운영체제 요약 - 10. 파일 시스템
10.1. 파일 개념(File Concept)
운영체제는 컴퓨터 시스템을 편리하게 사용하기 위해 저장된 정보에 대한 일관된 논리적 관점을 제공하고 저장 장치의 물리적 특성을 추상화하여 논리적 저장 단위, 즉 파일을 정의한다. 파일은 물리 장치들로 사상되며 저장 장치에서 영구히 저장된다.
파일은 보조 저장 장치에 기록된 관련 정보의 집합으로 정의할 수 있다. 사용자의 관점에서 볼 때 파일은 논리적 보조 저장 장치의 가장 작은 할당 요소이다. 즉 자료가 파일 안에 존재해야만 보조 저장 장치에 기록될 수 있다.
10.1.1. 파일 속성(File Attributes)
파일은 운영체제마다 다른 속성을 갖지만 보통 다음과 같은 속성들을 가진다.
- 이름: 파일의 이름은 사람이 읽을 수 있는 형태로 유지된 유일한 정보이다.
- 식별자(Identifier): 통상 하나의 숫자로 파일 시스템 내에서 파일을 확인한다.
- 타입: 여러 유형을 제공하는 시스템을 위해 필요하다.
- 위치: 파일이 존재하는 위치와 그 장치 내의 위치에 대한 포인터이다.
- 크기: 파일의 현재 크기(바이트, 워드 혹은 블록)와 최대 허용 크기가 포함된다.
- 보호: 접근 제어 정보는 누가 읽기, 쓰기, 실행 등을 할 수 있는가를 제어한다.
- 시간, 날짜, 사용자 식별: 생성, 최근 변경, 최근 사용 등을 유지하고 보호, 보안 및 사용자 감시를 위해 사용된다.
몇몇 파일 시스템들은 문자 인코딩 정보와 파일 체크섬과 같은 보안 정보를 포함하여 확장된 파일 속성(extended file attributes)도 지원한다.
모든 파일에 대한 정보는 보조 저장 장치에 상주하는 디렉터리 구조에 의해서 유지된다. 디렉터리 항목은 파일의 이름과 고유의 식별자로 구성된다.
10.1.2. 파일 연산(File Operations)
파일은 추상적인 데이터 유형이다. 파일을 정의하기 위해 파일에 대한 연산을 고려해야 한다.
운영체제는 파일에 대한 시스템 호출들을 제공한다.
- 파일 생성: 파일 시스템 내에 공간을 찾고 새로 생성된 파일에 대한 항목을 디렉터리에 만듦
- 파일 쓰기: 파일명과 파일에 기록할 정보를 가지고 시스템 호출을 실행. 시스템은 파일 내의 다음 쓰기가 일어날 위치를 가르키는 쓰기 포인터(write pointer)를 유지하고 갱신.
- 파일 읽기: 파일을 찾기 위해 디렉터리를 탐색하고, 다음 읽기가 일어날 파일 안의 위치를 가르키는 읽기 포인터(read pointer)를 유지하고 갱신. 대부분의 시스템은 하나의 현재 파일 위치 포인터(current file position pointer)를 가짐. 읽기와 쓰기 연산 모두 이 포인터를 사용함으로써 공간을 절약하고 시스템의 복잡성을 감소시킴.
- 파일 안에서의 위치 재설정: 디렉터리에서 적합한 항목을 탐색하고 현재 파일 위치을 주어진 값으로 설정한다. 재설정을 위해 입출력을 할 필요는 없으며 이 파일 연산은 탐색(seek)으로도 알려져 있다.
- 파일 삭제: 디렉터리에서 파일을 찾고, 해당 파일이 차지한 모든 공간을 방출하고 디렉터리 항목을 삭제한다.
- 파일 절단: 파일의 내용을 지우지만 파일의 속성은 남긴다. 파일의 길이가 0으로 재설정되며 파일이 가지고 있던 공간은 해제된다.
대부분의 파일 연산들은 파일과 관련된 디렉터리를 찾는 작업을 한다. 반복적인 탐색을 피하기 위해서 많은 시스템들은 파일이 맨 처음 사용될 때 open() 시스템 호출을 요구한다.
