운영체제 요약 - 11. 파일 시스템 구현
11.1. 파일 시스템 구조
파일 시스템을 유지하기 위한 보조 저장장치로 디스크가 대부분 사용된다. 디스크는 임의의 블록에 직접 접근할 수 있고, 메모리와 디스크간의 입출력 전송은 블록 단위로 수행된다. 각 블록은 하나 이상의 섹터이다.
파일 시스템은 여러 층으로 이루어져 있다. 각 층은 낮은 층의 기능을 사용하여 새로운 기능을 만들어 상위 층에게 제공한다.
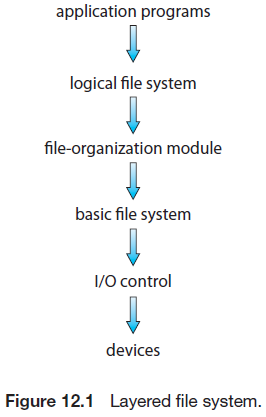
입출력 제어 층은 장치 드라이버와 인터럽트 핸들러로 이루어져 있어서 메모리와 디스크 시스템간의 정보 전송을 담당한다. 장치 드라이버는 번역기라고 생각할 수 있다. 입력은 “블록 123을 인출하라”와 같은 고 수준의 명령이고, 출력은 특정 하드웨어에 맞는 저수준의 명령이다.
이는 입출력 장치와 시스템과의 소통을 해주는 하드웨어 제어기에 의해 사용된다. 장치 드라이버는 입출력 제어기 메모리의 특별한 위치에 특정 비트를 설정하여 제어기에게 어느 장치에 어떤 일을 수행할지를 알린다.
그 다음 층인 기본 파일 시스템(basic file system) 층은 적절한 장치 드라이버에게 디스크 상의 물리 블록을 읽고 쓰도록 일반적인 명령을 내리는 층이다. 또한 파일 시스템, 디렉터리 및 데이터 블록을 저장하는 메모리 버퍼와 캐시를 관리한다.
그 위의 파일-구성 모듈(file-organization module) 층은 파일의 논리 블록과 물리 블록들 양쪽을 알고 있어야 한다. 파일 할당 타입과 파일의 위치를 앎으로써 파일에 대한 논리 블록 주소를 물리 블록 주소로 변환할 수 있다. 어느 디스크 공간이 비어있는지를 파악하는 자유 공간 관리자도 포함하고 있다.
마지막으로 논리 파일 시스템(logical file system) 층은 메타데이터 정보를 관리한다. 메타데이터는 파일의 내용 자체인 데이터를 제외한 모든 파일 시스템 구조를 말한다. 파일 이름이 심볼릭일 때 이를 해석하며, 디렉터리 구조도 관리한다. 파일 구조는 파일 제어 블록(File Control Block, FCB)로 유지되며, 이는 소유, 허가 그리고 파일 내용의 위치를 포함하여 파일에 관한 정보를 가지고 있다.
11.2. 파일 시스템 구현
11.2.1. 개요
여러 디스크 상의 구조와 메모리 내 구조가 파일 시스템을 구현하는 데 사용된다. 이들은 운영체제와 파일 시스템에 따라 다르지만, 몇 개의 일반적인 원칙은 공동 적용된다.
디스크 상의 구조는 다음을 포함한다.
- 부트 제어 블록은 시스템이 그 파티션으로부터 운영체제를 부트시키는 데 필요한 정보를 가지고 있다. 디스크가 운영체제를 가지고 있지 않다면 부트 제어 블록은 비어 있다. 부트 제어 블록은 일반적으로 한 파티션의 첫 번째 블록이다.
- 볼륨 제어 블록은 볼륨(또는 파티션)의 블록 수, 블록 크기, 자유 블록 수와 포인터, 그리고 자유 FCB 수와 포인터 같은 파티션 정보를 포함한다.
- 디렉터리 구조는 파일을 조직화하는데 사용된다. 파일 이름 등이 저장된다.
- 파일별 FCB는 자세한 파일 정보를 가지고 있다. FCB는 디렉터리 항목과의 연결을 위하여 고유한 식별 번호를 가지고 있다.
메모리내의 정보는 파일 시스템 관리와 캐싱을 통한 성능 향상을 위해 사용된다. 다수의 자료구조 유형이 이 안에 포함된다.
- 메모리 내 파티션 테이블은 각 마운트된 파티션 정보를 포함한다.
- 메모리 내 디렉터리 구조는 최근 접근된 디렉터리의 디렉터리 정보를 가진다.
- 범 시스템 오픈 파일 테이블(system wid open file table)은 다른 정보외에 오픈된 각 파일 FCB의 복사본을 가지고 있다.
- 프로세스 별 오픈 파일 테이블(per-process open file table)은 다른 정보외에 범 시스템 오픈 파일 테이블 항목에 대한 포인터를 포함한다.
- 버퍼는 파일 시스템이 디스크로부터 읽혀지거나 써질 때 파일 시스템 블록을 저장한다.
새로운 파일을 생성하기 위해 응용 프로그램은 디렉터리 구조의 포맷을 알고 있는 논리 파일 시스템을 호출한다. 파일 시스템은 새로운 FCB를 할당하고, 해당 디렉터리를 메모리로 읽어, 새로운 파일 이름과 FCB로 디렉터리를 갱신하여, 디스크에 다시 쓴다.
open() 시스템 호출은 파일이 다른 프로세스에 의해 사용 중인지 확인하기 위해 범 시스템 오픈 파일 테이블을 검색한다. 사용 중이면, 범 시스템 오픈 파일 테이블을 가르키는 프로세스별 오픈 파일 테이블 항목이 생성된다.
