다. 하지만 프로세스를 너무 많이 올리면 과할당(over-allocation)이 발생한다.
한 프로세스가 갑자기 모든 페이지를 요구했을 때, 메모리에 남은 프레임이 없을 수 있다. 이를 해결하기 위한 여러 페이지 교체 방법을 알아본다.
9.4.1. 기본적인 페이지 교체
페이지 교체는 다음과 같이 수행된다.
- 디스크에서 페이지를 찾아낸다.
- 빈 페이지 프레임이 있으면 사용한다.
- 없으면 페이지 교체 알고리즘을 통해 삭제할 프레임을 선정한다.
- 삭제할 프레임을 디스크에 기록하고, 프레임 테이블과 페이지 테이블을 수정한다.
- 프레임에 새 페이지를 적재하고 프레임 테이블과 페이지 테이블을 수정한다.
- 페이지 부재가 발생한 지점에서부터 프로세스를 재개한다.
빈 프레임이 없으면 디스크를 두 번(한 번은 프레임을 비울 때, 다른 한 번은 읽어 들일 때) 접근해야 한다. 접근 시간을 줄이기 위해 변경 비트(modify bit 또는 dirty bit)를 하드웨어에 추가한다.
변경 비트는 페이지가 수정되었음을 나타낸다. 변경 비트가 설정되어 있지 않다면 프레임을 디스크로 복사하지 않고 덮어쓴다. 이 경우에 디스크 접근 시간을 절반으로 줄일 수 있다.
요구 페이징 시스템은 프레임 할당(frame-allocation) 알고리즘과 페이지 교체(page-replacement) 알고리즘을 사용한다. 각 프로세스에 몇개의 프레임을 할당할지, 페이지 교체가 필요할 때 어떤 페이지를 교체할지 결정해야 한다.
9.4.2. FIFO 페이지 교체
FIFO를 사용한 가장 간단한 페이지 교체 알고리즘이 있다. 메모리에 올라온 지 가장 오래된 페이지를 교체한다.
9.4.3. 최적 페이지 교체
앞으로 가장 오랫 동안 사용되지 않을 페이지를 교체한다. 하지만 이 방식은 프로세스가 앞으로 메모리를 어떻게 참조할지 알아야 하기 때문에 구현이 어렵다. 따라서 주로 비교 연구 목적을 위해 사용된다.
9.4.4. LRU(Least-Recently-Used) 페이지 교체
가장 오랜 기간 동안 사용되지 않은 페이지를 교체한다. 각 페이지마다 마지막 사용 시간을 유지한다.
LRU 정책은 두 가지 구현 방법으로 가능하다.
- 계수기(counters): CPU에 계수기를 추가한다. 페이지 참조마다 시간 레지스터의 내용을 복사하여 마지막 참조 시간을 유지한다.
- 스택(stack): 밑바닥에 오래된 페이지를, 꼭대기에 최근 페이지를 둔다. 중간에서 갱신이 발생하면 이를 꼭대기로 옮기느라 오버헤드가 발생할 수 있다.
두 방법 모두 TLB 레지스터 이상의 하드웨어의 지원이 있어야 한다. 계수기 값과 스택을 갱신하는 일은 메모리 참조 마다 수행되는데, 이 작업을 소프트웨어로 하기에는 너무 느리다.
9.4.5. LRU 근사 페이지 교체(LRU Approximation Page Replacement)
LRU 페이지 교체를 충분히 지원할 수 있는 하드웨어는 거의 없다. 하지만 각 페이지와 대응되는 참조 비트는 어느 정도 지원되고 있다. 초기 참조 비트는 0이며, 참조되는 페이지의 비트는 하드웨어가 1로 세트한다.
9.4.5.1. 부가적 참조 비트 알고리즘(Additional-Reference Bits Algorithm)
일정한 간격마다 참조 비트들을 기록함으로써 추가적인 선후 관계 정보를 얻는다. 예를 들어, 각 페이지에 8비트를 대응시킨다.
