데이터 베이스 요약 - 4. 관계 대수와 SQL
4. 관계 대수와 SQL
관계 대수(relational algebra)는 어떻게 질의를 수행할 것인가를 명시하는 절차적 인어이다. 관계 DBMS에서 널리 사용되는 SQL의 이론적인 기초이며, SQL을 구현하고 최적화하기 위해 DBMS의 내부 언어로서도 사용됨.
상용 관계 DBMS들의 사실상의 표준 질의어는 SQL임. 사용자는 SQL을 사용하여 관계 데이터베이스에 릴레이션을 정의하고, 정보를 검색하고, 갱신하며, 무결성 제약조건들을 명시할 수 있음.
4.1. 관계 대수
관계 대수는 기존의 릴레이션들로부터 새로운 릴레이션을 생성함. 산술 연산자와 유사하게 단일 릴레이션이나 두 개의 릴레이션을 입력으로 받아 하나의 결과 릴레이션을 생성함. 결과 릴레이션은 또 다른 관계 연산자의 입력으로 사용될 수 있음.
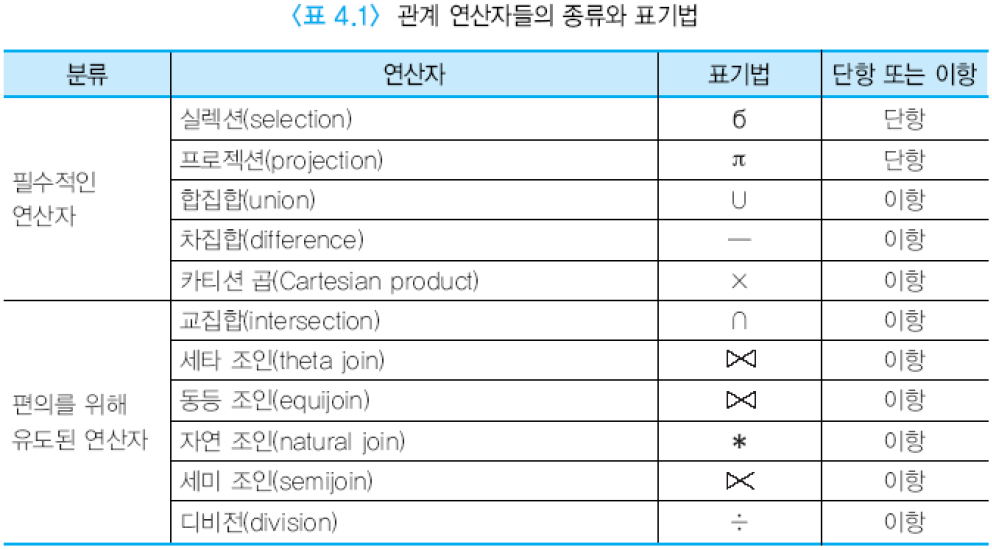
집합 연산자의 입력으로 사용되는 두 개의 릴레이션은 합집합 호환(union compatible)이어야 함. 두 릴레이션 R1(A1, A2, …, An)과 R2(B1, B2, …, Bm)이 합집합 호환일 필요 충분 조건은 n=m이고, 모든 1<=i<=n에 대해 domain(Ai)=domain(Bi).
테이블에서 실렉션, 프로젝션, 합집합, 차집합, 카티션 곱은 관계 대수의 필수적인 연산자이다. 다른 관계 연산자들은 필수적인 관계 연산자를 두 개 이상 조합하여 표현할 수 있으나 편의를 위해 존재한다. 임의의 질의어가 적어도 필수적인 관계 대수 연산자들만큼의 표현력을 갖고 있으면 관계적으로 완전(relationally complete)하다고 말함.
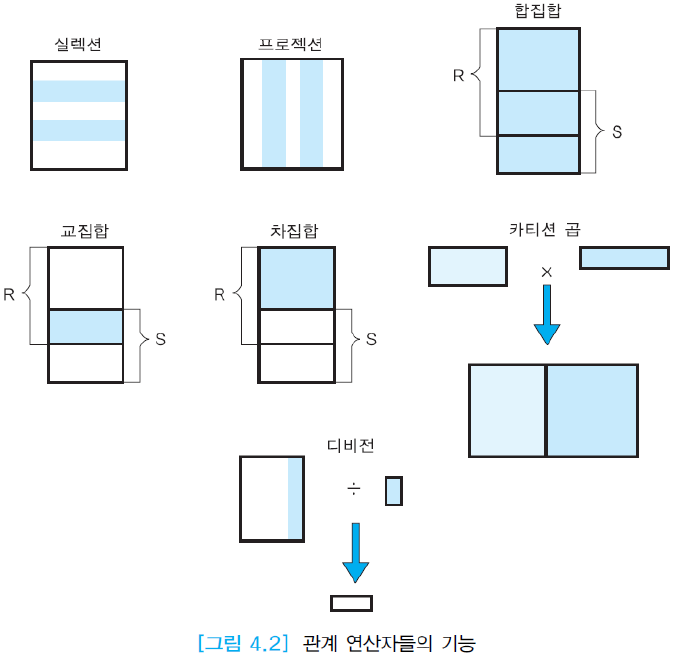
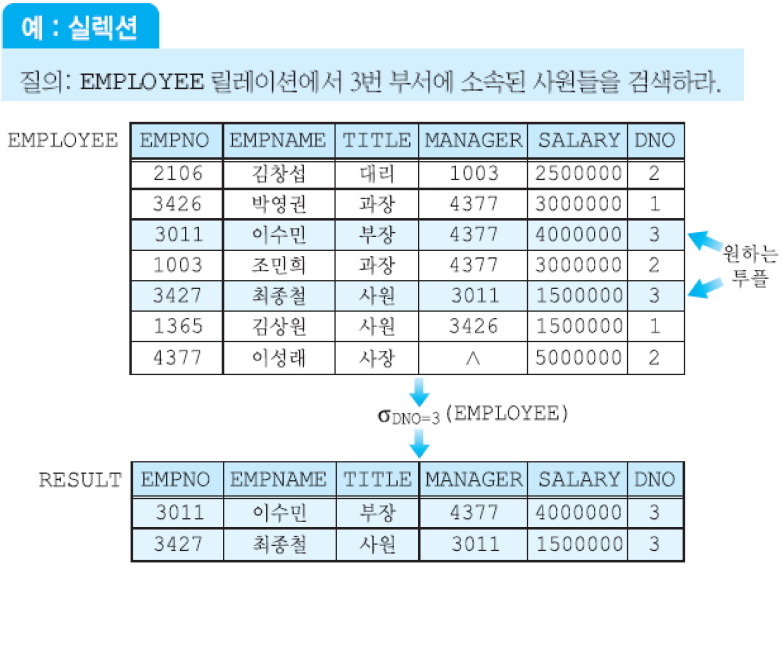
(1) 실렉션 연산자 - σ실렉션 조건(릴레이션): 한 릴레이션에서 실렉션 조건(selection condition)을 만족하는 투플들의 부분 집합을 생성함. 실렉션 조건은 릴레이션의 임의의 애트리뷰트와 상수, =, < 등의 비교 연산자, AND, OR, NOT 등의 부울 연산자를 포함.
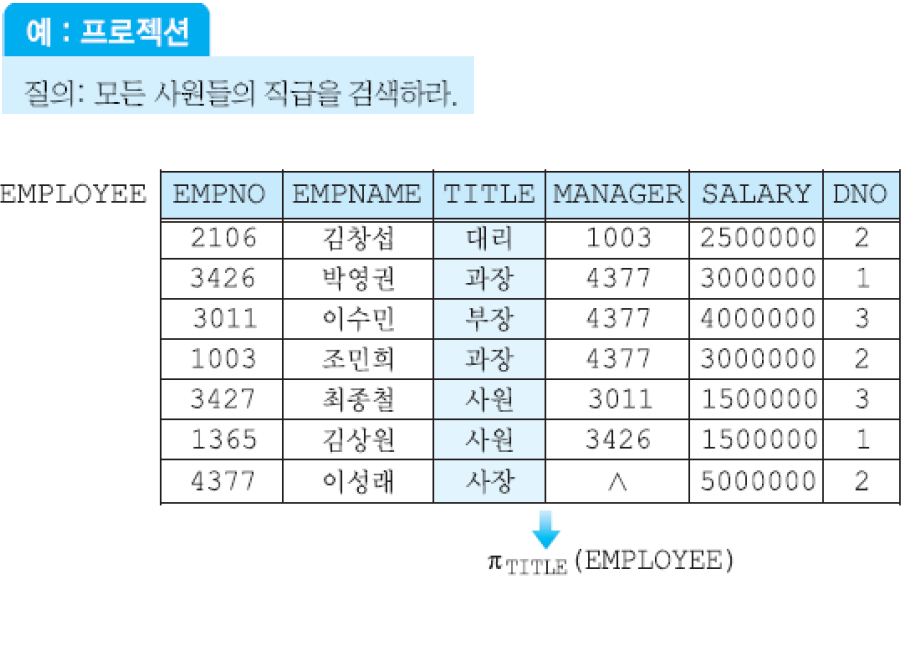
(2) 프로젝션 연산자 - π애트리뷰트 리스트(릴레이션): 한 릴레이션의 애트리뷰트들의 부분 집합을 구함. 결과로 생성되는 릴레이션은 <애트리뷰트 리스트="">에 명시된 애트리뷰트들만 가짐.