파일이 오픈되지 않았다면, 파일 이름을 디렉터리 구조에서 찾는다. 파일이 발견되면 FCB가 메모리내의 범 시스템 오픈 파일 테이블에 복사된다. 이 테이블은 FCB뿐만 아니라, 파일을 오픈한 프로세스의 수도 저장한다.
다음으로, 범 시스템 오픈 파일 테이블의 항목을 가르키는 포인터와 몇 개의 다른 필드를 갖는 새로운 항목이 프로세스 별 오픈 파일 테이블에 만들어진다. 이 필드들은 현재 파일 위치 포인터와 접근 모드 등을 포함한다. open() 시스템 호출은 프로세스 별 파일 시스템 테이블의 해당 항목에 대한 포인터를 돌려준다.
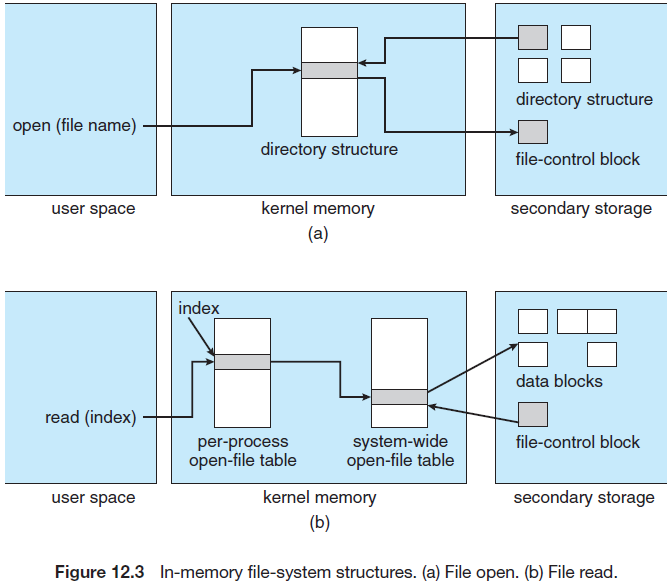
해당 FCB를 디스크에서 찾으면 시스템은 파일 이름을 사용하지 않기에, 파일 이름은 오픈 파일 테이블의 한 부분이 아니다. 그러나 이것은 같은 파일에 대한 다중 오픈 연산을 빠르게 하기 위해서 캐쉬될 수 있다. UNIX에서는 이것을 파일 디스크립터라 부르고, Windows는 파일 핸들이라 한다.
프로세스가 파일을 닫으면, 프로세스 별 테이블 항목이 삭제되며, 범 시스템 항목의 오픈 계수는 감소된다. 오픈했던 모든 사용자가 파일을 닫으면 디스크 기반 디렉터리 구조에 업데이트 된 파일 정보가 복사되며, 범 시스템 오픈 파일 테이블에서 그 항목이 삭제된다.
11.2.2. 파티션과 마운팅(Partitions and Mounting)
각 파티션은 파일 시스템을 포함하지 않은 미가공(raw) 파티션이나, 포함하는 가공(cooked) 파티션으로 나누어질 수 있다. Raw 디스크는 파일 시스템이 사용되지 않는 곳에 사용된다. UNIX의 스왑 공간이나 몇몇 데이터베이스은 자신의 고유 포맷을 활용하여 raw 디스크를 사용한다.
부트 정보는 별도의 파티션에 저장될 수 있다. 부트 정보는 자신의 형식을 가지는데, 부트할 때 시스템은 파일 시스템 코드가 적재되어 있지 않기에 파일 시스템 형식을 해석할 수가 없기 때문이다.
부트 정보는 통상 일련의 순차 블록으로, 메모리에 하나의 이미지로 로드된다. 이 이미지의 실행은 첫 번째 바이트 같은 미리 정해진 위치에서부터 시작된다.
부트 로더는 커널의 위치를 찾아 적재하고 실행할 수 있도록 파일 시스템의 구조를 알고 있다. 또한 최소한 특정 운영체제를 부트할 수 있는 명령어들을 포함하고 있다.
운영체제 커널과 더불어 다른 시스템 파일을 포함할 수도 있는 루트 파티션은 부트 시에 마운트된다. 다른 파티션은 부트 시에 자동으로 마운트되거나 운영체제에 따라 수동으로 나중에 마운트된다.
마운트 연산 중에 운영체제는 시스템이 유효한 파일 시스템을 가지고 있는가를 확인한다. 운영체제는 디바이스 드라이버에게 디바이스 디렉터리를 읽도록 요청하고, 유효한 포맷을 가졌는지 확인한다.
11.2.3. 가상 파일 시스템(Virtual File System, VFS)
대부분의 운영체제는 구현을 단순화하고, 조직화하고, 모듈화하기 위해 객체 지향 방법을 사용한다. 이러한 방법을 통해 NFS와 같은 네트워크 파일 시스템을 포함하여 크게 다른 파일 시스템 타입이 같은 구조 안에 구현되는 것을 허용한다. 구현 세부 사항으로부터 시스템 호출 기능을 격리시키기 위해 자료구조와 프로시저가 사용된다.