그리고 일정 간격마다 8비트를 오른쪽으로 시프트 시키고, 참조비트를 8비트의 최상위 비트에 할당한다. 즉, 11001000 이 01100111 보다 최근에 사용된 페이지이다.
9.4.5.2. 2차 기회 알고리즘(Second-Chance Alogrithm)
기본적으로 FIFO 교체 알고리즘이다. 그러나 페이지가 선택될 때마다 참조 비트를 확인한다. 참조 비트가 0이면 교체하고, 1이면 0으로 세트하고 다음 FIFO 페이지로 넘어간다.
9.4.5.3. 개선된 2차 기회 알고리즘(Enhanced Second-Chance Algorithm)
2차 기회 알고리즘의 참조 비트에 변경 비트를 더하여 네가지 등급을 만들었다.
- (0, 0) 최근에 사용되지 않음, 변경되지 않음 - 교체하기 좋은 페이지
- (0, 1) 최근에 사용되지 않음, 변경됨 - 디스크에 내용을 기록해야 함
- (1, 0) 최근에 사용됨, 변경 되지 않음 - 다시 사용될 가능성이 높음
- (1, 1) 최근에 사용됨, 변경 됨 - 교체하기 좋지 않음
9.4.6. 계수-기반 페이지 교체(Couting-Based Page Replacement)
각 페이지를 참조할 때 계수를 하여 다음과 같은 두가지 기법을 만들 수 있지만 잘 쓰이지 않는다. 구현에 비용이 많이 들고, 최적 페이지 교체 정책을 제대로 근사하지 못한다.
- LFU(least frequently uesd): 참조 회수가 가장 작은 페이지를 교체
- MFU(most frequently used): 가장 작은 참조 회수를 가진 페이지가 가장 최근에 참조된 것이라 가정
9.4.7. 페이지-버퍼링 알고리즘(Page-Buffering Algorithm)
페이지 교체 알고리즘과 병행하여 여러 가지 버퍼링 기법이 사용될 수 있다. 한 가지 방법은 가용 프레임 여러 개를 풀(pool)로 가지고 있다가, 페이지 부재 시 교체될 페이지의 내용을 디스크에 기록하기 전에 가용 프레임에 새로운 페이지를 먼저 읽어 들이는 방법이다.
교체될 페이지가 다 쓰여 지고나면 그 프레임이 가용 프레임 풀에 추가된다. 따라서, 교체될 페이지가 쓰여지기를 기다리지 않고 프로세스가 가능한 빨리 시작할 수 있다.
변경된(modified) 페이지 리스트를 유지하는 방법도 있다. 디스크가 할 일이 없을 때, 변경된 페이지들을 디스크에 쓴 후 페이지의 변경 비트를 0으로 세트한다. 페이지를 교체할 때 페이지가 변경되지 않은 상태이기에 쓰기 작업이 불필요할 가능성이 높아진다.
가용 프레임의 각 프레임을 사용했었던 프로세스를 기억하는 방법도 있다. 같은 프로세스가 이를 재사용한다면, 프레임이 디스크에 기록된 후 수정되지 않았기 때문에 입출력 없이 바로 사용할 수 있다.
9.4.8. 응용(application)과 페이지 교체
몇몇 응용은 운영체제가 버퍼링 기능을 제공하지 않을 때 더 좋을 성능을 보일 때가 있다. 예를 들어, 데이터베이스는 스스로의 메모리와 디스크 사용 방식을 사용한다. 운영체제가 입출력 버퍼링을 하고 또 응용이 버퍼링을 하게 되면 같은 입출력에 대해 메모리가 두 배로 사용된다.
따라서 어떤 운영체제는 특별한 프로그램들에는 디스크 파티션을 파일 시스템 구조가 아닌 단순한 논리적인 블록들의 순차적인 배열로서 사용할 수 있게 해준다. 이 배열을 raw disk라고 부르며, 여기에 대한 입출력은 raw 입출력이라는 용어를 사용한다. Raw 입출력은 파일 시스템의 요구 페이징, 파일 잠금, 선반입, 공간 할당, 디렉토리 등의 모든 파일 시스템 서비스를 거치지 않는다.