(3) 합집합 연산자 - 릴레이션1 ∪ 릴레이션2: R ∪ S는 R 또는 S에 있거나 R과 S 모두에 속한 투플들로 이루어진 릴레이션을 생성함. 결과 릴레이션에서 중복된 투플들은 제외됨. 결과 릴레이션의 애트리뷰트 이름들은 R의 애트리뷰트들의 이름과 같거나 S의 애트리뷰트들의 이름과 같음.
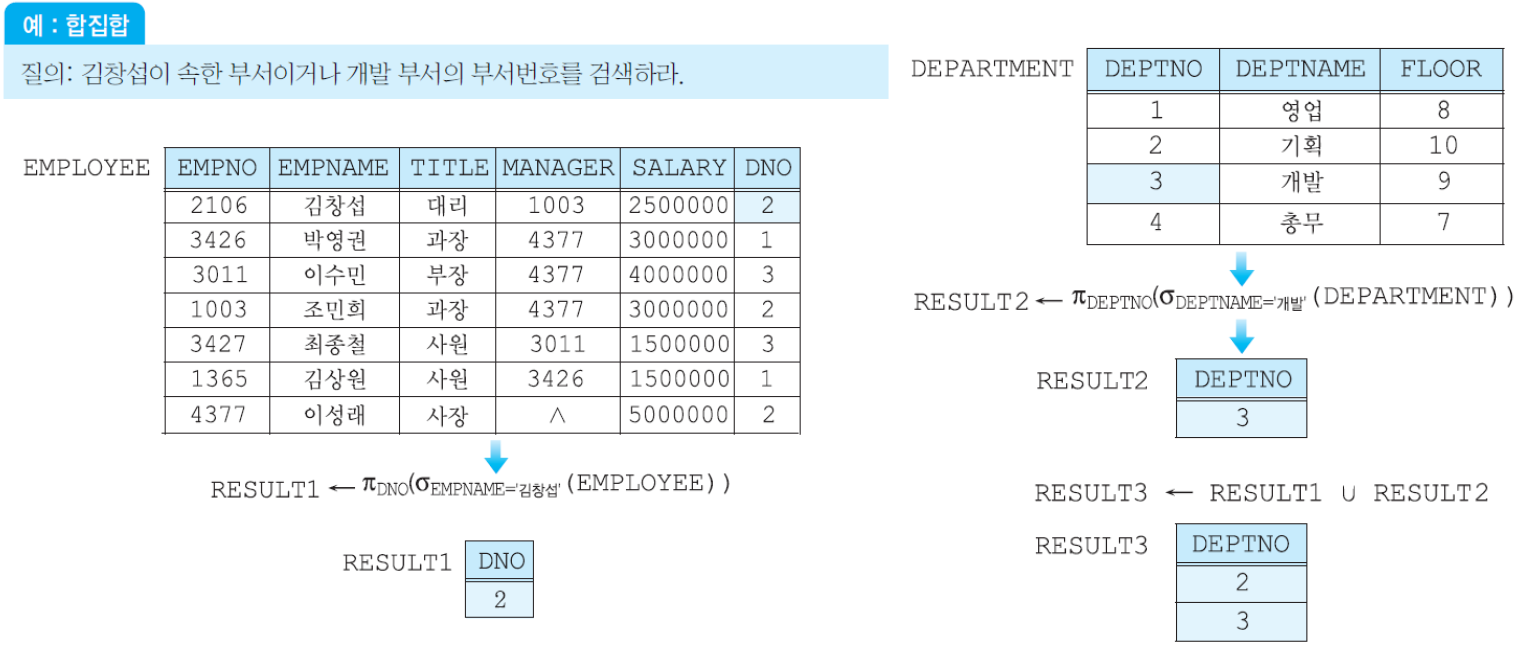
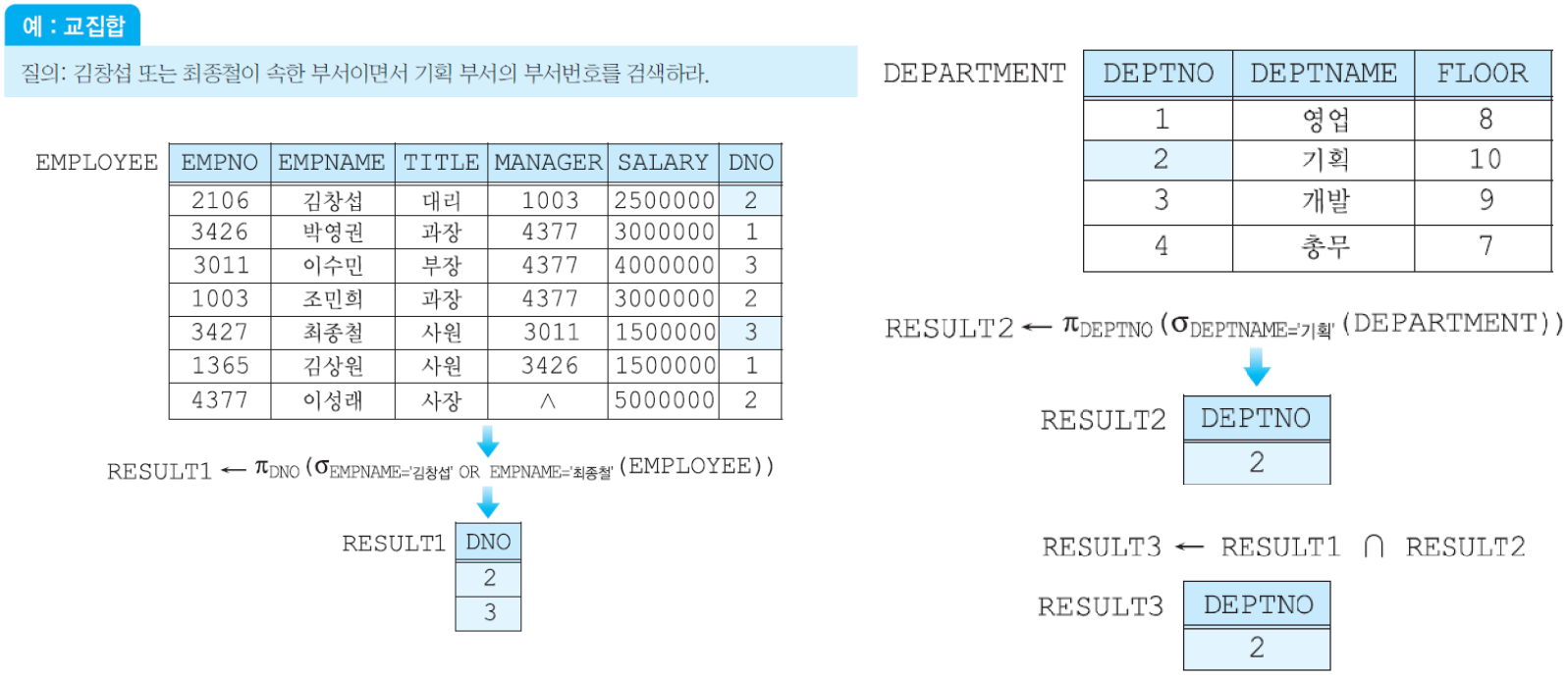
(4) 교집합 연산자 - 릴레이션1 ∩ 릴레이션2: R ∩ S는 R과 S 모두에 속한 투플들로 이루어진 릴레이션을 생성함. 결과 릴레이션의 애트리뷰트 이름들은 R의 애트리뷰트들의 이름과 같거나 S의 애트리뷰트들의 이름과 같음.
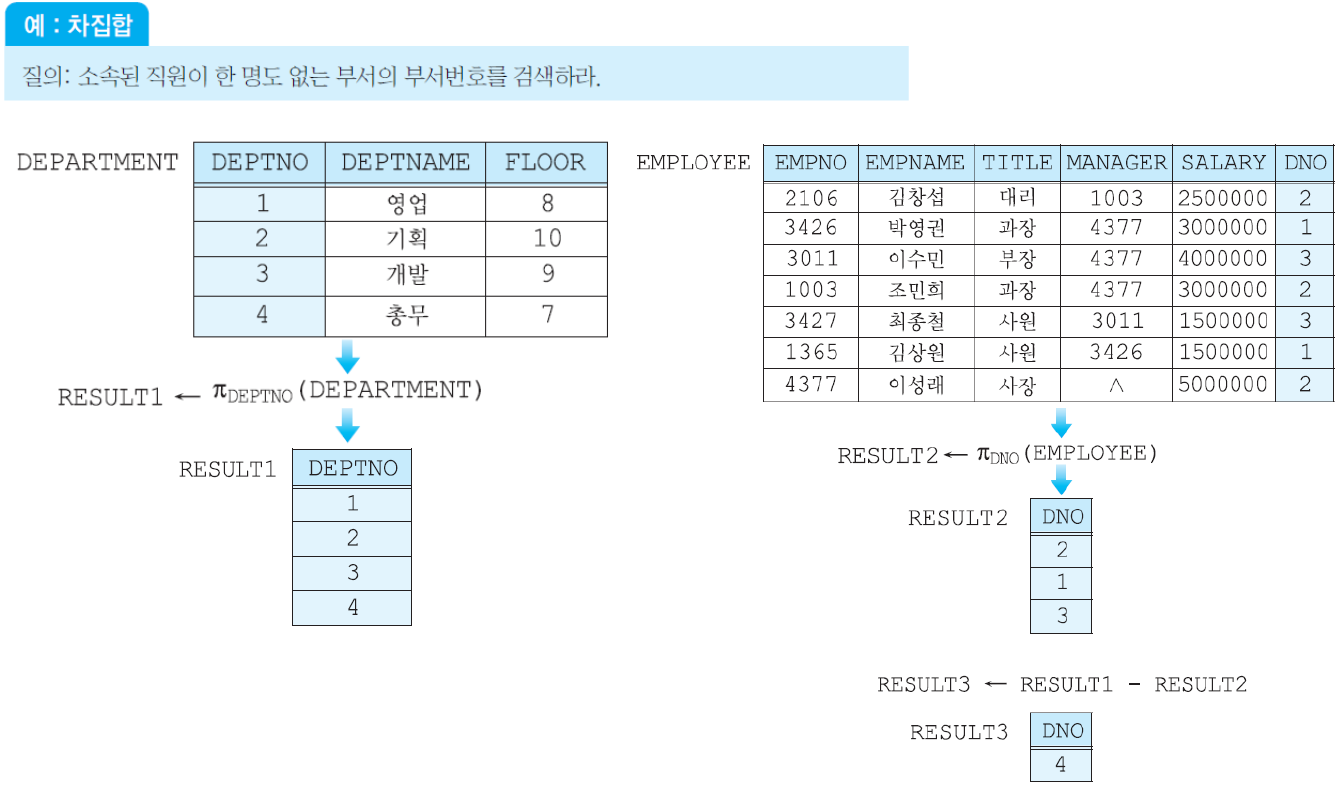
(5) 차집합 연산자 - 릴레이션1 - 릴레이션2: R - S는 R에는 속하지만 S에는 속하지 않은 투플들로 이루어진 릴레이션을 생성함. 결과 릴레이션의 애트리뷰트 이름들은 R의 애트리뷰트들의 이름과 같거나 S의 애트리뷰트들의 이름과 같음.