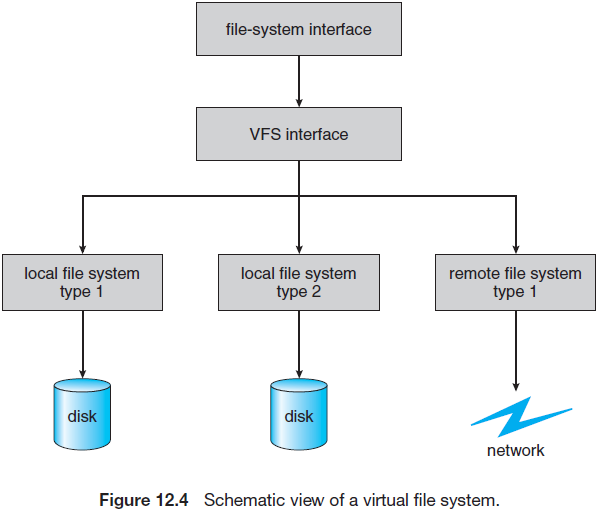
파일 시스템 구현은 세 가지 주요한 계층으로 구성된다. 첫 번째 계층은 열기, 읽기, 쓰기, 그리고 닫기 호출과 파일 디스크립터에 기반을 둔 파일 시스템 인터페이스이다.
두 번째 계층은 가상 파일 시스템 계층으로 두 가지 중요한 기능을 제공한다.
- VFS 인터페이스를 정의함으로써 파일 시스템의 일반적 연산을 구현과 분리시킨다. VFS 인터페이스에 대한 여러 구현들이 같은 기계 상에 공존할 수 있으므로, 지역적으로 마운트된 다른 형태의 파일 시스템에 대한 투명한 접근을 제공한다.
- 네트워크에 속한 파일을 고유하게 표현하는 방법을 제공한다. VFS는 vnode라 불리는, 파일 표현 구조(file-representation structure)에 기반을 둔다. vnode는 네트워크에서 고유한 파일에 대한 수치 지정자(designator)를 포함하고 있다. 네트워크 파일 시스템을 지원하려면 이런 네트워크 전체의 유일성(network-wide uniqueness)이 필요하다. 커널은 각 활성 노드(파일/디렉터리)에 대해 하나의 vnode 구조를 가진다.
이렇게 VFS는 원격 파일과 로컬 파일을 구분하고, 로컬 파일들은 파일 시스템 타입에 따라 더 세부적으로 구분된다.
VFS는 특정 파일 시스템의 명령을 활성화시킴으로써 파일 시스템에 따른 로컬 요청들을 처리하며, 원격 요청에 대해서는 NFS 프로토콜 프로시저를 호출한다. 파일 핸들은 관련된 vnode들로 구성되며, 프로시저에 매개변수로 전달된다. 파일 시스템 타입이나 원격 파일 시스템 프로토콜을 구현하는 계층은 그 구조의 최하부(3단계) 계층이다.
Linux에서의 VFS 사용 예는 다음과 같다. Linux VFS에는 네 가지 기본 객체 타입이 있다.
- inode object: 각 파일을 나타냄
- file object: 열린 파일을 나타냄
- superblock object: 전체 파일 시스템을 나타냄
- dentry object: 각 디렉터리 엔트리를 나타냄
네 가지 각 객체 타입에 대하여, VFS는 구현 가능한 연산의 집합을 정의하였다. 이러한 객체 타입들에 해당되는 모든 오브젝트는 대응되는 함수 테이블에 대한 포인터를 가지고 있다. 함수 테이블은 정의된 연산을 구현한 함수의 주소들을 가지고 있다.
따라서 VFS는 어떤 객체에 대한 연산을 객체의 함수 테이블에서 적절한 함수를 호출함으로써 수행할 수 있다. VFS는 객체가 어떤 타입(디스크 파일인지, 디렉터리 파일인지, 원격 파일인지)인지 알 필요가 없다.
11.3. 디렉터리 구현
11.3.1. 선형 리스트(Linear List)
디렉터리를 구현하는 가장 간단한 방법은 파일 이름과 데이터 블록에 대한 포인터들의 선형 리스트를 사용하는 것이다. 그러나 이 방법은 파일을 찾기 위해 선형 탐색을 하여 실행 시간이 길다.
정렬된 리스트는 이진 탐색을 가능케 하여 탐색 시간을 줄일 수 있으나, 정렬 상태를 유지하려면 복잡할 수 있다. 따라서 B-트리같은 트리 데이터 구조가 사용될 수 있다.
11.3.2. 해시 테이블(Hash Table)
선형 리스트에 디렉터리 항목들이 저장되며 해시 자료구조도 함께 사용된다. 파일 이름을 해시하여 값을 얻고, 그것을 포인터로 활용하여 리스트에 접근할 수 있다. 해시 테이블의 각 항목을 하나의 값이 아닌 연결 리스트로 하여 해시 충돌(collision)을 해결할 수도 있다.
11.4. 할당 방법(Allocation Methods)
11.4.1. 연속 할당(Contiguous Allocation)
연속 할당은 각 파일이 디스크 내에서 연속적인 공간을 차지하도록 한다. 연속 할당된 파일들은 접근하기 위해서 필요한 디스크 탐색 횟수를 최소화시킬 수 있다. 각 파일을 위한 디렉터리 항목은 이 파일의 디스크 내 시작 블록 주소와 이 파일의 크기만 표시하면 된다.
연속 할당 기법에서 한 가지 어려운 점은 새로운 파일을 위한 가용 공간을 찾는 일이다. 9.3절의 동적 공간 할당 문제처럼 최초 적합과 최적 적합이 사용될 수 있다. 그러나 비슷하게 외부 단편화 문제가 생긴다.
연속 할당은 또 다른 문제점이 있다. 파일을 위해서 얼마나 많은 공간을 줄지 결정하는 것이다. 너무 작은 공간을 예약한다면 파일이 커질 수 없고, 너무 큰 공간을 예약한다면 많은 공간이 내부 단편화로 낭비된다.
따라서 많은 운영체제는 어느 정도의 연속된 공간만 초기에 할당하고, 추후 n개의 연속된 공간을 단위(extent라고 부르는)로 할당한다. 파일 블록들의 위치는 위치와 블록 수, 그리고 다음 extent의 첫 블록에 대한 포인터로 기록된다.