9.5. 프레임의 할당
9.5.1. 최소로 할당해야 할 프레임의 수
각 프로세스에 최소한의 프레임은 할당해야 페이지 부재를 줄일 수 있다. 프로세스당 필요할 최소 프레임 수는 명령어 집합 아키텍처(instruction set architecture)에 의해 결정된다. 예를 들어, PDPP-11의 move 명령어는 특정 주소 지정 모드를 위해 하나 이상의 워드를 포함하고, 따라서 명령어 자체만으로 2페이지에 걸쳐 있을 수 있다.
최대 할당 수는 가용 물리 메모리에 의해 결정된다.
9.5.2. 할당 알고리즘
가장 쉬운 할당 방법은 모든 프로세스에게 똑같이 할당하는 균등 할당이다. 다른 대안은 프로세스의 크기 비율에 맞추어 할당하는 비례 할당 방식이 있다.
9.5.3. 전역 대 지역 할당(Global Versus Local Allocation)
다수의 프로세스가 경쟁하는 환경에서 페이지 교체 알고리즘은 크게 두 가지 범주, 즉 전역 교체(global replacement)와 지역 교체(local replacement)로 나눌 수 있다.
전역 교체는 교체할 프레임을 다른 프로세스에 속한 프레임을 포함한 모든 프레임을 대상으로 찾는 경우이다.
지역 교체는 자기에게 할당된 프레임들 중에서만 선택하는 경우이다.
전역 교체에서 한 프로세스의 페이지 부재율은 그 프로세스가 어떠한 프로세스들과 함께 실행되느냐에 영향을 받는다.
지역 교체에서는 프로세스 자신의 페이징 형태에만 영향을 받는다. 그러나 잘 안쓰이는 페이지 프레임이 있더라도 그것을 낭비할 수 있다.
일반적으로 전역 교체 방법이 더 좋은 성능을 보이며, 많이 사용된다.
9.5.4. 비균등 메모리 접근(NUMA, Non-Uniform Memory Access)
다수의 CPU를 가진 시스템에서 특정 CPU는 주 메모리의 일정 영역을 다른 영역보다 빠르게 접근할 수 있다.
시스템은 여러 시스템 보드들로 구성되고 각 보드는 다수의 CPU와 일정 메모리를 장착할 수 있다. 특정 보드 상의 CPU는 같은 보드의 메모리를 더 빠르게 접근할 수 있다. 메모리 접근 시간이 차이가 나는 시스템을 비균등 메모리 접근 시스템이라고 한다.
어느 페이지를 어느 프레임에 할당하느냐 하는 정책이 NUMA 성능에 영향을 미친다. 따라서 프로세스를 실행 중인 CPU에서 최소 지연 시간을 가진 메모리 프레임에 할당해야 한다. 통상 CPU와 같은 보드에 장착된 메모리를 의미한다.
스케줄러는 프로세스가 마지막으로 실행된 CPU에 스케줄하고, 메모리 관리 시스템은 스케줄 된 CPU와 가까운 프레임에 할당한다. 이는 캐시 적중률을 높이고 메모리 접근 시간을 감소시킨다.
스레드를 고려하면 상황은 더욱 복잡해진다. Solaris는 커널 내에 lgroup이라는 개체를 만들어 가까운 CPU와 메모리를 모은다. 프로세스의 모든 스레드와 메모리 할당을 lgroup 단위로 처리한다. 만일 이것이 불가능하다면, 필요한 나머지 자원에 대해서는 가까운 lgroup을 선택하여 할당한다.
9.6. 스레싱(Thrashing)
어떤 프로세스에게 할당된 프레임 수가 명령어 집합 아키텍처가 요구하는 최소한의 수보다 적게 되면, 그 프로세스의 모든 페이지를 포기하고 실행을 중단하여야 한다. 이러한 상황을 위해 스왑 인(swap-in), 스왑 아웃(swap-out)단위의 CPU 스케줄링이 필요하다.