운영체제는 모든 열린 파일에 대한 정보를 갖는 열린 파일 테이블(open-file table)을 유지한다. 파일 연산이 요구되면, 이 테이블에 대한 인덱스로 그 파일을 지정하므로 어떠한 탐색도 필요하지 않다. 파일이 더 이상 사용되지 않으면 운영체제는 열린 파일 테이블에서 항목을 제거한다.
보통 운영체제는 두 단계 내부 테이블, 즉 프로세스별 테이블과 범 시스템 테이블을 사용한다. 프로세스별 테이블은 각 프로세스가 연 모든 파일들을 기록한다.
프로세스별 테이블에 저장된 내용은 프로세스가 파일을 어떻게 사용하는가에 관한 정보이다. 예를 들어, 각 파일에 대한 현재 파일 포인터, 접근 권리, 회계 정보 등이 포함되어 있다.
프로세스별 테이블의 각 항목(entry)은 다시 범 시스템 열린 파일 테이블들을 가리킨다. 이 범 시스템 테이블은 디스크 상의 파일 위치, 접근 날짜, 파일 크기와 같은 정보들을 갖고 있다.
일단 파일이 하나의 프로세스에 의해 열리면, open() 호출을 하는 다른 프로세스는 단순히 범 시스템 테이블들 내에 있는 항목을 가르키는 새로운 항목을 프로세스의 열린 파일 테이블에 추가한다.
열린 파일과 관련된 몇 가지 정보들은 다음과 같다.
- 파일 포인터: 현재 파일 위치 포인터로서 가장 최근의 읽기/쓰기 위치를 추적한다. 파일 연산을 수행하는 각 프로세스에 대해 유일하게 하나씩 만들어지므로 디스크 상의 파일 속성들과는 분리되어 유지되어야 한다.
- 파일 열린 계수: 이 계수는 파일의 총 open/close의 수를 추적하며, 값이 0에 도달하면 열린 파일 테이블에서 파일 항목을 제거한다.
- 파일의 디스크 위치: 매 연산마다 디스크에서 읽는 것을 피하기 위해 메모리에 저장된다.
- 접근 권한: 각 프로세스는 한 파일을 하나의 접근 모드로 연다. 이 정보는 프로세스별 테이블에 저장된다. 운영체제는 이 정보를 후속 요구를 허용하거나 불허하는 데 사용할 수 있다.
몇몇 운영체제는 열려진 파일을 잠금(locking)할 수 있는 기능을 제공한다. 파일 잠금은 한 프로세스가 파일을 잠그고 다른 프로세스들이 접근하는 것을 막는데 사용될 수 있다. 여러 프로세스가 동시에 잠금을 획득하는 공유 잠금(shared lock)과 한 프로세스만 잠금을 획득하는 배타적인 잠금(exclusive lock)이 있다.
운영체제는 강제적(mandatory) 또는 권고적(advisory) 파일 잠금 방법을 제공할 수도 있다. 만약 잠금이 강제적이라면, 한 프로세스가 배타적 잠금을 획득 시 다른 프로세스의 접근을 막을 것이다. 잠금이 권고적이라면, 잠금이 획득되고 해제되는 것에 대한 보장은 소프트웨어 개발자의 몫이다.
10.1.3. 파일 유형(File Types)
파일 이름이 마침표로 구분되는 이름과 확장자(extension) 두 부분으로 나뉘게 된다. .exe, .sh, .docx 등 다양한 파일 유형이 있다.
10.1.4. 파일 구조(File Structure)
각각의 파일들은 그 파일을 다루는 프로그램에 의해 인식 가능한 내부 구조를 일정한 현태로 가지게 된다. 어떤 파일들의 경우에는 운영체제가 인식할 수 있도록 미리 정해진 구조를 따라야 할 때도 있다. 예를 들어, 수행 파일이 메모리 상의 어느 위치에 적재되며 초기에 수행 가능한 명령어의 위치를 파악할 수 있도록 특별한 구조를 요구한다.
운영체제가 여러 파일 구조를 지원하는 경우에 발생 가능한 단점 중의 하나는 운영체제의 크기가 증가한다는 점이다. 파일 구조를 지원하기 위한 코드가 필요하며, 모든 파일은 운영체제에서 지원하는 파일 유형 중 하나로만 정의되어야 한다.
