데이터 베이스 요약 - 8. 뷰와 시스템 카탈로그
8.1. 뷰
ANSI/SPARC 3단계 아키텍처에서 외부 뷰는 사용자가 보는 데이터베이스의 구조. 관계 데이터베이스에서의 뷰는 외부 뷰가 아닌, 하나의 가상 릴레이션(virtual relation)을 의미.
뷰는 기존의 기본 릴레이션(base relation; 실제 릴레이션)에 대한 SELECT문의 형태로 정의됨. 뷰는 릴레이션으로부터 데이터를 검색하거나 갱신할 수 있는 동적인 창(dynamic window)의 역할.
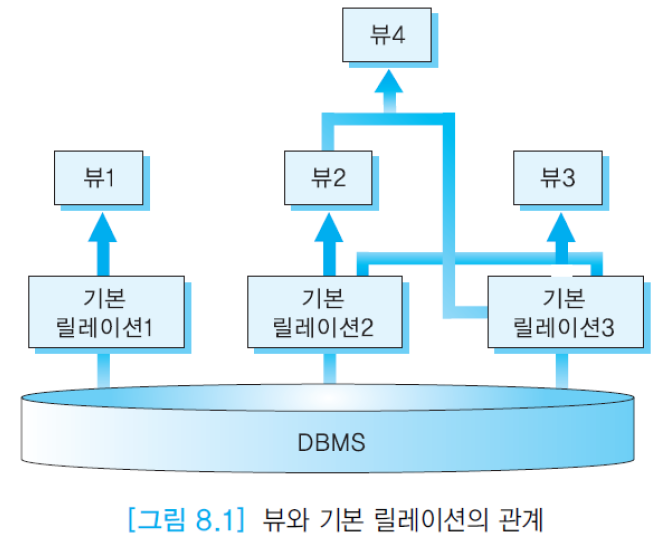
스냅샷(snapshot)은 어느 시점에 SELECT문의 결과를 기본 릴레이션의 형태로 저장해 놓은 것. 어떤 시점의 조직체의 현황, 예를 들어 몇년 몇월 시점에 근무하던 사원들의 정보 등이 스냅샷으로 정의될 수 있음.
뷰를 정의하는 SQL문의 구문
CREATE VIEW 뷰이름 [(애트리뷰트(들))]
AS SELECT문
[WITH CHECK OPTION];
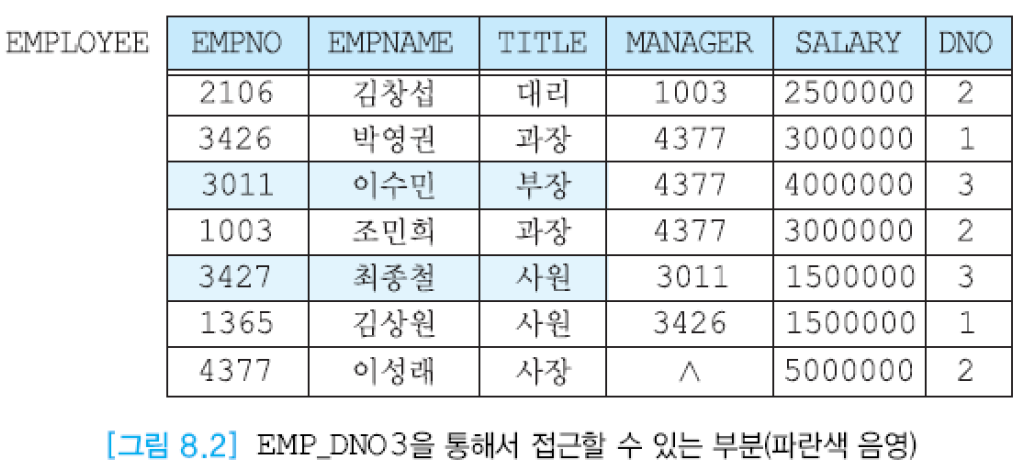
CREATE VIEW EMP_DNO3 (ENO,ENAME,TITLE)
AS SELECT EMPNO, EMPNAME, TITLE
FROM EMPLOYEE
WHERE DNO=3;
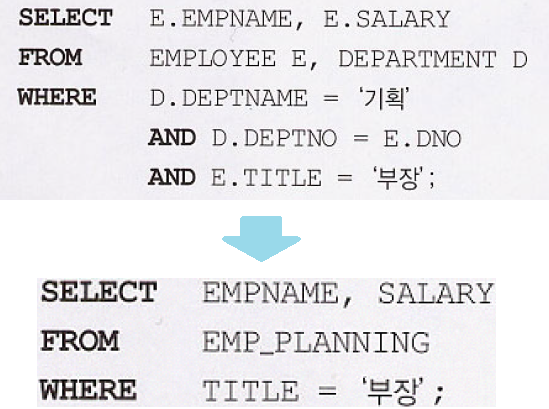
CREATE VIEW EMP_PLANNING
AS SELECT E.EMPNAME, E.TITLE, E.SALARY
FROM EMPLOYEE E, DEPARTMENT D
WHERE E.DNO=D.DEPTNO
AND D.DEPTNAME='기획';
뷰의 이름 다음에 애트리뷰트들을 생략하면 뷰를 정의하는데 사용된 SELECT문의 SELECT절에 열거된 애트리뷰트들의 이름이 뷰에 포함됨.
산술식 또는 집단함수를 사용한 경우, 조인할 때 가져온 애트리뷰트들의 이름이 같게 되는 경우에는, 모든 애트리뷰트들의 이름을 지정해야 함.