11.4.2. 연결 할당(Linked Allocation)
연결 할당의 경우 파일은 디스크 블록의 연결 리스트 형태로 저장되고, 블록들은 디스크 내에 흩어져 저장될 수 있다. 각 블록은 다음 블록을 가르키는 포인터를 포함하며, 이 영역은 사용자가 사용할 수 없다. 연결 할당의 경우 외부 단편화가 없고, 파일 생성 시 생성할 파일의 크기가 미리 고정될 필요도 없다.
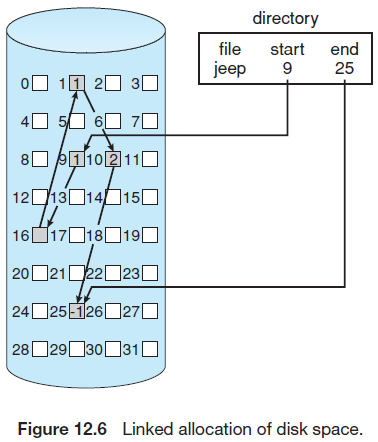
그러나 순차적 접근 파일에만 효과적으로 사용될 수 있고, 직접 접근 방식에는 매우 비효율적이다. n번째 블록을 찾으려면 첫 번째 블록에서부터 포인터를 쭉 따라가야하며, 매번 디스크를 읽어야 한다.
다른 단점은 포인터들을 위한 공간이 필요하여, 각 파일들은 더 많은 공간이 필요하다는 점이다. 일반적인 해결 방법은 여러 블록들을 하나의 클러스터(cluster)로 구성하여 클러스터 단위로 할당하는 것이다. 포인터가 차지하는 비율이 훨씬 작아지나 내부 단편화 문제는 증가한다.
또 다른 문제는 신뢰성의 문제이다. 오류나 하드웨어의 고장으로 하나의 포인터를 잃어버리거나 잘못된 포인터 값을 가지게 되면 모든 데이터를 읽게 된다.
한 가지 변형 기법은 파일 할당 테이블(File Allocation Table, FAT)을 사용하는 것이다. 각 볼륨의 시작 부분이 FAT로 사용된다.
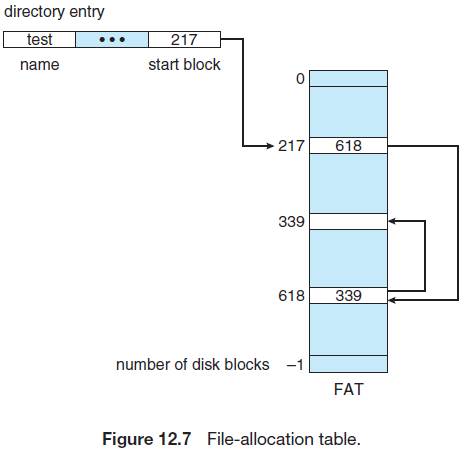
FAT는 각 디스크 블록마다 한 개의 항목을 가지고 있고, 이 항목에는 파일의 다음 블록 번호가 있다. 파일의 끝이라면 블록 번호 대신, 끝을 나타내는 특수한 값을 가지고 있다. FAT는 디스크 블록 번호로 접근된다.
디렉터리 항목은 파일의 첫 번째 블록 번호를 가지고 있다. 연결 할당과 비슷하게 탐색이 가능하다.
파일에 새로운 블록을 할당하는 일은 먼저 테이블 값이 0인 블록을(사용되지 않는 블록) 찾는다. 이후 0 이전에 파일의 끝을 표시하는 블록을 사용하고, 0인 블록을 끝을 나타내도록 한다.
FAT는 캐시되지 않으면 디스크 탐색이 오래 걸린다. 장점은 직접/무작위(random) 접근의 시간이 개선된다는 것이다. 디스크 헤드가 FAT의 정보를 읽어 임의의 블록의 위치를 알 수 있기 때문이다.
11.4.3. 색인 할당(Indexed Allocation)
각 파일들은 디스크 블록 주소를 모아놓은 배열인 색인(index) 블록을 가진다. 색인 할당은 외부 단편화 없이 직접 접근을 제공한다.
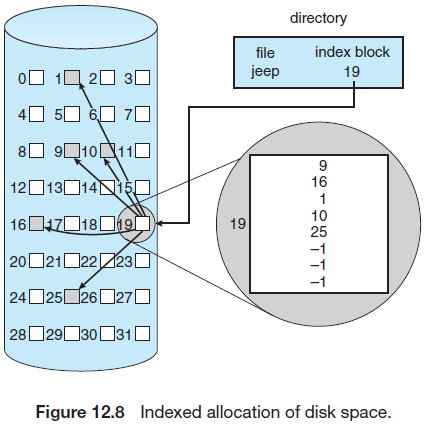
그러나 색인 블록을 위해 공간이 사용된다. 이를 해결하기 위한 색인 블록 크기에 대한 기법들은 다음과 같다.
- 연결 기법(linked scheme): 파일의 크기가 크면 여러 개의 색인 블록들을 연결시킨다.
- 다중 수준 색인(multilevel index): 여러 개의 두 번째 수준 색인 블록들의 집합을 가리키기 위하여 첫 번째 수준의 색인 블록을 사용한다. 한 블록에 1,024개의 포인터가 들어간다면, 1,024*1,024개의 데이터 블록을 가르킬 수 있다. 파일 크기가 더 크다면 여러 수준의 블록을 사용한다.