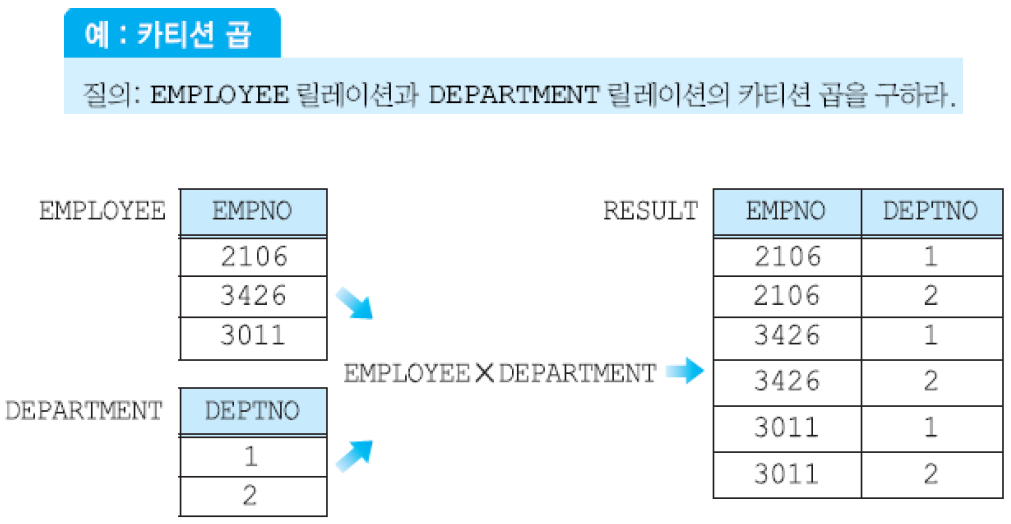
(6) 카티션 곱 연산자 - R × S: 카디날리티가 i인 릴레이션 R(A1, …, An)과 카디날리티가 j인 릴레이션 S(B1, …, Bm)의 카티션 곱 R × S는 차수가 n+m이고, 카디날리티가 i*j이고, 애트리뷰트가 (A1, A2, …, An, B1, B2, …, Bm)이며, R과 S의 투플들의 모든 가능한 조합으로 이루어진 릴레이션이다. 카티션 곱의 결과 릴레이션의 크기가 매우 클 수 있다.
(7) 세타(θ) 조인 - R ⋈조인 조건 S: 두 릴레이션 R(A1, …, An)과 S(B1, …, Bm)의 세타 조인 결과는 차수가 n+m이고, 애트리뷰트가 (A1, …, An, B1, …, Bn)이며, 조인 조건을 만족하는 투플들로 이루어진 릴레이션이다.
조인 조건은 (R의 애트리뷰트 θ S의 애트리뷰트)의 형태로 주어지며 θ는 =, < 등이 가능.
(8) 동등 조인은 세타 조인 중에서 비교 연산자가 =인 조인.
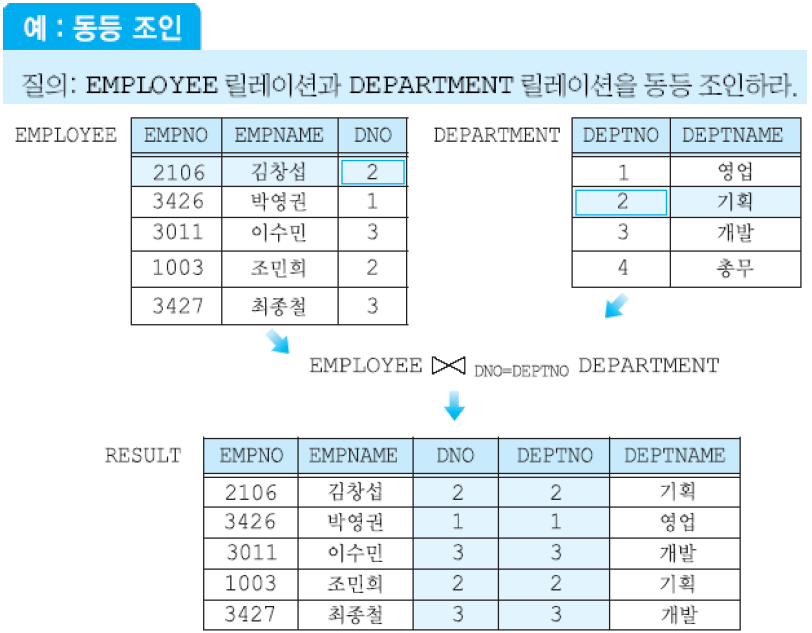
(9) 자연 조인 - R ⋈ S: 두 릴레이션의 공통된 애트리뷰트에 대해 동등 조인을 수행하고, 동등 조인의 결과 릴레이션에 있는 두 개의 조인 애트리뷰트 중 하나를 제외한 조인.
관계 데이터베이스에서 대부분의 질의는 실렉션, 프로젝션, 자연 조인으로 표현 가능.
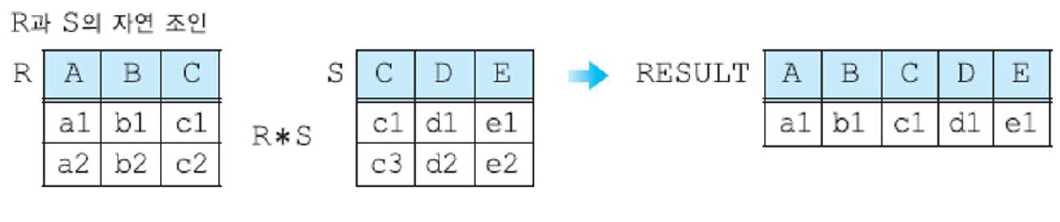
(10) 디비전 연산자 - R ÷ S: 차수가 n+m인 릴레이션 R(A1, …, An, B1, …, Bm)과 차수가 m인 릴레이션 S(B1, …, Bm)의 디비전 R ÷ S는 차수가 n이고, S에 속하는 모든 투플 u에 대하여 투플 tu(투플 t와 투플 u을 결합한 것)가 R에 존재하는 투플 t들의 집합.
릴레이션 S의 모든(ALL) 투플 값과 쌍을 이루는 릴레이션 R의 A1, …, An 값.
“모든 …에 대해 ~하는” 형태의 질의에 사용될 수 있음.
SQL로 표현할 때 동치를 활용: ~하지 않는 …가 없다.