뷰를 사용하여 데이터를 접근할 때 관계 DBMS에서 거치는 과정은 다음과 같다.
- 시스템 카탈로그로부터 뷰의 정의, 즉 SELECT문을 검색
- 기본 릴레이션에 대한 뷰의 접근 권한을 검사
- 뷰에 대한 질의를 기본 릴레이션에 대한 동등한 질의로 변환

뷰의 장점은 다음과 같다.
(1) 뷰는 복잡한 질의를 간단하게 표현할 수 있게 함.
(2) 뷰를 정의할 때 WITH CHECK OPTION을 사용하면, 뷰는 데이터 무결성을 보장하는데 활용됨.
기본적으로 뷰를 통해 투플을 추가하거나 수정할 때, 투플이 뷰를 정의하는 SELECT문의 WHERE절의 기준에 맞지 않으면 뷰의 내용에서 사라짐.
(3) 뷰는 데이터 독립성을 제공함. 뷰는 데이터베이스의 구조가 바뀌어도 기존의 질의를 다시 작성할 필요성을 줄일 수도 있음.
(4) 뷰는 데이터 보안 기능을 제공함. 뷰는 원본이 되는 기본 릴레이션에 직접 접근할 수 있는 권한을 부여하지않고, 뷰를 통해 데이터를 접근하도록 함.
뷰는 일반적으로 기본 릴레이션의 일부 애트리뷰트들 또는 일부 투플들을 검색하는 SELECT문으로 정의되므로, 뷰를 통해서 접근하면 기본 릴레이션의 일부만 검색할 수 있음.
(5) 동일한 데이터에 대한 여러 가지 뷰를 제공함. 뷰는 사용자들의 그룹이 각자 특정한 기준에 따라 데이터를 접근하도록 함.
뷰에 대한 갱신도 기본 릴레이션에 대한 갱신으로 변환됨.
갱신이 불가능한 뷰는 다음과 같다.
- 릴레이션 위에서 정의되었으나, 그 릴레이션의 기본 키가 포함되지 않은 뷰
- 기본 릴레이션의 애트리뷰트들 중에서 뷰에 포함되지 않은 애트리뷰트에 대해 NOT NULL이 지정되어 있을 때
- 집단 함수가 포함된 뷰
- 조인으로 정의된 뷰

8.2. 관계 DBMS의 시스템 카탈로그
시스템 카탈로그는 데이터베이스의 객체(사용자, 릴레이션, 뷰, 인덱스, 권한 등)와 구조들에 관한 모든 데이터를 포함.