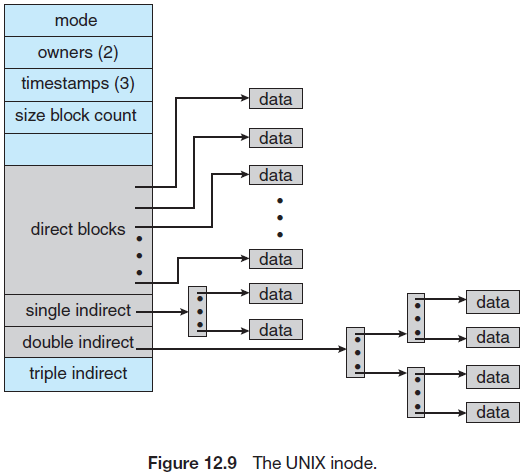
- 결합 기법(combined scheme): UNIX 기반 파일 시스템에서 사용되는 대안은 파일의 inode에 색인 블록 15개 포인터를 유지하는 것이다. 처음 12개의 포인터는 직접 블록(direct block)을 가르킨다. 즉, 데이터가 있는 블록을 직접 가르킨다. 그 다음 3개의 포인터는 간접 블록(indirect block)을 가르킨다. 즉, 데이터가 있는 블록의 주소를 가진 블록을 가르킨다. 다중 수중 색인처럼 단일 간접, 이중 간접, 삼중 간접 3개의 포인터가 있다.
11.4.4. 성능
시스템들이 어떤 목적을 위해 사용되느냐가 할당 방법 선택에 중요하다. 몇몇 시스템들은 연속, 연결 할당을 둘다 사용한다. 일부 시스템은 연속과 색인 할당을 결합하여, 작은 파일은 연속 할당하고 더 커지면 색인 할당으로 전환한다.
11.5. 자유 공간의 관리(Free-Spacee Management)
11.5.1. 비트 벡터(Bit Vector)
자유 공간 리스트는 흔히 비트 맵(bit map) 또는 비트 벡터(bit vector)로서 구현된다. 각 블록은 1비트로 표현되고, 블록이 자유로우면 1, 아니면 0이 된다. (ex, 01101001…)
자유 블록을 찾는 일이 간편하고 효율적이지만, 디스크 크기가 클 경우 비트 벡터가 메모리에 올라가기엔 너무 커질 수 있다.
11.5.2. 연결 리스트(Linked List)
모든 자유 디스크 블록을 연결시킨다. 자유 블록은 다음 자유 블록을 가르키는 포인터를 가지고 있다. 하지만 자유 블록 리스트 순회는 효율적이지 못하다.
11.5.3. 그룹핑(Grouping)
연결 리스트의 변형으로, 첫 자유 블록에 n개의 자유 블록 주소를 저장하는 방법이다. 처음 n-1개는 비어있는 블록이고, 마지막 블록은 다시 다른 n개의 자유 블록 주소를 가지고 있다. 다수 개의 자유 블록 주소를 쉽게 찾을 수 있다.
11.5.4. 계수(Counting)
일반적으로 디스크 공간의 할당과 반환이 여러 연속된 블록 단위로 이루어진다는 이점을 이용하는 것으로, 특히 연속 할당 알고리즘이나 클러스터링을 통해 공간을 할당할 경우 유용하다.
모든 블록을 추적할 필요 없이 연속된 자유 블록의 첫 번째 블록의 주소와 연속된 블록의 개수만 유지한다.
11.5.5. 공간맵(Space Maps)
Oracle의 ZFS 파일 시스템은 대규모의 파일, 디렉터리, 파일 시스템을 저장할 수 있다. 이러한 규모에서는 메타데이터의 입출력이 성능에 영향을 미친다. 예를 들어 수천 개의 비트 맵을 갱신할 수도 있다.
따라서 ZFS는 장치의 공간을 관리 가능한 크기의 덩어리로 나누기 위해 메타슬랩(metaslabs)을 생성한다. 각 메타슬랩은 연관된 공간맵을 가진다.
ZFS는 계수 알고리즘을 사용하는데, 디스크에 계수 구조를 기록하는 것이 아니라 로그-구조 파일 시스템 기법을 사용하여 이 정보를 저장한다. 공간맵은 할당과 반환같은 모든 블록 활동을 계수 형식으로, 시간 순서로 기록한다.
ZFS가 메타슬랩으로부터 공간을 할당받거나 반환할 때, 관련된 공간맵을 변위에 따라 색인된(indexed by offset) 균형-트리 구조로 메모리에 적재하고, 로그를 재실행하여 이 구조에 반영한다.
또한 ZFS는 연속된 자유 블록을 결합하여 하나의 항으로 만들어 공간 맵을 압축한다. 마지막으로 ZFS의 트랜잭션 기반 연산의 일부분으로 디스크에 존재하는 자유 공간 리스트가 갱신된다.
11.6. 효율과 성능
11.6.1. 효율
UNIX 에서 빈 디스크라 해도 inode를 미리 할당하거나, 파일 크기가 증가함에 따라 클러스터의 크기를 변화 시킬 수 있다. 효율을 위해 많은 부분이 고려되어 왔다. 하드 디스크가 커져가고, 32비트에서 64비트로 넘어감에 따라 파일 속성, 포인터 크기, 커널 구조 등이 변해왔다.
11.6.2. 성능
시스템 성능을 향상시킬 수 있는 방법들이 몇 가지 더 있다. 13장에 나올 디스크 컨트롤러는 전체 트랙의 내용을 전부 저장할 수 있는 캐시(on-board cache)를 가지고 있다. 탐색(seek)이 수행되면, 디스크 헤드 아래 있는 섹터부터 시작하여, 트랙이 디스크 캐시로 읽혀진다. 그 후 디스크 컨트롤러가 운영체제가 요구하는 섹터를 전송한다.