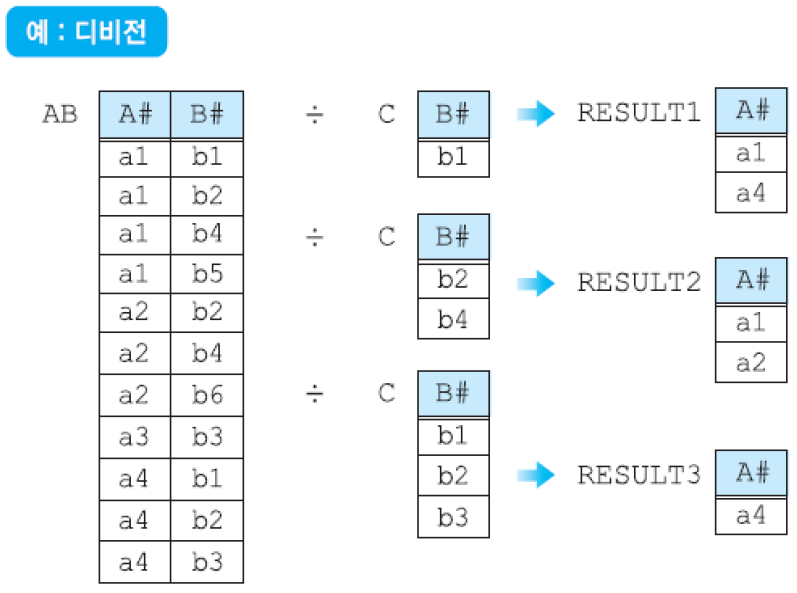
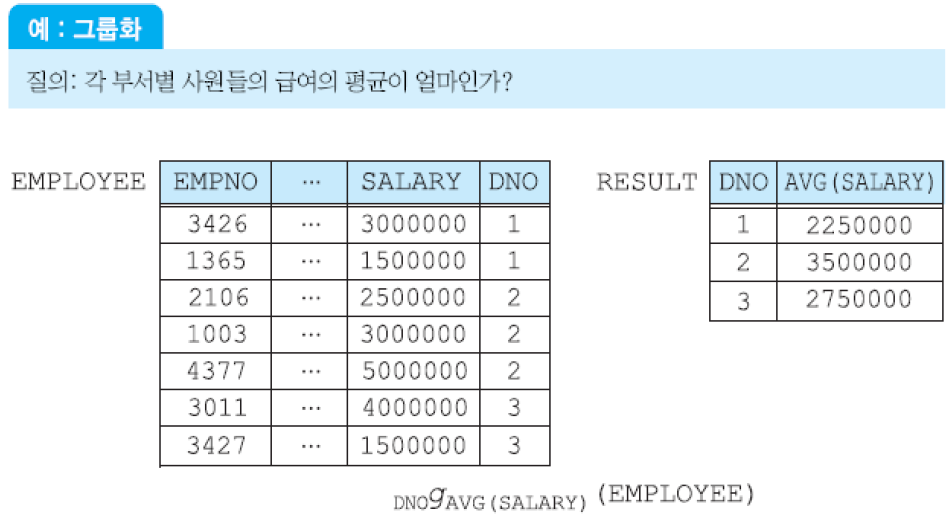
추가된 관계 연산자 (1) 집단(aggregation) 함수: AVG, SUM, MIN, MAX, COUNT 등.
추가된 관계 연산자 (2) 그룹화: 각 그룹에 대해 집단 함수를 적용.
추가된 관계 연산자 (3) 외부조인: 상대 릴레이션에서 대응되는 투플을 갖지 못하는 투플이나, 조인 애트리뷰트에 널값이 들어 있는 투플들을 다루기 위해서 조인 연산을 확장한 조인.
두 릴레이션에서 대응되는 투플들을 결합하면서, 대응되는 투플을 갖지 않는 투플과 조인 애트리뷰트에 널값을 갖는 투플도 결과에 포함시킴.
(3-1) 왼쪽 외부 조인 - R ⟕ S: 릴레이션 R과 S의 왼쪽 외부 조인 연산은 R의 모든 투플들을 결과에 포함시키고, 만일 릴레이션 S에 관련된 투플이 없으면 결과 릴레이션에서 릴레이션 S의 애트리뷰트들은 널값으로 채움.

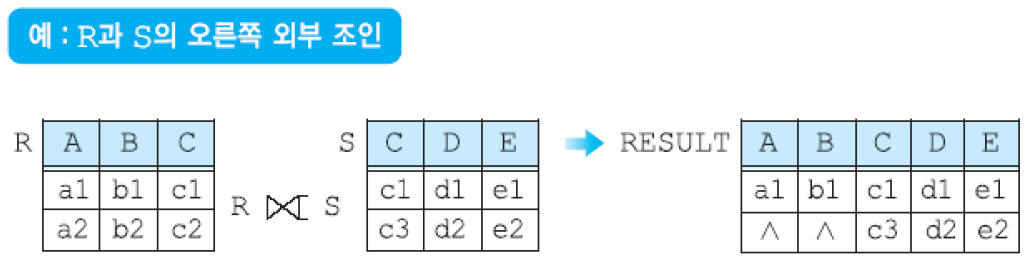
(3-2) 오른쪽 외부 조인 - R ⟖ S: 릴레이션 R와 S의 오른쪽 외부 조인 연산은 S의 모든 투플들을 결과에 포함시키고, 만일 릴레이션 R에 관련된 투플이 없으면 결과 릴레이션에서 릴레이션 R의 애트리뷰트들은 널값으로 채움.
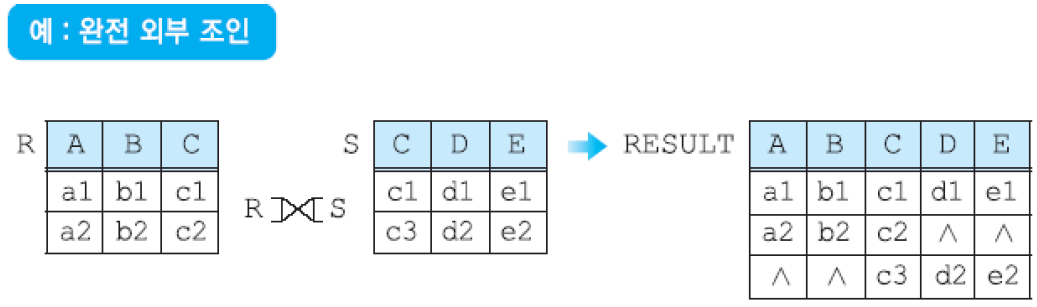
(3-3) 완전 외부 조인 - R ⟗ S: 릴레이션 R와 S의 완전 외부 조인 연산은 R과 S의 모든 투플들을 결과에 포함시키고, 만일 상대 릴레이션에 관련된 투플이 없으면 결과 릴레이션에서 상대 릴레이션의 애트리뷰트들은 널값으로 채움.
R ⟗ S = (R ⟕ S) ∪ (R ⟖ S)
4.2. SQL 개요
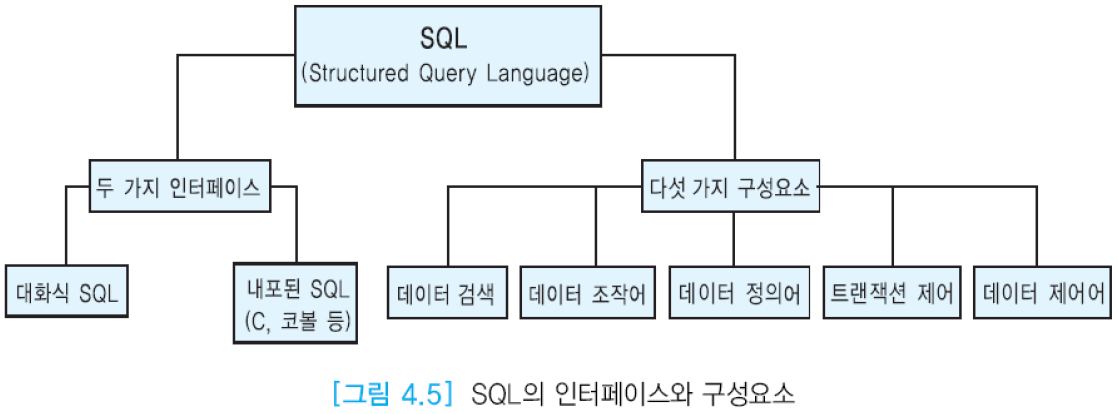
SQL은 비절차적 언어이므로 사용자는 자신이 원하는 바(what)만 명시하며, 원하는 것을 처리하는 방법(how)은 명시할 수 없음. 관계 DBMS는 사용자가 입력한 SQL문을 번역하여 사용자가 요구한 데이터를 찾는데 필요한 모든 과정을 담당.
4.3. 데이터 정의어와 무결성 제약조건

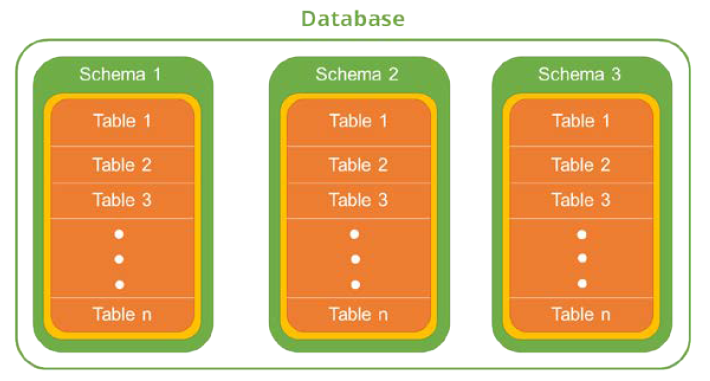
SQL2에서는 동일한 데이터베이스 응용에 속하는 릴레이션, 도메인, 제약조건, 뷰, 권한 등을 그룹화하기 위해서 스키마 개념도 지원.
// 릴레이션 정의 및 제약 조건 등
CREATE TABLE EMPLOYEE (
EMPNO NUMBER NOT NULL,
EMPNAME CHAR(10) UNIQUE,
TITLE CHAR(10) DEFAULT '사원',
SALARY NUMBER CHECK (SALARY < 60000), // 제약 조건
MANAGER CHAR(10),
DNO NUMBER,
PRIMARY KEY (EMPNO),
FOREIGN KEY (MANAGER) REFERENCES EMPLOYEE (EMPNO) ON DELETE CASCAED // 외래 키, 참조 무결성 제약 조건
);
// 릴레이션 제거
DROP TABLE EMPLOYEE;
// 테이블 변경
ALTER TABLE EMPLOYEE ADD PHONE CHAR(13);
// 인덱스 생성
CREATE INDEX EMPDNO_IDX ON EMPLOYEE (DNO);
// 무결성 제약 조건의 추가 및 삭제
ALTER TABLE STUDENT ADD CONSTRAINT STUDENT_PK PRIMARY KEY (STNO);
ALTER TABLE STUDENT DROP CONSTRAINT STUDENT_PK;
4.4. SELECT 문
관계 데이터베이스에서 정보를 검색하는 SQL문. 관계 대수의 실렉션, 프로젝션, 조인, 카티션 곱 등을 결합한 것.