시스템 카탈로그를 메타데이터라고 함. 메타데이터는 데이터에 관한 데이터라는 의미. 시스템 카탈로그는 데이터 사전(data dictionary) 또는 시스템 테이블이라고도 부름.
시스템 카탈로그는 사용자 및 질의 최적화 모듈 등 DBMS 자신의 구성요소에 의해서 사용됨. 시스템 카탈로그는 표준화되어 있지 않아서, 관계 DBMS마다 서로 다른 형태로 시스템 카탈로그 기능을 제공함.
시스템 카탈로그가 아래 질의 처리에 어떻게 활용되는가?

- SELECT문이 문법적으로 정확한지 검사
- SELECT문에서 참조하는 EMPLOYEE 릴레이션이 데이터베이스에 존재하는지 검사
- EMPLOYEE 릴레이션에 SELECT절의 애트리뷰트와 WHERE절에서 사용된 애트리뷰트가 존재하는지 확인
- SALARY 애트리뷰트가 수식에 사용되었으므로, 이것의 데이터 타입이 숫자형인지 검사. TITLE이 문자열과 비교되었으므로, 이것의 데이터 타입이 문자형인지 검사함
- 질의를 입력한 사용자가 EMPLOYEE 릴레이션의 EMPNAME, SALARY 애트리뷰트를 검색할 수 있는 권한이 있는지 확인
- TITLE 애트리뷰트와 DNO 애트리뷰트에 인덱스가 정의되어 있는지 확인
- 둘다 인덱스가 존재한다면, DBMS가 두 인덱스 중에서 조건을 만족하는 투플 수가 적은 것을 선택하기 위해 시스템 카탈로그를 사용(전체 투플 수와 각 인덱스에 존재하는 상이한 값들의 개수를 유지)
질의 최적화는 DBMS가 질의를 수행하는 여러 방법들 중에서 가장 비용이 적게 드는 방법을 찾는 과정. 질의 최적화 모듈이 정확한 결정을 내릴 수 있도록, DBMS는 시스템 카탈로그에 다양한 정보를 유지함.
관계 DBMS의 시스템 카탈로그는 사용자 릴레이션과 같은 형태로 저장되기에, 회복 기법과 동시성 제어 기법을 동일하게 사용할 수 있음. 시스템 카탈로그는 SELECT문을 사용하여 내용을 검색할 수 있음.
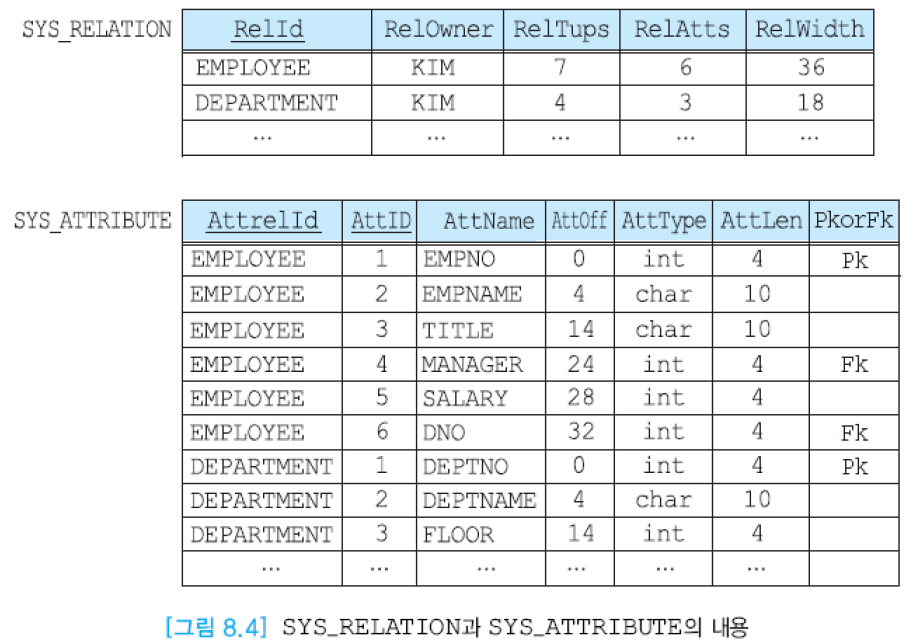
시스템 카탈로그에는 릴레이션, 애트리뷰트, 인덱스, 사용자, 권한 등 각 유형마다 별도의 릴레이션이 유지됨.