충분한 프레임을 할당받지 못한 프로세스는 페이지 부재가 발생한다. 이때, 모든 페이지들이 활발하게 사용되고 있다면, 어떤 페이지가 교체되든 바로 다시 필요해질 것이다. 결과적으로 반복해서 페이지 부재가 발생할 수 있다.
이러한 과도한 페이징 작업을 스레싱이라 부른다. 어떤 프로세스가 실행보다 더 많은 시간을 페이징에 사용하고 있을 경우 스레싱이 발생했다고 한다.
9.6.1. 스레싱의 원인
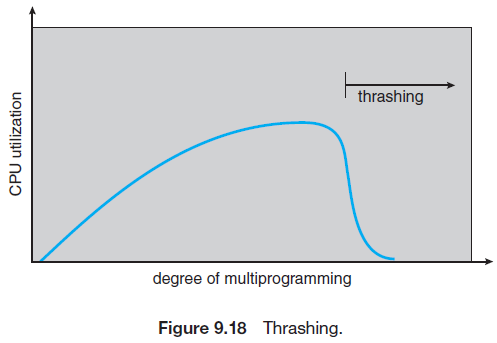
운영체제는 CPU의 이용률을 감시한다. 이용률이 낮을 경우 새로운 프로세스를 추가하여 다중 프로그래밍의 정도를 높인다.
하지만 많은 프로세스로 인해 페이지 부재가 반복적으로 발생하여 CPU 이용률이 떨어졌을 때도, CPU는 이용률을 높이기 위하여 새로운 프로세스를 추가할 수도 있다.
다중 프로그래밍의 정도가 너무 커지면 스레싱이 일어나게 되고 CPU 이용률은 급격히 떨어진다. 따라서 이 지점에서는 스레싱을 중지시키기 위해 다중 프로그래밍 정도를 낮춰야만 한다.
스레싱 현상을 방지하기 위해서는 프로세스가 필요로 하는 프레임 개수를 보장해야 한다. 프로세스가 필요로 하는 프레임 개수를 아는 방법 중 하나는 작업 집합 방법이다.
9.6.2. 작업 집합 모델(Working-Set Model)
이는 프로세스가 사용하고 있는 프레임의 수를 지역성 모델(locality model)을 기반으로 계산한다. 지역성 모델이란 프로세스가 실행될 때에는 항상 어떤 특정한 지역에서만 메모리를 집중적으로 참조함을 말한다. 그리고 지역이란, 집중적으로 함께 참조되는 페이지들의 집합을 의미한다.
기본 아이디어는 최근 n개 만큼의 페이지 참조를 관찰하는 것이다. 여기서, 최근 참조된 n개의 페이지들을 작업 집합(중복 제외)이라고 한다.
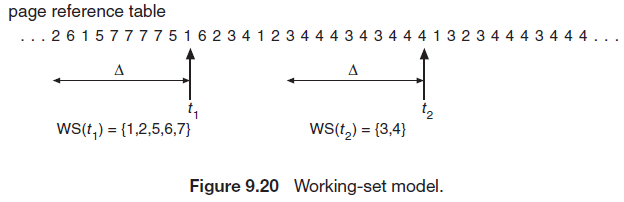
이 모델의 가장 중요한 요소는 집합의 크기(working-set size, WSS)이다. 각 프로세스는 WSS크기의 프레임을 요구하며, 전체 요구량은 프로세스들의 WSS를 모두 합친 값이다. 만약 시스템이 보유한 총 메모리 크기 보다 전체 요구량이 커지면, 어떤 프로세스는 지역을 위한 충분한 프레임을 메모리에 가질 수 없게 되기 때문에 스레싱을 유발한다.
메모리에 여유가 있다면 새로운 프로세스를 실행 시키고, 전체 요구량이 더 커진다면 한 프로세스를 중지시키고 페이지들을 가져온다.