SELECT문의 형식에서 SELECT절과 FROM절만 필수적인 절이고, 나머지는 선택 사항.

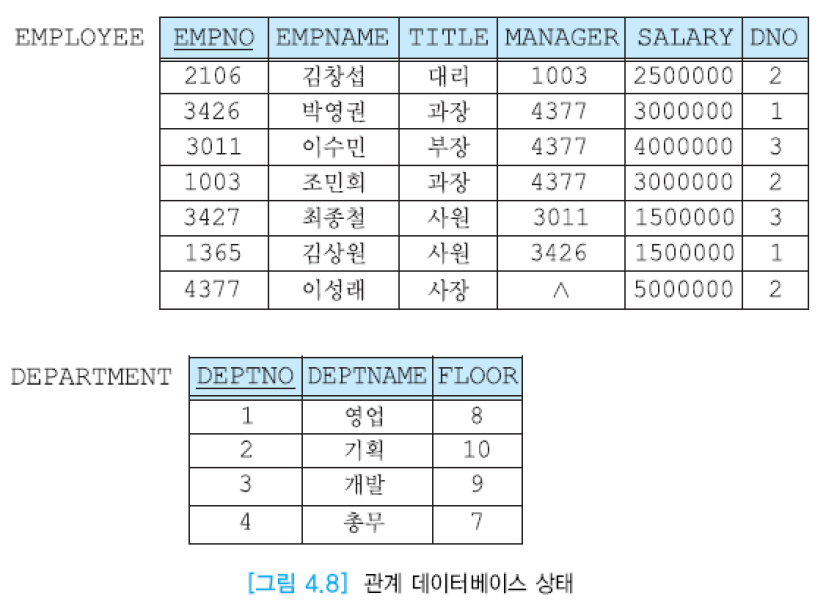
4.4절에서 사용할 데이터베이스 예시 그림은 아래와 같다.
별칭(alias): 서로 다른 릴레이션에 동일한 이름을 가진 애트리뷰트가 속해 있을 때 애트리뷰트의 이름을 구분하는 방법.
FROM EMPLOYEE AS E, DEPARTMENT AS D
WHERE E.DNO == D.DEPTNO
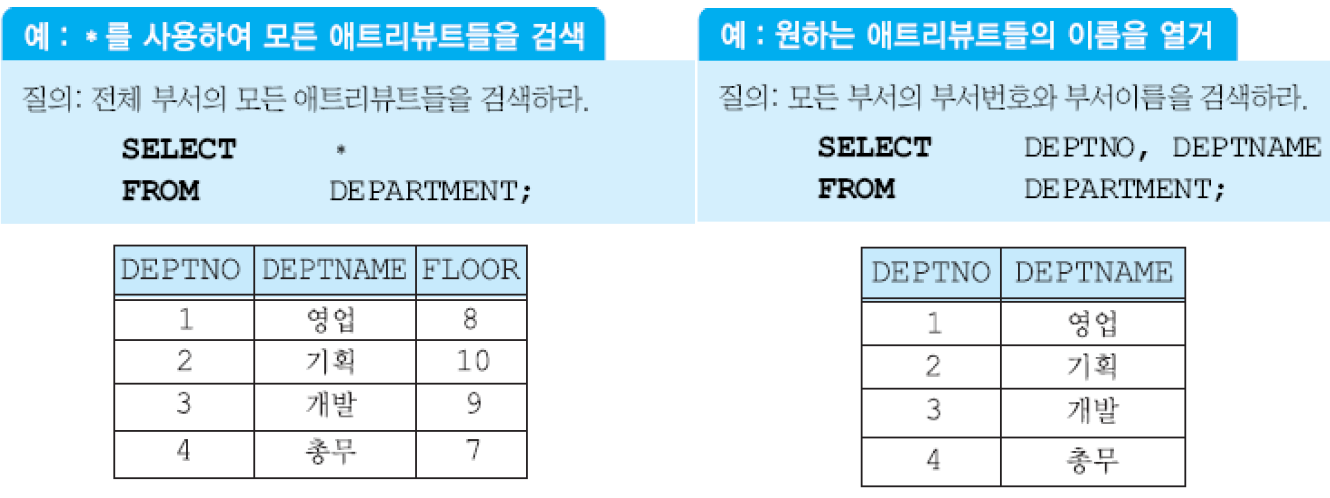
모든 애트리뷰트나 일부 애트리뷰트들을 검색.
상이한 값들을 검색.
특정할 투플들을 검색.
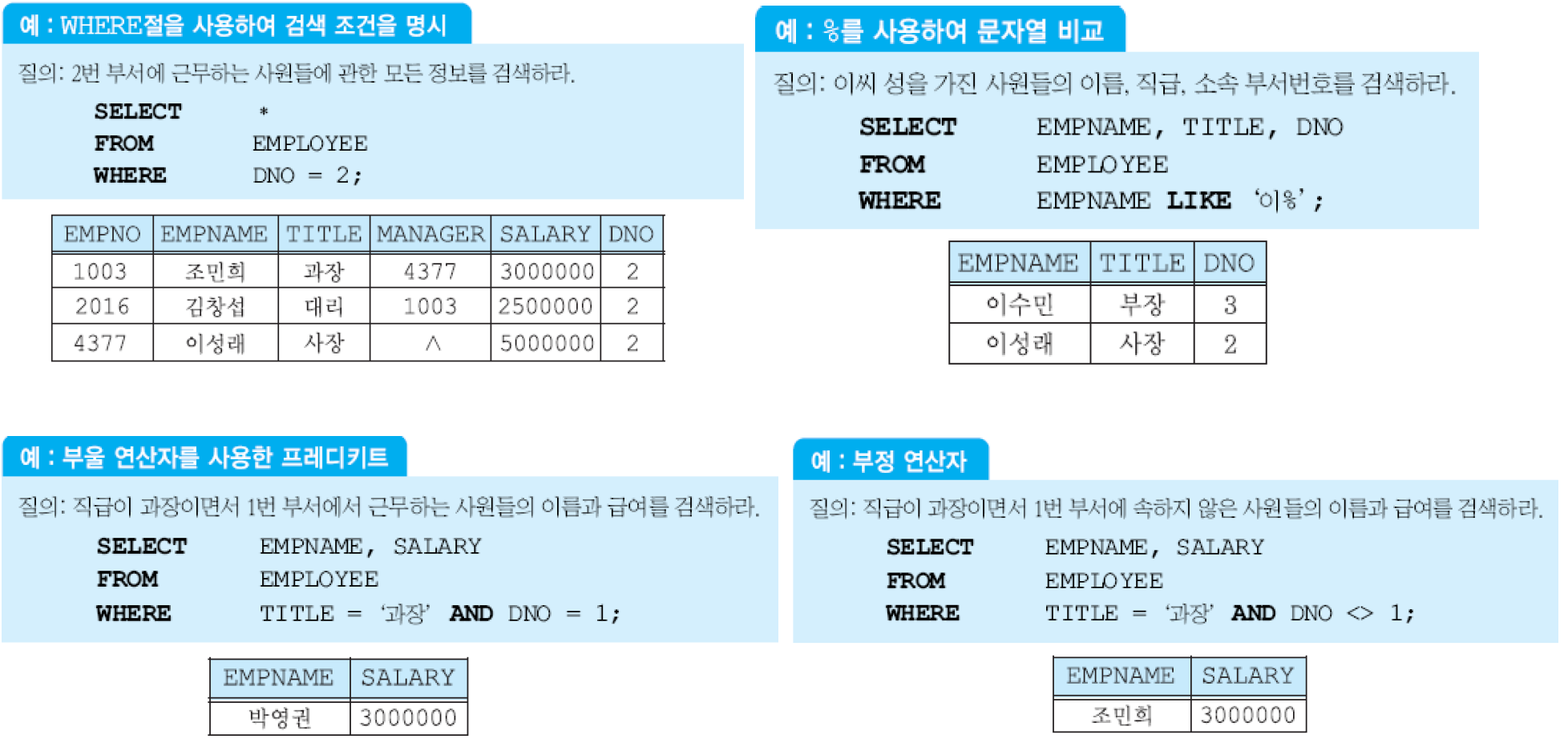
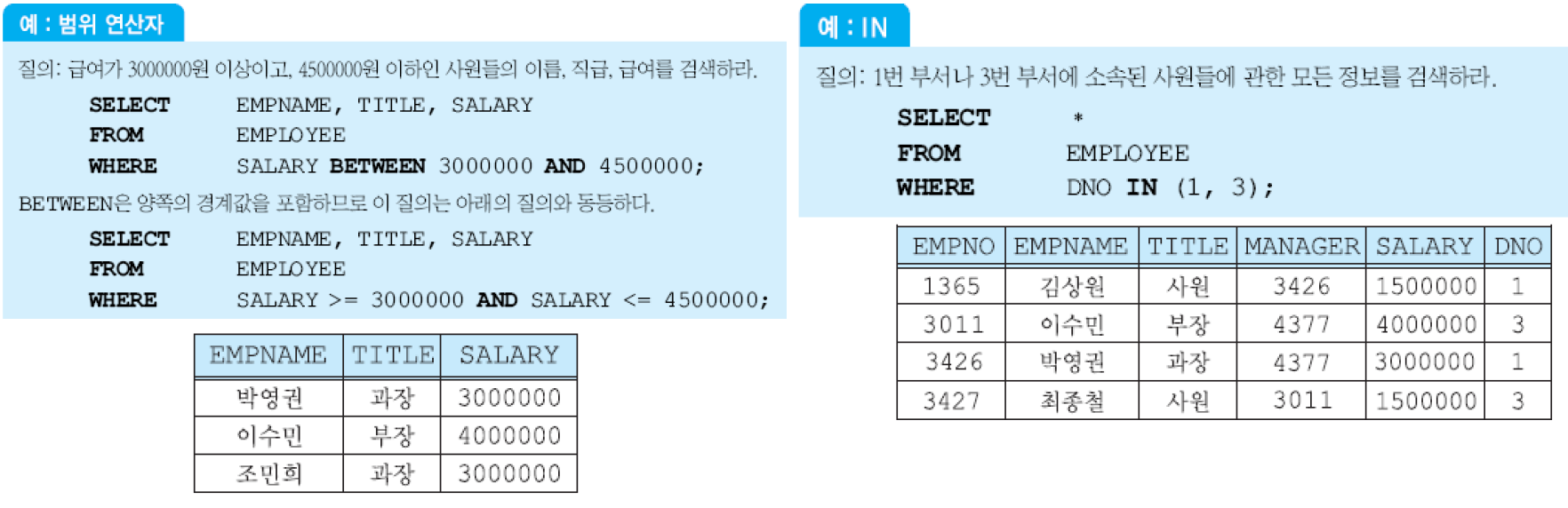
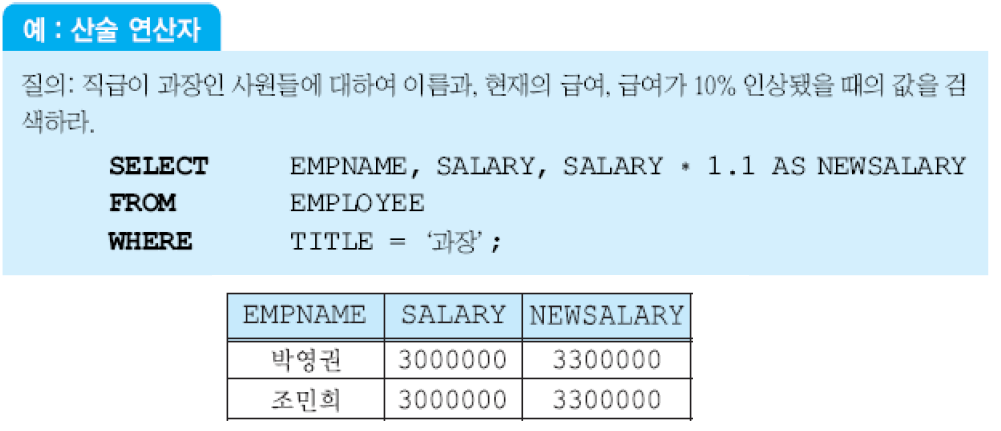
SELECT절에서 산술 연산자(+, -, *, /) 사용