따라서 어떤 운영체제들은 파일 형태, 구조에 대하여 제한을 거의 두지 않는다. 이에 따라 각 응용 프로그램들이 각자의 프로그램에서 사용되는 파일들에 대한 해석과 운용을 책임져야 한다. 그렇다 하더라도 모든 운영체제는 반드시 한 가지 파일 구조는 지원해야 한다. 바로 프로그램을 로딩하고 수행할 수 있는 수행 파일의 구조이다.
10.1.5. 파일의 내부 구조(Internal File Structure)
내부적으로 한 파일 내의 어떤 위치를 찾는 것은 운영체제에게 복잡할 수 있다. 디스크 시스템은 섹터 크기에 의해 결정되는 블록 크기를 가진다.
디스크 입출력은 한 블록 단위(물리 레코드)로 수행되며, 모든 블록들은 동일한 크기를 가진다. 논리 레코드의 길이는 다양하며, 물리 레코드와 논리 레코드의 길이가 일치하지 않을 수 있다. 따라서 여러 논리 레코드들을 하나의 물리 레코드에 팩킹(packing)하는 것이 한 해결책이다.
파일은 일련의 블록으로 간주된다. 모든 입출력은 블록 단위로 수행된다. 논리 레코드로부터 물리 레코드로의 변환은 소프트웨어 문제이다.
디스크 공간이 항상 블록 단위로 할당되기 때문에 각 파일의 마지막 블록의 일부는 낭비된다. 한 블록이 512바이트이고 파일 크기가 1949바이트 일 경우 4블록(2048바이트)이 할당되고 마지막 99바이트는 낭비된다. 이를 내부 단편화라고 한다.
10.2. 접근 방법(Access Methods)
파일은 정보를 저장한다. 파일이 사용될 때는 이 정보가 반드시 접근되어 메모리로 읽혀져야 한다.
10.2.1. 순차 접근(Sequential Access)
파일을 저장되어 있는 레코드 순서로 접근한다. 편집기나 컴파일러는 보통 이러한 형식으로 파일을 접근한다.
10.2.2. 직접 접근(Direct Access or Relative Access)
파일은 고정 길이의 논리 레코드의 집합으로 정의되고, 프로그램은 특정 순서없이 바로 레코드에 직접 접근할 수 있다.
직접 접근에서 파일은 번호를 갖는 일련의 블록 또는 레코드로 간주된다. 블록 14을 읽고, 블록 53을 읽고, 그리고는 블록 7을 기록할 수 있다.
사용자가 사용하는 블록 번호 n은 통상 파일의 시작을 0으로 보고 계산한 레코드 위치로써 상대 블록 번호(relative block number)이다. 따라서 블록의 실제 절대적인 디스크 주소가 첫 번째 블록 14703, 두 번째 3192일지라도, 파일의 첫 번째 상대 블록은 0이고 다음은 1의 순서이다.
10.2.3. 기타 접근 방법
색인(index)를 사용하는 방법이 있다. 색인이란 여러 부분에 대한 포인터를 제공하는 것이다.
찾고자 하는 레코드가 있으면 먼저 색인부터 찾아 그에 대응하는 포인터를 얻는다. 그런 다음 포인트를 사용하여 파일을 직접 접근하고 원하는 레코드를 찾는다.
예를 들어 판매 가격 파일이 상품 코드를 가질 수 있다. 파일들을 상품 코드로 정렬해 두면, 상품 코드로 구성된 인덱스를 정의할 수 있다.
인덱스는 파일 전체가 아닌 상품 코드만 저장함으로써 메모리에 올라갈 정도로 적은 용량이 될 수 있다. 게다가 정렬이 되어있기에 이진 탐색으로 빠르게 인덱스 탐색이 가능하다.
파일이 아주 크면 색인도 매우 커 메모리에 들어가지 못할 수가 있다. 색인 파일에 대해서도, 메모리에 올라갈 정도가 될 때까지, 색인을 만들어 2차 색인을 만들 수 있다.
10.3. 디렉터리와 디스크 구조
저장 장치는 전체를 하나의 파일 시스템으로 사용할 수도, 정교한 제어를 위해 세분될 수도 있다. 예를 들어 디스크는 쿼터 단위로 분할되고, 각 쿼터가 하나의 파일 시스템을 포함할 수 있다.