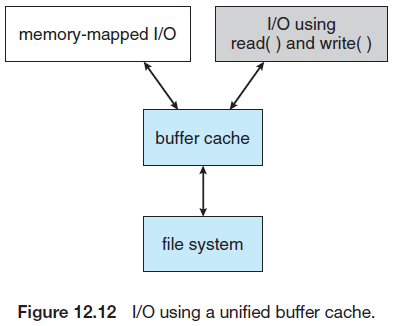
어떤 시스템은 주 메모리에 별도의 구역을, 곧 다시 사용될 블록을 가진 버퍼 캐시용으로 유지한다.
다른 시스템은 파일 데이터를 페이지 캐시를 사용하여 캐시한다. 페이지 캐시는 가상 메모리 기법을 사용하여 파일 데이터를 파일-시스템-지향 블록이 아닌 페이지로 캐시한다. 가상 주소로 파일을 캐싱하는 것은 물리 디스크 블록으로 캐시하는 것보다 효율적인데, 이는 접근을 파일 시스템이 아닌 가상 메모리로 하기 때문이다.
파일 시스템을 접근할 때, 가상 메모리 시스템은 버퍼 캐시와 인터페이스할 수 없기 때문에, 버퍼 캐시에 있는 파일이 페이지 캐시에 복사되어야만 한다. 즉, 파일 시스템 데이터를 두 번 캐싱해야 한다. 이를 해결하기 위해 버퍼 캐시와 페이지 캐시는 통합되었다.
입출력의 성능에 영향을 줄 수 있는 문제는 파일 시스템에 쓰기 연산이 동기적인지 비동기적인지 이다. 대부분의 경우 데이터를 캐시에 저장하고 호출자에게 제어를 돌려주는 비동기식 쓰기가 행해진다. 그러나 메타데이터 쓰기 작업은 통상 동기적으로 수행된다.
어떤 시스템은 파일의 접근 타입에 따라 다른 교체 알고리즘을 사용함으로써 페이지 캐시를 최적화한다. 예를 들어, 순차적으로 읽혀지고 쓰여지는 파일은 LRU가 아닌 free-behind, read-ahead 기술이 사용된다. Free-behind는 다음 페이지가 요청되자마자 버퍼에서 페이지를 제거하는 것이다. Read-ahead는 요구된 페이지와 몇 개의 뒤이은 페이지를 읽어 캐싱하는 것이다.
데이터 쓰기는 다음과 같이 개선될 수 있다. 데이터가 디스크 파일에 쓰여질 때, 페이지는 캐시에 버퍼되고, 디스크 드라이버는 자신의 출력 큐를 디스크 주소에 따라 정렬한다. 이 행동은 디스크 드라이버에게 디스크 헤드 탐색을 최소화하고, 디스크 회전에 최적화된 시간에 데이터 쓰기를 허용한다.
11.7. 복구
11.7.1. 일관성 검사(Consistency Checking)
파일 시스템은 파일 시스템 메타데이터안에 자신의 상태를 기록할 수 있다. 메타데이터를 변경중이면, 이 상태 비트는 1로 세트된다. 변경이 성공적으로 완료 됬으면 상태 비트를 0으로 클리어한다. 하지만, 상태 비트가 1로 남아있으면 일관성 검사기(consistency checker)가 실행된다.
UNXI의 fsck와 같은 일관성 검사기는 디렉터리 구조에 있는 데이터와 디스크에 있는 데이터를 비교하고, 불일치가 발견되면 그것을 복구하려고 시도한다.
11.7.2. 로그-구조 파일 시스템(Log-Structured File System)
로깅 알고리즘은 일관성 검사 문제에 성공적으로 적용되었다. 그 구현은 로그-기반 트랜잭션-지향(또는 journaling) 파일 시스템으로 알려져 있다.
기본적으로 모든 메타데이터 변경은 로그에 순차적으로 기록된다. 특정 태스크를 수행하는 연산의 집합 각각을 하나의 트랜잭션이라고 한다.
변경이 로그에 기록되면 그것들은 commit 된 것으로 간주되고, 시스템 콜은 사용자 프로세스로 복귀하여 실행을 계속한다. 그동안 이 로그 엔트리는 실제 파일 시스템 구조에 대해 재실행된다.
변경이 반영되는 동안, 어느 연산이 끝났는지 그리고 어느 것이 덜 끝났는지를 나타내기 위한 포인터가 갱신된다. commit 된 전체 트랜잭션이 완료되면, 이 로그는 원형 버퍼로 구성된 로그 파일에서 제거된다.
시스템이 고장났을 때, 로그 파일은 0개 이상의 트랜잭션을 가지고 있을 것이다. 이들은 파일 시스템에 수행되지 않았으므로 반드시 재수행 되어야한다.
유일한 문제는 트랜잭션이 중간에 중단되어, commit 이 되지 않은 상태로 시스템이 고장났을 때 생긴다. 이런 트랜잭션에 의해 변경된 파일 시스템은 원상태로 돌려져야한다. 이때 일관성 검사가 사용된다.
11.7.3. 다른 해결 방안들
트랜잭션은 모든 데이터와 메타데이터 변경을 새로운 블록에 기록한다. 트랜잭션이 완료되면, 옛날 버전의 블록을 가르키고 있는 메타데이터 구조는 새로운 블록을 가르킨다.
이후에 파일 시스템은 옛날 포인터와 블록을 삭제한다. 만약 옛날 포인터와 블록은 유지한다면 스냅샷을 생성하는 것이 되고, 이 스냅샷은 마지막 갱신이 일어나기 전의 파일 시스템 상태이다.
11.7.4. 백업과 복구
디스크 고장에 대비해 다른 저장 장치에 주기적으로 백업해야 한다.