널 값을 포함한 다른 값과 널 값을 +, - 등을 사용하여 연산하면 결과는 널. 어떤 애트리뷰트에 들어 있는 값이 널인가 비교하기 위해서는, ‘DNO IS NULL’, ‘DNO IS NOT NULL’
// 아래 비교 결과들은 모두 거짓
NULL > 300
NULL = 300
NULL <> 300
NULL = NULL
NULL <> NULL
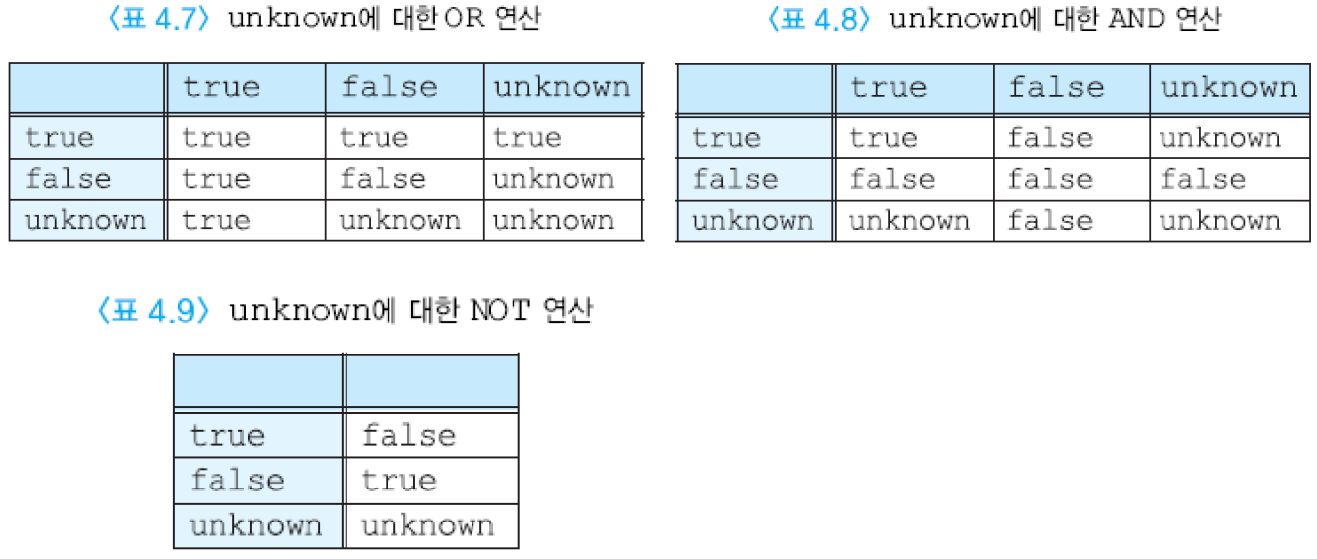
true/false/unknown 세 가지 값의 논리 (Three valued logic)
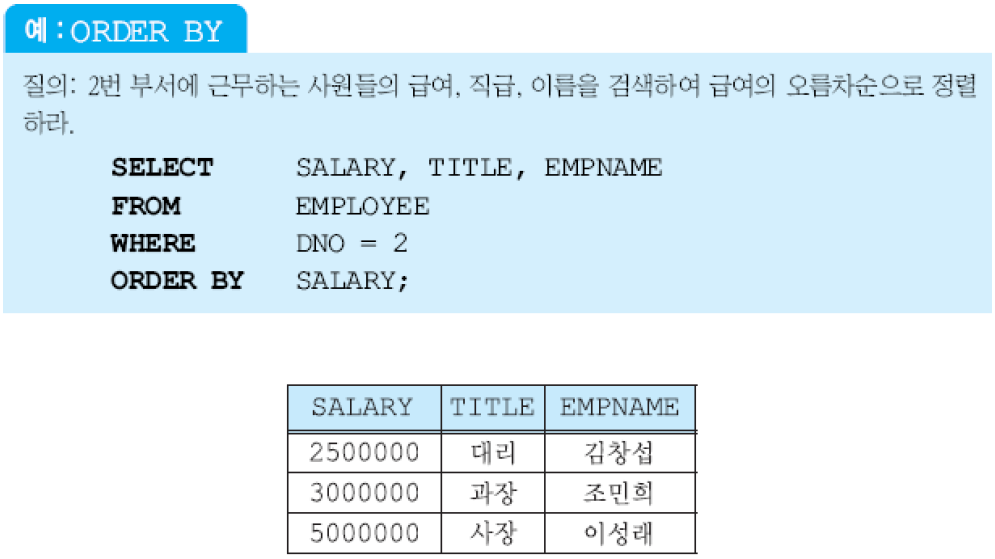
사용자가 SELECT문에서 질의 결과의 순서를 명시하지 않으면, 릴레이션에 투플들이 삽입된 순서대로 사용자에게 제시됨. ORDER BY절에서 하나 이상의 애트리뷰트를 사용하여 검색 결과를 정렬할 수 있음.
SELECT문에서 가장 마지막에 사용되는 절이며, 디폴트 정렬 순서는 오름차순(ASC). DESC를 지정하여 정렬 순서를 내림차순으로 지정할 수 있음.
널값은 오름차순에서는 가장 마지막에 나타나고, 내림차순에서는 가장 앞에 나타남. SELECT절에 명시한 애트리뷰트들을 사용해서 정렬해야 함.