이 방법은 작업 집합(최근 참조된 페이지)을 추적해야 한다. 고정 간격 타이머 인터럽트(fixed-interval timer interrupt)와 참조 비트(reference bit)로 유사한 모델을 근사할 수 있다.
예를 들어, n이 10,000이고 매 5,000번의 참조마다 타이머 인터럽트를 건다고 가정하자. 타이머 인터럽트가 걸릴 때마다 각 페이지의 참조 비트 값을 저장해 두고 참조 비트를 0으로 초기화한다.
따라서 페이지 부재가 발생하면, 바로 앞 10,000에서 15,000번의 참조 사이에 그 페이지가 사용되었는 지를 현재 참조 비트와 저장된 참조 비트로 알 수 있다. 만약 그 페이지가 사용되었으면 어느 한 비트라도 1일 것이고, 사용되지 않았으면 모두 0이다.
하지만, 참조가 과거 5,000번 중 언제 발생했는지를 정확히 알 수는 없다. 과거 기억 비트수를 늘리고 타이머 인터럽트 빈도를 높이면 (예를 들어, 10비트를 기억하고 인터럽트를 매 1000번의 참조마다 발생시키면) 불확실성을 줄일 수 있다. 그러나 자주 발생되는 인터럽트 처리 오버헤드도 그에 따라 증가할 것이다.
9.6.3. 페이지 부재 빈도(Page-Fault Frequency)
스레싱이랑 페이지 부재율이 너무 높은 것을 의미한다.
페이지 부재율이 너무 높으면 프로세스가 더 많은 프레임을 필요로 한다는 의미이고, 낮으면 프로세스가 너무 많은 프레임을 갖고 있다는 것을 의미한다.
따라서 페이지 부재율의 상한과 하한을 정해 놓고, 페이지 부재율이 상한을 넘으면 그 프로세스에게 프레임을 더 할당해 주고, 하한보다 낮아지면 그 프로세스의 프레임 수를 줄인다.
만약 페이지 부재율이 높아졌는데, 줄 수 있는 프레임이 없으면 한 프로세스를 선택하여 스왑 아웃시킨다.
9.7. 메모리 사상 파일(Memory-Mapped Files)
open, read, write 시스템 호출은 파일을 엑세스할 때마다 디스크를 접근해야 한다. 대신 프로세스의 가상 주소 공간 중 일부를 파일에 할당하는 메모리 사상을 통해 성능을 향상시킬 수 있다.
9.7.1. 기본 기법
파일의 메모리 사상은 프로세스의 페이지 중 일부분을 디스크에 있는 파일의 블록에 사상함으로써 이루어진다. 그 이후의 read, write는 일반적인 메모리 엑세스와 같이 처리된다.
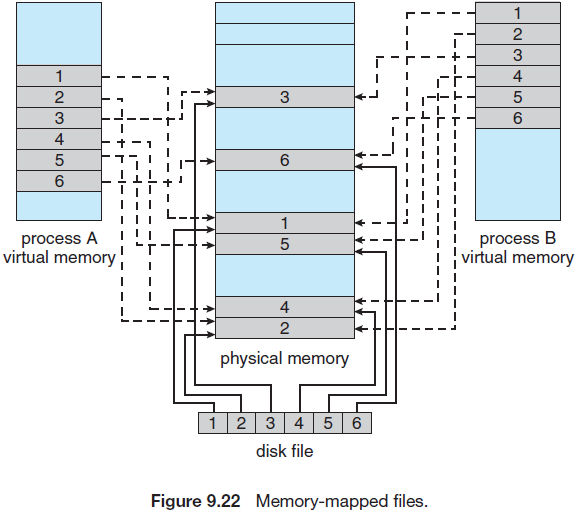
메모리에 사상 된 파일에 대한 write는 디스크에 즉시 write 되지 않을 수도 있다. 운영체제가 주기적으로 디스크에 반영할 수도 있고, 파일을 close할 때 디스크로 변경 내용을 적을 수도 있다.