파티션은 개별 파일 시스템의 크기를 제한하거나, 하나의 디스크에 여러 파일 시스템을 사용하거나, 파일 시스템으로 일부분을 사용하고 나머지 부분은 스왑 공간이나 포맷되지 않은(raw) 디스크 공간 같은 것들로 사용할 때 유용하다.
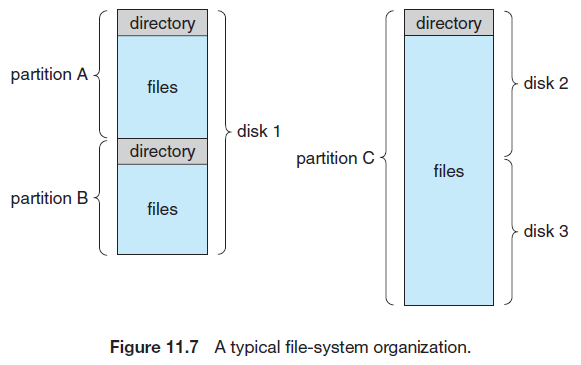
파일 시스템을 포함하고 있는 임의의 개체는 볼륨(volume)이라고 불린다. 볼륨은 장치의 부분 집합, 전체 장치, 또는 RAID 집합으로 연결된 다수의 장치일 수 있다.
각 볼륨은 시스템에 존재하는 파일에 대한 정보를 가지고 있어야 한다. 이는 디바이스 디렉터리(device directory, 간단히 디렉터리) 또는 컨텐츠 볼륨 테이블(volume table of contents)의 항목들에 저장된다.
10.3.1. 저장 장치의 구조
컴퓨터 시스템은 파일 시스템이 없을 수도 있으며 다양한 종류의 파일 시스템을 가질 수 있다. Solaris는 tmpfs, ufs 등 다양한 파일 시스템 유형을 가지고 있다.
10.3.2. 디렉터리 개관(Directory Overview)
디렉터리는 파일 이름을 그 위치로 바꾸어 주는 심볼 테이블(symbol table)로 볼 수 있다.
각 디렉터리에 수행될 수 있는 연산들은 다음과 같다.
- 파일 찾기: 파일 이름들은 식별될 수 있는 문자열이다. 특정 패턴과 일치하는 이름을 갖는 모든 파일을 찾을 수 있다.
- 파일 생성: 파일을 생성하여 디렉터리에 추가한다.
- 디렉터리 나열: 디렉터리에 존재하는 파일들을 나열하고, 파일에 대한 디렉터리 항목의 내용을 보여준다.
- 파일의 재명명: 파일 이름을 변경한다. 이름이 바뀌면서 디렉터리 구조 내에서 파일의 위치가 변경될 수도 있다.
- 파일 시스템의 순회(traverse): 모든 디렉터리와 파일에 접근한다.
10.3.3. 1단계 디렉터리
모든 파일이 한 개의 디렉터리 밑에 있다. 다수의 사용자가 사용한다면 각 파일들은 유일한 이름을 가져야 한다.
3.4. 2단계 디렉터리
각 사용자들에게 서로 다른 디렉터리를 만들어 준다. 각 사용자는 자신만의 UFD 디렉터리(UFD, User File Directory)를 가지고, 시스템은 마스터 파일 디렉터리(MFD, Master File Directory)를 가진다. MFD는 사용자 이름이나 계정 번호로 색인되어 있고, 각 항목은 사용자의 UFD를 가르키고 있다.
두 사용자가 한 파일을 공유해서 사용해야 하는 경우, 서로 자신의 UFD 접근을 허용해야 한다. 그 후 사용자 이름과 파일명을 사용해서 경로명을 써야 한다.
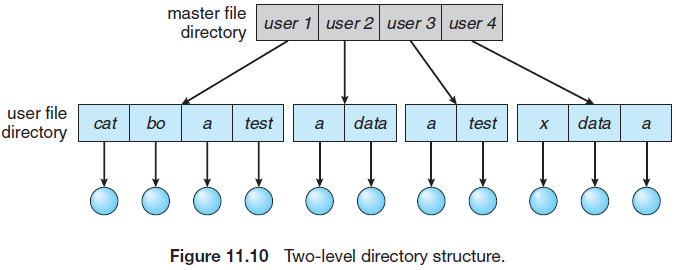
터미널에서 명령어(시스템 실행 파일 이름)를 입력하면 현재 UFD에서 검색될 것이다. 시스템 파일을 각 UFD마다 복사하는 것은 공간 낭비이므로 검색 절차를 바꾸어 해결한다.