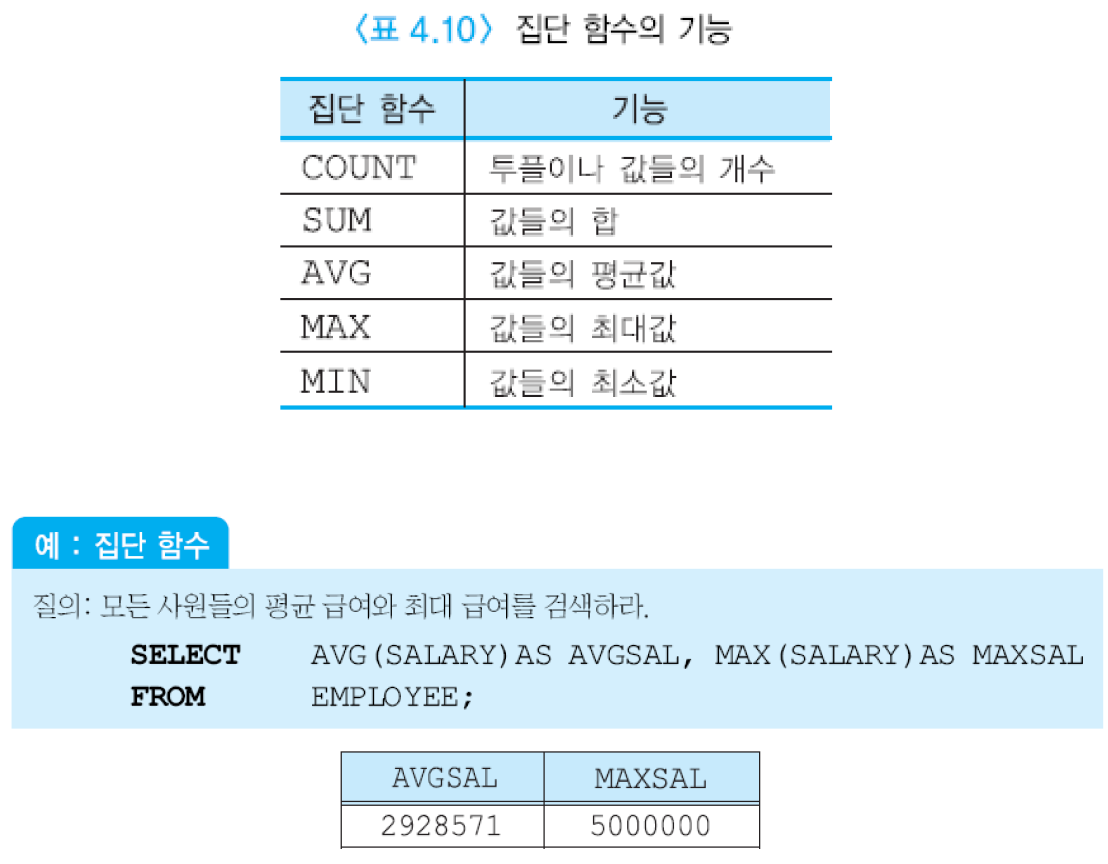
집단 함수는 데이터베이스에서 검색된 여러 투플들의 집단에 적용되는 함수. 한 릴레이션의 한 개의 애트리뷰트에 적용되어 단일 값을 반환함. SELECT절과 HAVING절에만 나타날 수 있음.
COUNT()를 제외하고는 널값을 제거한 후 남아 있는 값들에 대해서 집단 함수의 값을 구함. COUNT()는 결과 릴레이션의 모든 행들의 총 개수를 구하는 반면에 COUNT(애트리뷰트)는 해당 애트리뷰트에서 널값이 아닌 값들의 개수를 구함.
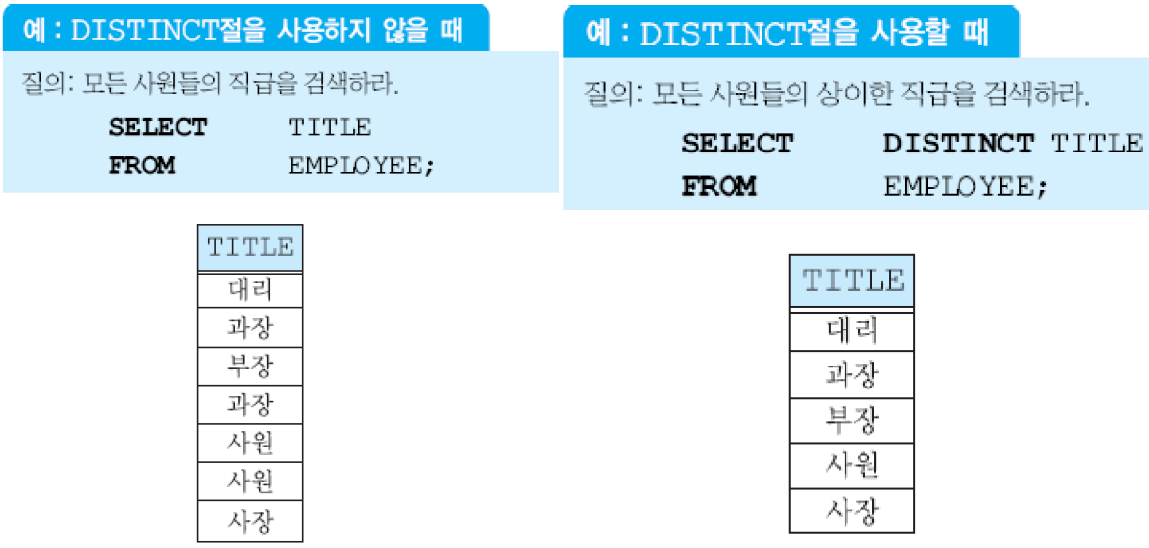
키워드 DISTINCT가 집단 함수 앞에 사용되면 집단 함수가 적용되기 전에 먼저 중복을 제거함.
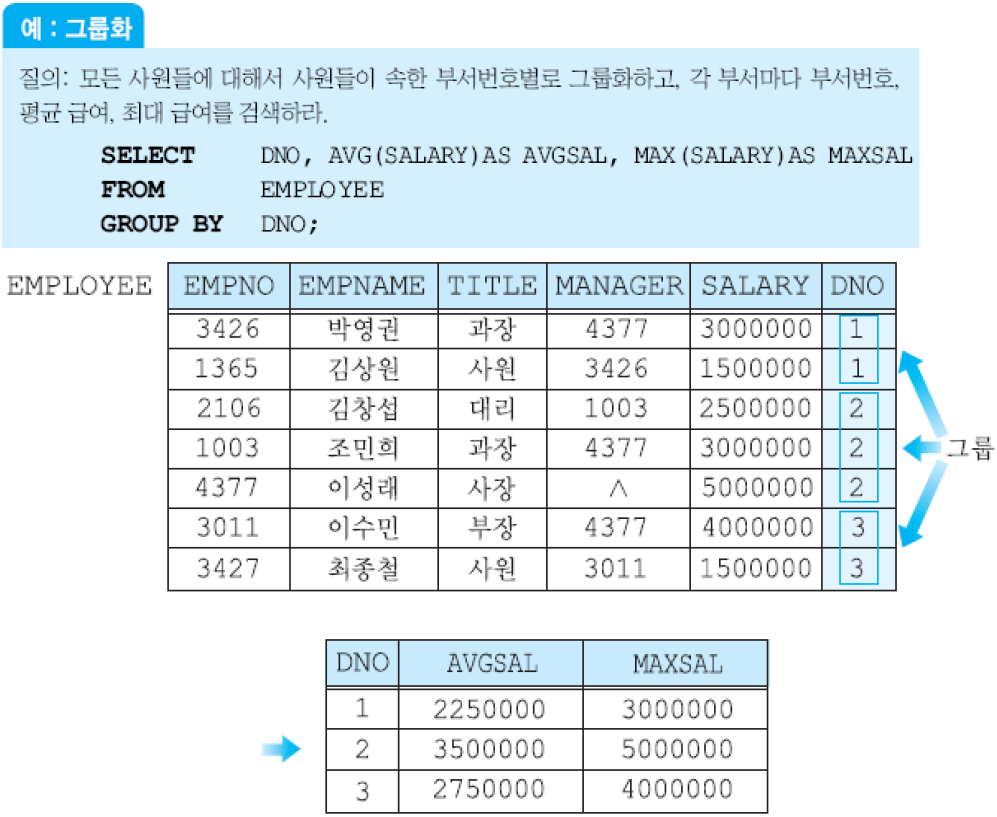
GROUP BY절에 사용된 애트리뷰트에 동일한 값을 갖는 투플들이 각각 하나의 그룹으로 묶임. 이 애트리뷰트를 그룹화 애트리뷰트(grouping attribute)라고 함.
각 그룹에 대하여 결과 릴레이션에 하나의 투플이 생성됨. SELECT절에는 집단 함수, 그룹화 애트리뷰트들만 나타날 수 있음.