메모리 사상 파일을 여러 프로세스들이 데이터 공유를 위해 공유하는 수도 있다.
9.7.2. 메모리 사상 입출력
입출력 작업 시에 각 입출력 처리기는 명령어와 전송할 데이터를 담기 위한 레지스터들을 포함하고 있다. 이러한 레지스터와 시스템 메모리 간의 데이터 전송에는 대개 특별한 입출력 명령어가 사용된다.
좀 더 편리하게 접근할 수 있도록, 많은 컴퓨터 아키텍처는 메모리 사상 입출력 기능을 제공하고 있다. 특정 메모리 영역을 장치 레지스터들을 사상할 수 있도록 유보해 둔다. 이러한 주소에 대한 읽기, 쓰기 작업은 장치 레지스터로의 데이터 전송으로 처리된다.
9.8. 커널 메모리의 할당
사용자 프로세스가 추가적인 메모리를 요구하면 커널이 관리하는 가용 페이지 프레임에서 페이지들이 할당된다. 그러나 커널 메모리는 별도의 메모리 풀에서 할당 받는다.
이유는 다음과 같다.
- 커널은 다양한 크기의 자료구조를 사용하며, 이들은 페이지 크기보다 작은 크기를 갖기도 한다. 때문에 단편화에 의한 낭비를 최소화 해야 한다. 특히 많은 운영체제들이 커널 코드나 데이터를 페이징 하지 않기 때문에 더 중요하다.
- 사용자 프로세스에 할당되는 페이지들은 물리 메모리 상에서 연속된 것일 필요는 없다. 그러나 물리 메모리에 직접 접근하는 특정 하드웨어 장치는 연속적인 메모리를 필요로 하는 경우가 있다.
9.8.1. 버디 시스템(Buddy System)
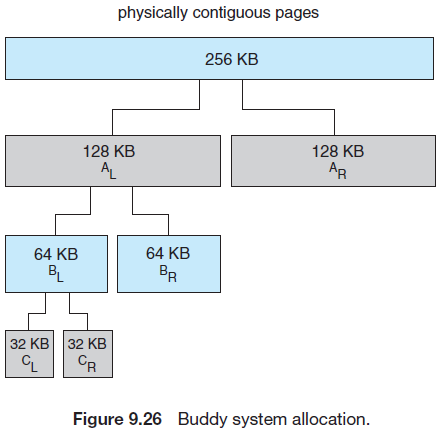
버디 시스템은 물리적으로 연속된 페이지들로 이루어진 고정된 크기의 세그먼트로부터 메모리를 할당한다. 메모리는 이 세그먼트로부터 2의 거듭제곱 할당기에 의해 2의 거듭제곱 단위(4KB, 8KB, …) 올림으로 할당된다. 남은 공간은 내부 단편화이다.
9.8.2. 슬랩 할당(Slab Allocation)
슬랩은 하나 이상의 연속된 페이지들로 구성된다. 캐시는 하나 이상의 슬랩으로 구성된다.
그리고 커널 자료구조마다 하나의 캐시가 있다. 각 캐시는 커널 자료구조의 instance 객체들로 채워져 있다.
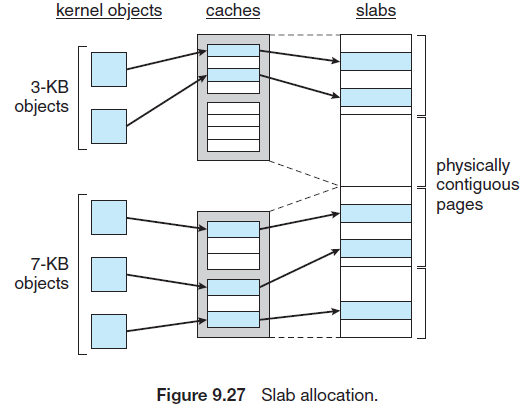
캐시가 생성되면 초기에 free라고 표시된 몇 개의 객체들이 캐시에 할당된다. 커널 자료구조 객체가 필요하면 free 객체들 중 하나를 캐시로부터 할당해주고 used라고 표시한다.