어떤 사용자도 시스템 카탈로그를 직접 갱신할 수 없음. 즉, DELETE, UPDATE 또는 INSERT문을 사용하여 시스템 카탈로그를 변경할 수 없음.
시스템 카탈로그에 유지되는 통계 정보
- 릴레이션마다 투플의 크기, 투플 수, 각 블록의 채우기 비율, 블록킹 인수, 릴레이션의 크기(블록 수)
- 뷰마다 뷰의 이름과 정의
- 애트리뷰트마다 애트리뷰트의 데이터 타입과 크기, 애트리뷰트 내의 상이한 값들의 수, 애트리뷰트 값의 범위, 선택율(조건을 만족하는 투플 수/전체 투플 수)
- 사용자마다 접근할 수 있는 릴레이션과 권한
- 인덱스마다 인덱스된 애트리뷰트, 비/클러스터링 인덱스 여부, 밀집/희소 인덱스 여부, 인덱스의 높이, 1단계인 덱스의 블록 수
8.3. 오라클의 시스템 카탈로그
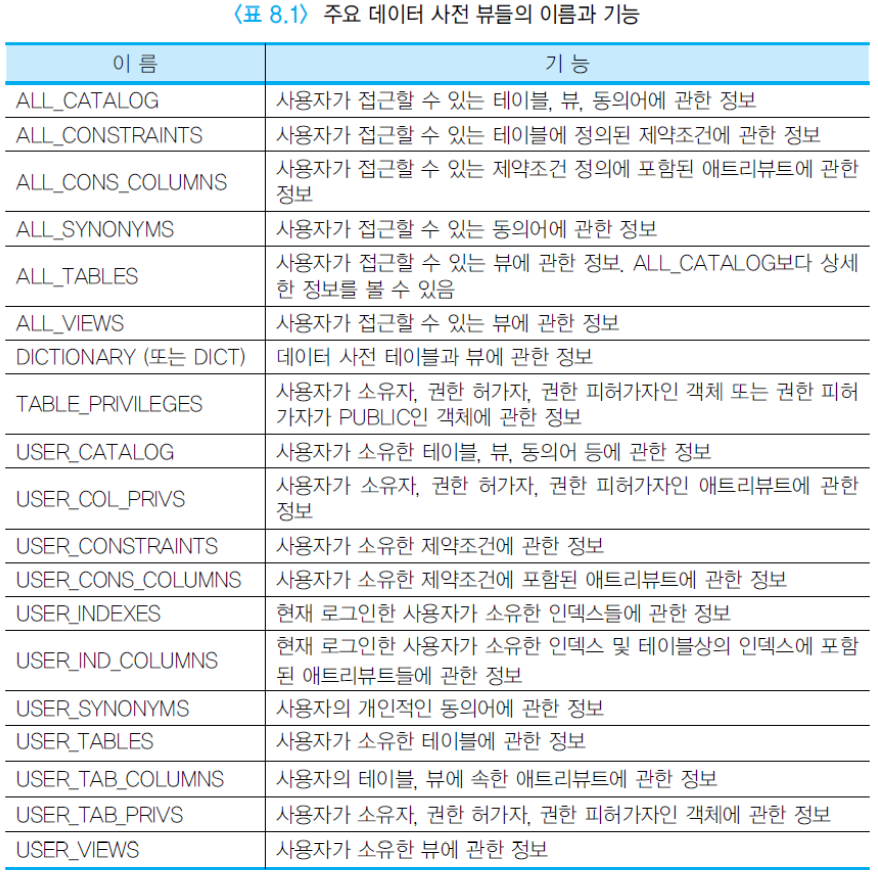
시스템 카탈로그를 데이터 사전(data dictionary)이라고 부름. 데이터 사전은 시스템 테이블 스페이스에 저장됨. 이는 기본 테이블과 데이터 사전 뷰로 구성됨.