시스템 파일을 가지는 특정 디렉터리를 정의한다. 시스템에 적재될 파일 이름이 주어질 때마다, 운영체제는 우선 현재 UFD를 검색한다. 없다면 특정 디렉터리를 검색한다.
이처럼 일정하게 디렉터리를 탐색하는 순서를 탐색 경로(search path)라고 한다. 탐색 경로는 수시로 변경할 수 있고, 각 사용자마다 자신만의 탐색 경로를 가질수도 있다.
10.3.5. 트리 구조 디렉터리
사용자들에게 자신의 서브 디렉터리를(subdirectory)를 만들 수 있게 한다. 디렉터리는 하부에 다시 디렉터리나 파일을 가질 수 있다. 디렉터리의 각 항목은 한 비트를 사용하여, 그 항목이 일반 파일(0)인지 디렉터리 파일(1)인지를 구분한다.
경로명에는 절대 경로명(absolute path name)과 상대 경로명(relative path name) 두 가지가 있다. 절대 경로명이란 루트에서부터 지정된 파일까지의 경로이다. 상대 경로명이란 현재 디렉터리를 기준으로 목적 파일까지의 경로이다.
10.3.6. 비순환 그래프 디렉터리(Acyclic-Graph Directories)
트리 구조는 파일 또는 디렉터리의 공유를 허용하지 않는다. 비순환 그래프는 디렉터리들이 서브디렉터리들과 파일들을 공유할 수 있도록 허용하는 구조로, 똑같은 파일이나 서브디렉터리가 서로 다른 서브디렉터리에 있을 수 있다.
물리적으로 한 파일을 공유함으로써 하나의 파일에 가해진 변경을 다른 사용자가 즉시 볼 수 있다. 공유되고 있는 디렉터리에 파일을 만들거나 지우면 그것이 다른 모든 공유하고 있는 서브디렉터리에 자동적으로 반영된다.
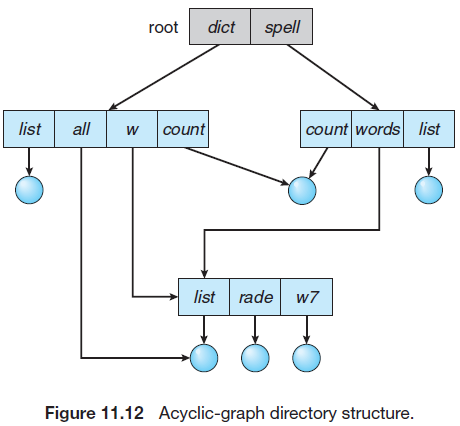
공유 파일, 디렉터리는 여러 방법으로 구현된다. 일반적인 방법(UNIX에서 사용)은 링크(link)라 불리는 새로운 디렉터리 항목을 만드는 것으로, 링크는 다른 파일이나 서브디렉터리를 가르키는 포인터이다. 실제 파일 이름은 링크 정보에 포함되어 있다.
파일에 대한 참조가 일어날 때, 디렉터리를 검색한다. 만약 디렉터리 항목이 링크로 표시되어 있다면, 링크를 해석하여 실제 파일에 대한 경로 이름을 얻어낸다.
비순환 그래프 디렉터리는 트리 구조보다는 융통적인 대신 더 복잡하다. 파일은 여러 개의 절대 경로명을 가질 수 있다. 따라서 파일을 찾고, 파일에 대한 통계를 내는 작업 등을 할 때 여러 문제가 생길 수 있다.
공유 파일을 한 사용자가 삭제 시 어떻게 처리할지도 문제이다. 운영체제 마다 해결 방법이 다르고, 하드 링크(hard link)와 심볼릭 링크(symbolic link)에 대한 차이가 있을 수 있다.
하드 링크는 디스크 위치 정보를 포함하는 이름을 여러 개 생성한다. 그렇기에 한 파일을 지워도 디스크에서 해당 위치를 찾아갈 수 있다. UNIX 운영체제는 하드링크에 대해서는 파일 정보 블록(또는 inode)에 참조 계수를 유지시킨다. 새로운 링크나 디렉터리 항목이 추가되면 참조 계수를 증가시키고, 링크나 항목이 삭제되면 계수를 감소시킨다. 계수가 0이 되면, 즉 남아있는 참조가 없을 때 파일은 삭제될 수 있다.