아래는 Linux의 예시이다. 슬랩은 다음과 같은 세 가지 상태 중 한 상태에 있다.
- Full: 슬랩 내 모든 객체가 used
- Empty: 슬랩 내 모든 객체가 free
- Partial: used, free 객체가 섞여 있음
슬랩 할당기는 먼저 Partial 슬랩의 free 객체를 사용하고, 없다면 Empty 슬랩으로부터 free 객체를 할당한다. Empty 슬랩도 없는 경우, 새로운 슬랩이 연속된 물리 메모리에서 할당되어 캐시에 주어진다. 객체는 이 슬랩에서 할당된다.
슬랩 할당기는 두 가지 주요 장점이 있다.
- 단편화에 의해 낭비되는 메모리가 없다. 커널 자료구조는 연관된 캐시를 가지며, 각 캐시는 객체 크기로 분할된 슬랩으로 구성되었기에 단편화 문제가 없다. 즉, 메모리를 할당할 때, 슬랩 할당기는 필요한 만큼의 메모리만 할당한다.
- 메모리 요청이 빠르게 처리된다. 객체들은 미리 생성되어 있고 캐시에서 쉽게 할당 가능하다. 특히 커널이 객체를 사용하고 해제하면 free로 표시된 상태로 캐시로 반환되어, 다음 요구 시 즉시 할당이 가능하다.
9.9. 기타 고려 사항
9.9.1. 프리페이징(Prepaging)
페이징 시스템은 프로세스가 시작될 때 많은 페이지 부재가 발생한다. 최초의 지역을 메모리에 올리기 위한 현상이다. 이 현상은 스왑 아웃되었던 프로세스가 다시 들어올 때도 발생한다.
프리페이징은 과도한 페이지 부재를 방지하기 위한 기법으로, 관련된 모든 페이지를 사전에 한꺼번에 메모리 내로 가져오는 기법이다. 예를 들어 작업 집합을 가지는 시스템에서는, 프로세스의 작업 집합을 기억하고 재시작 전에 작업 집합을 모두 메모리에 올려놓는다.
9.9.2. 페이지 크기(Page size)
이미 존재하는 시스템의 운영체제는 페이지 크기를 바꾸는 것이 거의 불가능하다. 새 시스템을 개발할 때는 페이지 크기를 결정해야 한다. 최적은 없다.
페이지 크기가 크면
- 페이지 테이블에 사용되는 메모리가 줄어든다.
- 페이지를 적게 참조하여 디스크 입출력 시간이 짧아진다.
- 페이지 부재 횟수를 줄일 수 있다.
페이지 크기가 작으면
- 내부 단편화를 최소화 할 수 있다.
- 지역성 향상, 즉 실제로 필요한 정보만을 메모리로 가져와 전체 입출력이 줄어든다.
9.9.3. TLB Reach
TLB hit ratio와 연관된 것에는 TLB reach 가 있다.
TLB reach는 TLB로부터 접근할 수 있는 메모리 공간의 크기를 뜻한다. TLB에 있는 항목 수에 페이지 크기를 곱한 것이다.
TLB를 크게 만드는 것은 비싸고 전력이 많이 소모된다. TLB reach를 늘릴 수 있는 다른 방법은 페이지 크기를 늘리던가 여러 가지의 페이지 크기를 허용하는 방법이다.
그러나 여러 가지 크기의 페이지를 수용하려면 하드웨어가 아니라 운영체제가 TLB를 관리해야 한다. TLB 내의 한 필드가 대응되는 페이지 프레임의 크기를 나타내야 한다.
소프트웨어로 하게 되면 성능이 다소 손해보지만, hit ratio와 TLB reach의 향상으로 상쇄될 수 있다. 따라서 TLB관리를 소프트웨어가 하는 경우도 있다.