사용자는 기본 테이블의 정보가 암호화된 형태로 저장되어 있기 때문에 직접 접근할 필요가 없으며, 일반적으로 이해하기 쉬운 형식의 정보를 제공하는 데이터 사전 뷰를 접근.
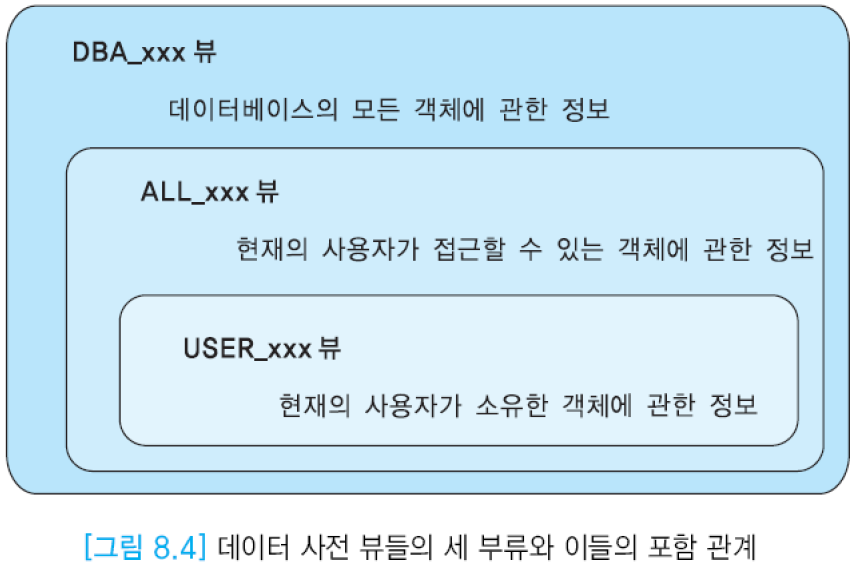
데이터 사전 뷰의 세 부류
- DBA_xxx뷰: 데이터베이스 내의 모든 객체들에 관한 정보
- ALL_xxx뷰: 현재의 사용자가 접근할 수 있는 객체들에 관한 정보
- USER_xxx뷰: 현재의 사용자가 소유하고 있는 객체들에 관한 정보
통계 정보는 ANALYZE문을 사용하여 갱신할 수 있음.
테이블에 대한 통계 정보는 ANALYZE TABLE 명령을 사용해서 갱신하고, 인덱스에 대한 통계 정보는 ANALYZE INDEX 명령을 사용해서 갱신.
ANALYZE 명령의문법
ANALYZE 객체_유형 객체_이름 연산 STATISTICS;
- 객체_유형은 테이블, 인덱스 등을 나타냄
- 객체_이름은 객체의 이름을 의미
- 연산에 COMPUTE가 사용되면 전체 테이블을 접근하여 통계 정보를 계산
- 연산에 ESTIMATE가 사용되면 데이터 표본을 추출하여 통계 정보를 계산
주기적으로 ANALYZE작업을 수행해야 함. 다량의 데이터를 일괄 작업으로 처리한 경우 등에는 바로 ANALYZE 작업을 수행하는 것이 필요.
댓글남기기