심볼릭 링크는 원본 파일의 이름을 가르키는 포인터이다. 따라서 원본 파일이 삭제되면 사용 불가능하다. UNIX나 Windows는 원본 파일이 삭제될 때, 심볼릭 링크를 그대로 둔다. 따라서 원본 파일이 삭제되거나 다른 파일로 바뀐 경우에 대한 책임은 사용자가 져야 한다.
10.3.7. 일반 그래프 디렉터리
기존의 트리에 새로운 링크를 추가하면, 트리 구조는 파괴되고 일반적인 그래프 구조가 될 수 있다. 디렉터리에서 순환이 허용될 경우에는, 성능적인 이유와 정확성의 이유에서 한 요소를 두 번 탐색하지 않을 것이다.
새로운 링크가 디렉터리 구조에 추가될 때, 순환 검색 알고리즘을 통해 순환이 생기지 않도록 하는 방법이 있다. 혹은 링크는 검색하지 않는 방법이 있다.
10.4. 파일 시스템 마운팅(File-System Mounting)
파일 시스템은 프로세스들에 의해 사용되기 전에 마운트 되어야 한다. 디렉터리 구조는 다양한 파티션으로 만들어 질 수 있는데, 각 파티션들이 마운트되어야 파일 시스템 네임 스페이스 안에서 이용 가능하다.
마운트 과정은 다음과 같다. 운영체제에게 디바이스 이름과 파일 시스템을 부착할 수 있는 파일 구조내의 위치(마운트 포인트)가 주어진다. 일반적으로 마운트 포인트는 마운트되는 파일 시스템이 부착될 비어 있는 디렉터리이다.
다음에 운영체제는 디바이스가 유효한 파일 시스템을 포함하는지 확인한다. 그 과정은 디바이스 드라이버가 디바이스 디렉터리를 읽고, 디럭테리가 유효한 포맷을 가지고 있는지 확인하도록 요청함으로써 이루어진다. 마지막으로 운영체제는 파일 시스템이 지정된 마운트 포인트에 마운트되었음을 디렉터리 구조에 기록한다.
10.5. 파일 공유(File Sharing)
10.5.1. 다수의 사용자
파일 공유와 보호를 구현하기 위해서, 시스템은 파일과 디렉터리에 대해 단일 사용자 시스템보다 더 많은 속성을 가져야 한다. 대부분의 시스템에서는 파일/디렉터리의 소유자(owner or user) 그룹(group) 개념을 사용한다.
소유자는 파일 속성을 변경하거나 파일 접근 허용 등 많은 제어 권한을 가지고 있다. 그룹 속성은 파일에 접근을 공유할 수 있는 사용자들을 정의한다.
주어진 파일/디렉터리의 소유자와 그룹 ID들은 다른 파일 속성과 함께 저장된다. 사용자가 파일 연산을 요구할 때, 사용자 ID와 그룹 ID를 소유자 속성과 비교한 후 시스템이 요구된 연산을 허가하든지 거부한다.
10.5.2. 원격 파일 시스템(Remote File Systems)
네트워크와 파일 기술의 발전으로 파일 공유 방법은 변화해 왔다.
- FTP같은 프로그램을 통해서 기계간 파일 직접 전송
- 로컬 기계에서 원격 디렉터리를 접근하는 분산 파일 시스템(DFS)
- WWW(World Wid Web), 파일 접근을 위해 브라우저가 필요하고, 파일 전송을 위해서는 별도의 연산(FTP를 포장한(wrapper))이 사용된다.
원격 시스템에 계정이 없어도 사용자가 파일을 전송할 수 있는 익명 접근(anonymous access), 인증형 접근이 있다.
10.5.2.1. 클라이언트 서버 모델
원격 파일 시스템은 컴퓨터가 하나 이상의 원격 시스템의 하나 이상의 파일 시스템을 마운트 하도록 허용한다. 이런 경우 파일을 가지고 있는 컴퓨터를 서버라 하고, 파일에 접근하기를 원하는 컴퓨터를 클라이언트라고 한다.