9.9.4. 역 페이지 테이블(Inverted Page Table)
역 페이지 테이블은 각 프레임에 어떤 가상 페이지가 저장되어 있는지의 정보만 유지하여 필요 물리 메모리양을 줄인다. 하지만 전체 가상 주소 공간에 대한 정보를 유지하지 않으므로, 참조된 페이지가 현재 메모리에 없을 때에는 문제가 된다. 요구된 페이지가 디스크 내 어디에 있는지를 알 수가 없다.
따라서 프로세스 마다 확장된 페이지 테이블(extended page table)을 유지해야 한다. 원래 페이지 테이블은 메모리 참조 때마다 사용되지만, 이 확장된 테이블은 페이지 부재 시에만 참조되기에 빨리 읽어야 할 필요가 없다.
그러므로 확장된 테이블은 그 자체가 페이징될 수도 있다. 이때 확장된 테이블을 읽어 들이기 위해 또 다른 페이지 부재가 발생할 수 있으며, 페이지 lookup 처리 시에 시간 지연이 발생한다.
9.9.5. 프로그램 구조
페이지가 128워드 크기이고 배열이 행 중심으로 저장되었다고 가정하자. 그러면 프로그램에서 배열 접근 순서가 페이지 부재 횟수에 영향을 줄 수 있다.
int i, j;
int[128][128] data;
// data[0][0], data[0][1], ... 순으로 접근 -> 페이지 부재 128
for (i = 0; i < 128; ++i)
for (j = 0; j < 128; ++j)
data[i][j] = 0;
// data[0][0], data[1][0], ... 순으로 접근 -> 페이지 부재 128 * 128
for (j = 0; j < 128; ++j)
for (i = 0; i < 128; ++i)
data[i][j] = 0;
컴파일러는 코드와 데이터를 분리하고 재진입 가능 코드를 생성하여 코드 페이지를 읽기 전용으로 만들 수 있다. 코드 페이지가 변경되지 않으므로, 페이지 교체 시 디스크에 내용을 저장할 필요가 없다.
로더는 하나의 루틴을 페이지 경계에 걸치지 않도록 할당하여, 각 루틴이 한 페이지 내에 완전히 들어가도록 할 수 있다. 또한 서로 호출하는 빈도수가 많은 루틴들끼리는 서로 같은 페이지에 위치시킬 수 있다. 페이지 간 참조를 최소화되도록 하는 것이다.
9.9.6. 입출력 상호 잠금(I/O Interlock)과 페이지 잠금(locking)
요구 페이징을 사용할 때, 페이지를 메모리에 고정시키는 것이 필요한 때가 있다. 이런 상황은 입출력이 사용자(가상 메모리) 공간에서 이루어질 때 발생한다.
프로세스의 입출력 요구가 입출력 장치의 큐에 들어가고 CPU가 다른 프로세스에게 할당된다. 다른 프로세스가 페이지 부재를 일으키고, 하필 대기 중인 프로세스의 버퍼 메모리를 포함한 페이지를 교체한다. 이는 입출력 작업을 마친 프로세스가 원래 프레임을 사용할 수 없게 한다.
일반적인 해결책은 두 가지 방법이 있다. 한 해결책은 사용자 공간에는 입출력을 하지 않는 것이다. 항상 시스템(커널) 공간과 입출력 장치 사이에서만 한다. 이는 데이터가 시스템 버퍼로 이동한 후 사용자 버퍼로 가는, 두 번 움직이는 오버헤드가 있다.
다른 해결책은 프레임마다 잠금 비트(lock-bit)를 두고, 프레임이 잠기면 교체 대상에서 제외하는 것이다. 잠금 비트는 다양한 상황에서 사용되며, 메모리 관리를 담당하는 커널 또는 특정 커널 모듈에서 사용할 수도 있다. 또한 메모리 영역을 직접 관리하는 데이터베이스 프로세스도 이를 사용 가능하다.
잠금 비트 사용은 위험한 상황을 만들 수도 있다. 잠금 비트가 해제가 되지 않아 잠긴 프레임이 영원히 사용되지 못할 수 있다.
댓글남기기