11.8. NFS
NFS는 LAN(또는 WLAN)을 거쳐 원격 파일을 접근하기 위한 소프트웨어 시스템의 구현과 명세 모두를 말한다. NFS에는 다수의 버전이 존재하며, 여기서는 버전 3을 설명한다.
11.8.1. 개요
NFS는 서로 연결된 워크스테이션의 집합을 독립적인 파일 시스템을 가진 독립적인 기계들의 집합으로 간주한다. NFS의 목적은 이들 파일 시스템 사이에서 일정 수준의 공유를 투명하게 허용하는 것이다. 투명하게 접근한다는 것은 객체가 로컬에 있든, 외부에 있든 상관없이 같은 연산을 통해 접근할 수 있다는 것이다.
원격 디렉터리가 특정 시스템(M1)에 투명하게 접근 가능하도록 하기 위해서 M1의 클라이언트는 먼저 마운트 명령을 수행한다. 이 명령은 원격 디렉터리가 로컬 파일 시스템의 디렉터리상에 마운트되게 한다. 마운트된 디렉터리는 로컬 파일 시스템의 하부트리처럼 보인다.
NFS의 설계 목표 중의 하나는 서로 다른 기계들, 운영체제, 그리고 네트워크 구조로 구성된 이질적 환경에서 작동되는 것이다. NFS 명세는 이들 매체에 독립적이기 때문에 다른 구현들을 이용 가능하게 한다. 이러한 독립성은 두 개의 구현 독립적 인터페이스간에서 사용되는 외부 자료 표현(External Data Representation, XDR) 프로토콜 위에 구축된 RPC 기본요소를 통해서 이루어진다.
NFS 명세는 마운트 기법에 의해 제공 되는 서비스와 실제 원격 파일 접근 서비스를 구분한다. 마운트 프로토콜과 NFS 프로토콜이라 불리는 원격 파일 접근을 위한 프로토콜이 이들 서비스들을 위해 명세되어있다.
11.8.2. 마운트 프로토콜(The Mount Protocol)
마운트 프로토콜은 서비스와 클라이언트 사이의 초기 논리적 연결을 생성하기 위해서 사용된다.
마운트 요구는 적절한 RPC로 매핑되고, 지정된 서버 기계에서 수행되는 마운트 서버로 전달된다. 서버는 수출 리스트(export list)를 유지한다. 이 리스트는 마운트될 수 있는 로컬 파일 시스템과 마운트할 수 있게 허용된 기계의 이름도 저장한다.
서버가 마운트 요구를 받았을 때, 클라이언트에게 마운트된 파일 시스템 안의 파일에 대한 접근 키(key)로 사용할 파일 핸들을 반환한다. 이 파일 핸들은 서버가 저장하고 있는 파일을 구분하기 위해서 필요한 모든 정보를 가지고 있다.
마운트 프로토콜은 마운트 프로시저 외에 언마운트와 수출 리스트 반환과 같은 여러 프로시저를 가지고 있다.
11.8.3. NFS 프로토콜(The NFS Protocol)
NFS 프로토콜은 원격 파일 연산을 위한 원격 프로시저 호출의 집합을 제공한다. 이러한 프로시저는 원격으로 마운트된 디렉터리에 대한 파일 핸들이 구축되어야만 호출할 수 있다.
- 디렉터리 내의 파일 검색
- 디렉터리 항목 읽기
- 링크와 디렉터리들의 조작
- 파일 속성의 접근
- 파일 읽기와 쓰기
NFS 서비스의 주요 특징은 무상태성(stateless)이다. 서버는 하나의 접근과 다른 접근 사이에 클라이언트에 대한 정보를 유지하지 않는다. 결론적으로 각각의 요청들은, 연산을 위해 유일한 파일 식별자와 파일 내부의 절대적 변위(offset)를 포함한 매개변수 집합을 제공해야 한다.
NFS 요청은 견고성을 위해, 같은 연산을 여러 번 적용하더라도 오직 한 번만 적용한 결과와 같아야 한다. 이를 위해 각 NFS 요청은 일련번호를 가지고 있어 서버가 요청이 중복되었는지 또는 빠졌는지를 결정할 수 있게 한다.
서버의 무상태 철학과 RPC의 동기성이 갖는 부가적인 의미는, 결과들이 클라이언트에게 반환되기 전에 변경된 자료가 서버의 디스크에 기록되어야 한다는 점이다. 즉, 서버는 모든 NFS 데이터를 동기적으로 써야만 한다. 이는, 캐싱을 활용할 수 없기에 성능에 큰 문제가 발생한다. 따라서 NFS에 의해 쓰여지는 블록들을 저장하는 빠르고 비휘발성인 캐시(대개 예비 배터리를 내장한 메모리)를 갖는 저장 장치를 사용하여 해결한다. 이런 블록들은 주기적으로 디스크로 기록된다.
하나의 NFS 쓰기 프로시저 호출은 원자성(atomic)이 보장되며, 같은 파일에 대한 다른 쓰기 호출과 혼합되지 않는다. 그러나 NFS 프로토콜은 병행성 제어 기법(concurrency control mechanism)을 제공하지 않는다. 쓰기 시스템 호출은 여러 개의 RPC 쓰기로 분리될 수 있는데, NFS 쓰기 또는 읽기 호출이 최대 8KB의 자료를 포함할 수 있고, UDP 패킷은 1,500바이트로 제한되어 있기 때문이다. 결과적으로 같은 원격 파일에 대해 쓰기를 하는 두 사용자는 그들의 데이터가 섞일수도 있다. 이러한 문제는 NFS 외부의 서비스가 록(lock)을 제공해야만 해결될 수 있다고 주장되고 있다.