원격 파일 시스템이 마운트되면, 파일 연산 요청은 사용자를 대신하여 DFS 프로토콜을 통해 네트워크를 거쳐 서버로 보내진다. 사용자 인증 후 연산이 수행된다.
10.5.2.2. 분산 정보 시스템(Distributed Information Systems, DFS)
클라이언트-서버 서비스를 쉽게 관리하기 위해 분산 정보 시스템이라는 개념이 출현하였다. 이는 원격 컴퓨팅을 위해 필요한 정보에 단일화된 접근을 제공하기 위해 고안되었다.
마이크로소프트 네트워크(CIFS), 디렉터리 접근 프로토콜(light-weight direcctory-access protocol, LDAP) 등이 있다. 특히 하나의 분산 LDAP 디렉터리를 이용하면 한 조직 내의 모든 사용자와 모든 컴퓨터에 대한 자원 정보를 저장할 수 있다. 결과적으로 사용자가 인증 정보를 입력하여 안전하게 통합 인증(single sign-on, SSO)을 한 후에는 한 조직 내의 모든 컴퓨터에 접속할 수 있다.
10.5.2.3. 고장 모드(Failure Modes)
많은 오류로부터 복구를 구현하기 위해 상태 정보(state information)가 클라이언트/서버 모두에 유지될 수 있다. 만약 서버와 클라이언트가 현재의 활동, 열리 파일을 알고 있다면, 오류로부터 무리 없이 복구될 수 있다.
10.5.3. 일관성의 의미(Consistency Semantics)
일관성 의미는 파일 공유를 지원하는 파일 시스템을 평가하는 데 있어 중요한 요소이다. 그것은 시스템의 특성 중 하나로, 동시에 공유 파일을 접근하는 여러 사용자의 의미를 명시한다. 특별히 이러한 의미들은 한 사용자에 의한 데이터의 변경이 언제 다른 사용자에 의해 관찰될지를 명시한다.
일관성 의미는 프로세스 동기 알고리즘과 연관이 있으나, 디스크와 네트워크의 큰 지연과 느린 전송률 때문에 동기 알고리즘이 사용되지는 못한다. 유닉스, OpenAFS, 불변 공유 파일 등을 위한 의미가 있으며, 파일 열기/쓰기 등 연산에 대한 조건 및 속성을 정의한다.
10.6. 보호
10.6.1. 접근의 유형
보호 기법은 가능한 파일 접근 유형을 제한함으로써 통제된 접근을 제공한다. 접근 유형은 다음과 같다.
- 읽기
- 쓰기
- 실행
- 추가
- 삭제
- 리스트: 파일 속성, 이름 출력
10.6.2. 접근 제어(Access Control)
일반적인 방법은 사용자의 신원에 따라 특정 파일에 대한 접근 허용 여부를 결정하는 것이다. 신원에 기반한 접근을 구현하는 방법은 각 파일/디렉터리에 접근 제어 리스트(access-control list, ACL)를 연관해 두는 것이다. 이 리스트는 파일을 누가 어떤 연산을 위해 사용할 수 있는지를 기술한다.
접근 리스트의 길이를 간결하게 하기 위해서 많은 시스템은 모든 사용자들을 세 가지 부류로 분류한다.
- 소유자: 파일을 생성한 사용자가 소유자이다.
- 그룹: 파일을 공유하여 파일에 대한 유사한 접근을 필요로 하는 사용자들의 집합
- 모든 사람: 시스템에 있는 모든 다른 사용자들
이런 제한된 보호 분류에서는 보호를 정의하기 위해 단지 세 개의 필드(field)만 필요하다. 각 필드는 비트들의 집합으로 구성되고, 각 비트들은 접근을 허용하거나 금지한다. 예를 들어, UNIX 시스템은 각 3비트(rwx)인 3필드로 정의되는데, r은 읽기 접근, w는 쓰기 접근, x는 실행을 제어한다. 각 필드는 파일 소유자, 소유자의 그룹, 그리고 모든 사용를 나타낸다.
10.6.3. 다른 보호 방법
파일 혹은 디렉터리마다 암호를 사용하는 방법이 있다. 디렉터리 연산과 디렉터리 내용을 열거하는 연산도 보호되어야 한다.
댓글남기기