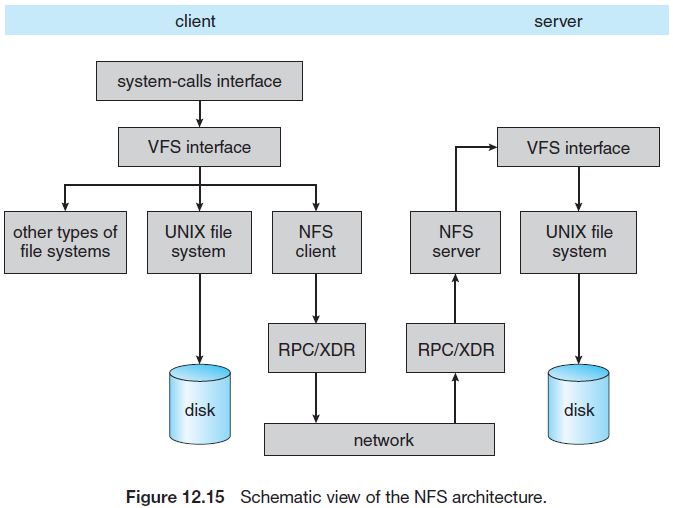
NFS는 가상 파일 시스템(VFS)을 통하여 운영체제로 통합된다.
- 클라이언트가 시스템 호출을 하면, 운영체제 층은 이 호출을 적절한 vnode에 대한 VFS 연산으로 매핑한다.
- VFS 계층은 파일을 원격 파일로 인식하고 NFS 프로시저를 실행한다.
- RPC 호출이 원격 서버의 NFS 서비스 계층에 대해 행해진다.
- 이 호출이 원격 서버의 VFS 계층으로 들어가, 그 호출이 로컬임을 발견하고 파일 시스템 연산을 수행한다.
- 이 경로를 다시 되돌아가서 결과를 반환한다.
이러한 구조의 장점은 시스템이 클라이언트나 서버 모두가 될 수 있다는 것이다.
11.8.4. 경로 이름 변환
NFS의 경로 이름 변환은 경로 이름을 분리하는 것을 포함한다. /usr/local/dir1/file.txt 는 별개의 디렉터리 항목/요소인 usr, local, dir1 가 된다. 경로 이름 변환은 경로를 구성 요소 이름(component name)으로 분리하고, 구성 요소 이름과 디렉터리 vnode의 모든 쌍에 대해 별도의 NFS 룩업(lookup) 호출을 실행함으로써 이루어진다.
마운트 포인트를 넘어가면, 모든 구성 요소 룩업은 서버에 대해 별도의 RPC를 유발한다.
이렇게 비용이 많이 소요되는 경로 이름 순회 기법이 필요한 이유는,
클라이언트가 수행한 마운트에 의해 형성된, 각 클라이언트의 논리 이름 공간 구조가 고유하기 때문이다.
룩업을 빠르게 하기 위해서, 클라이언트의 디렉터리 이름 룩업 캐시는 원격 디렉터리 이름들에 대한 vnode를 갖고 있다. 이 캐시는 시작 부분이 같은 경로 이름을 가진 파일에 대한 참조 속도를 증가시키며, 서버로부터 반환된 속성들이 캐시된 vnode의 속성들과 다를 때 버려진다.
11.8.5. 원격 연산(Remote Operations)
파일 연산을 위한 UNIX 시스템 호출들과 NFS의 RPC 프로토콜 간에는 거의 1:1 대응 관계가 있다. 그러므로 원격 파일 연산은 대응되는 RPC로 직접 변환될 수 있다.
하지만 성능 향상을 위해 직접적인 대응 관계 대신, 버퍼링과 캐싱 기술을 사용한다. 파일 블록들과 파일 속성들이 RPC에 의해서 불려져 로컬하게 캐시된다. 그 후 원격 연산들은 일관성 제한이 허락하는 한, 캐시 자료를 사용한다.
파일 블록 캐시와 파일 속성(inode 정보)캐시가 있다. 파일을 열 때, 커널은 캐시된 속성들을 가져올 지, 재검증할 지 결정한다. 캐시된 파일 블록들은 대응되는 캐시된 속성들이 최신 버전일 경우에만 사용한다. 서버로부터 새로운 속성들이 올 때마다 캐시된 속성이 갱신된다. 캐시된 속성들은 기본적으로 60초 후 버려진다.
미리 읽기(read-ahead)와 지연 쓰기(delayed write)기법들 모두가 서버와 클라이언트간에서 사용된다. 미리 읽기를 사용하면 NFS 클라이언트 어플리케이션이 요청할 데이터를 예상하여 NFS 서버에서 클라이언트로 데이터를 전송할 수 있다. 지연 쓰기에서 클라이언트는 서버가 자료를 디스크에 기록하기 전까지는 지연 쓰기 블록을 자유화 하지 않는다. 또한 파일이 충돌 모드로 병렬 오픈될 때도 사용된다.
성능을 위한 시스템의 조정은 NFS에서 일관성 의미를 규정하기 어렵게 만든다. 한 기계에서 생성된 새로운 파일은 다른 기계에서는 30초동안 볼 수가 없다. 한쪽에서 쓴 내용이 그 파일을 읽고 있는 다른 쪽에 보여야 하는지의 여부도 모호하다.
9. 예: WAFL(Write-Anywhere File Layout) 파일 시스템
WAFL 파일 시스템은 특정한 시스템을 위하여 최적화된 파일 시스템의 하나이다. 블록 기반이며, 파일을 기술하기 위해 inode를 사용한다. 각 inode는 블록을 가르키는 포인터를 갖는다. 각 파일 시스템은 root inode를 갖고, 모든 메타 데이터는 파일에 존재한다.
업데이트 및 쓰기 연산을 위해 스냅샷을 사용한다.
댓글남기기