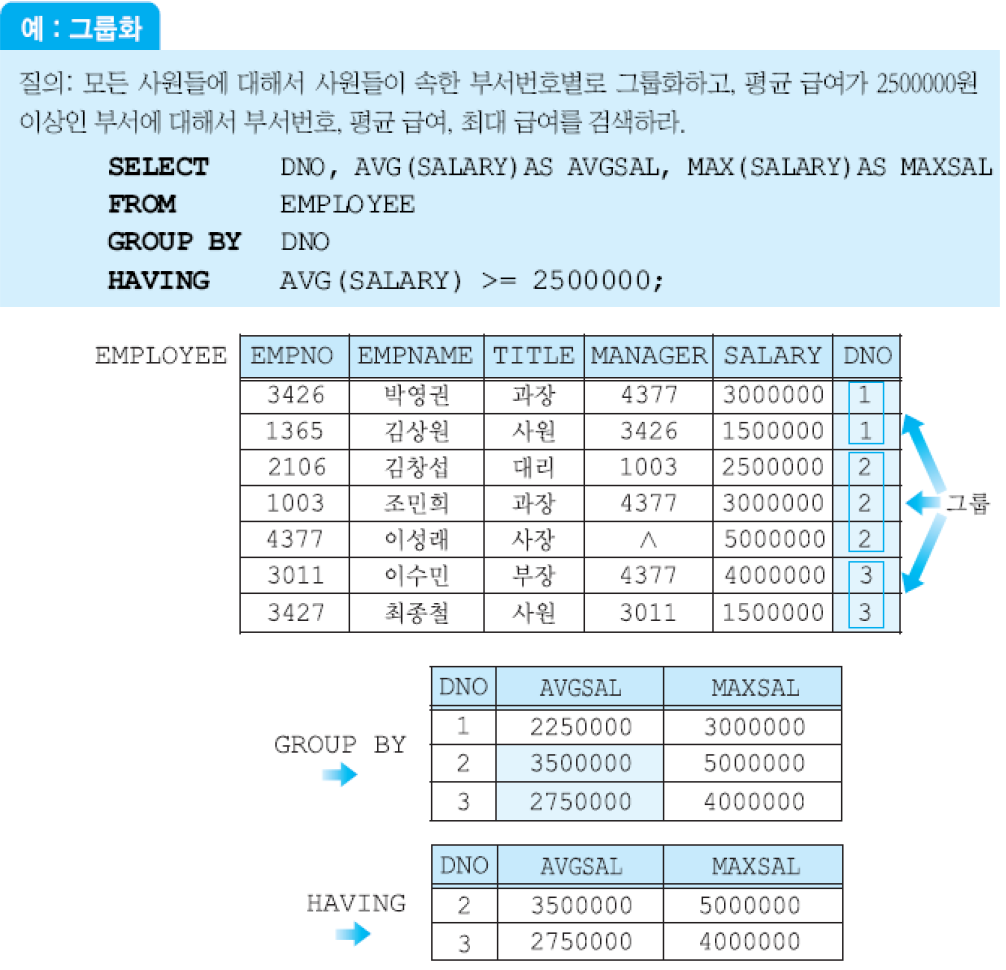
HAVING절을 사용하여, 어떤 조건을 만족하는 그룹들에 대해서만 집단 함수를 적용할 수 있음. 각 그룹마다 하나의 값을 갖는 애트리뷰트를 사용하여 각 그룹이 만족해야 하는 조건을 명시함.
그룹화 애트리뷰트에 같은 값을 갖는 투플들의 그룹에 대한 조건을 나타내고, 이 조건을 만족하는 그룹들만 질의 결과에 나타남. HAVING절에 나타나는 애트리뷰트는 반드시 GROUP BY절에 나타나거나 집단 함수에 포함되어야 함.
집합 연산을 적용하려면 두 릴레이션이 합집합 호환성을 가져야 함. UNION(합집합), EXCEPT(차집합), INTERSECT(교집합), UNION ALL(합집합), EXCEPT ALL(차집합), INTERSECT ALL(교집합). ALL이 붙은 것은 중복 튜플을 허용한다.

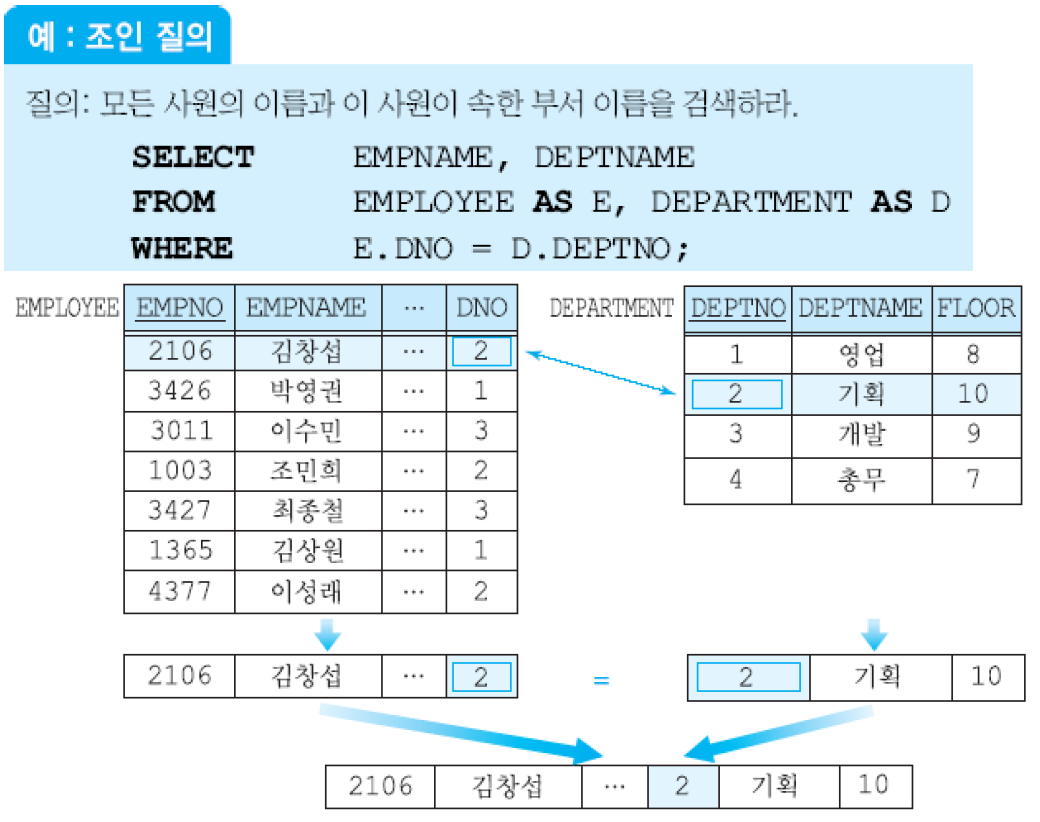
조인은 두 개 이상의 릴레이션으로부터 연관된 투플들을 결합. 일반적으로 FROM절에 두 개 이상의 릴레이션들이 열거되고, 두 릴레이션에 속하는 애트리뷰트들을 비교하는 조인 조건이 WHERE절에 포함됨.
조인 조건을 생략했을 때와 조인 조건을 틀리게 표현했을 때(매칭되는 애트리뷰트가 없음)는 카티션 곱이 생성됨. 조인 질의가 수행되는 과정은 먼저 조인 조건을 만족하는 투플들을 찾고, SELECT 절에 명시된 애트리뷰트들만 프로젝트하고, 중복을 배제하는 순서로 진행됨.
두 릴레이션의 조인 애트리뷰트 이름이 동일하다면 반드시 애트리뷰트 이름 앞에 릴레이션 이름이나 투플 변수를 사용해야 함.
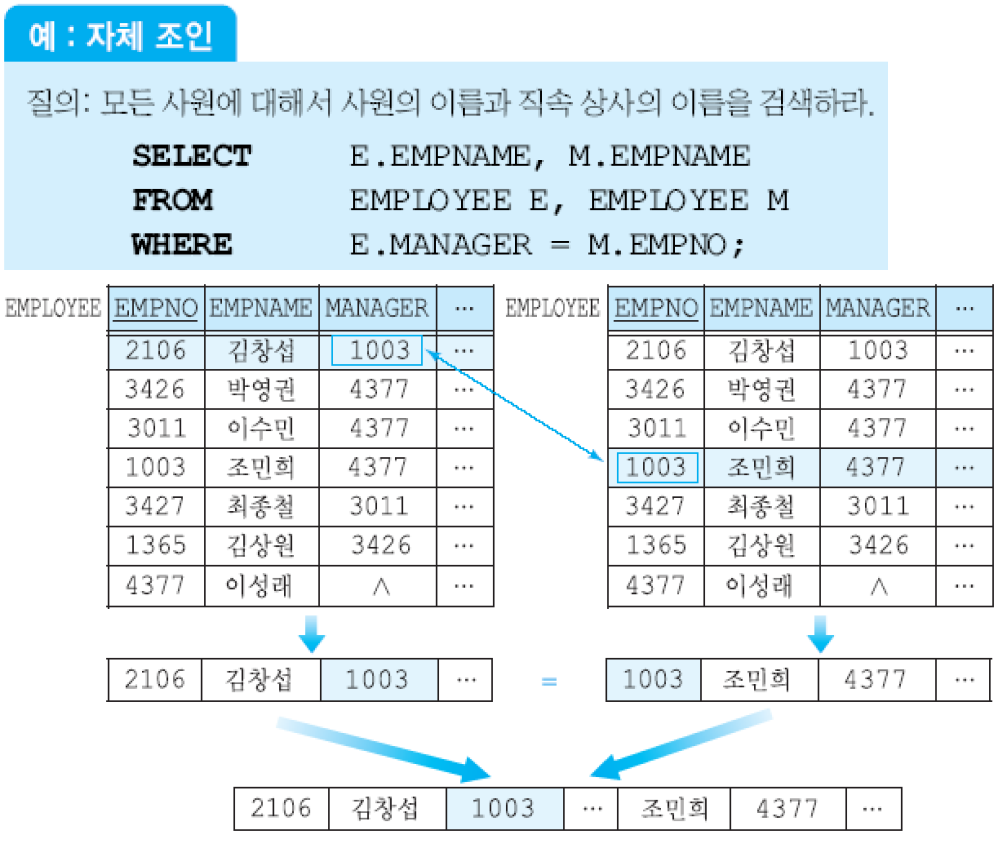
자체 조인(self join)은 한 릴레이션에 속하는 투플을 동일한 릴레이션에 속하는 투플들과 조인하는 것. 실제로는 한 릴레이션이 접근되지만 FROM절에 두 릴레이션이 참조되는 것처럼 나타내기 위해서 그 릴레이션에 대한 별칭을 두 개 지정해야 함.
중첩 질의(nested query)는 질의의 WHERE 또는 FROM절에 다시 ‘(SELECT … FROM … WHERE …)’ 형태로 포함된 SELECT문. 부질의(subquery)라고도 불림. 중첩 질의를 포함하는 질의를 외부 질의라고 부름.
중첩 질의의 결과는 세 가지 경우가 있음.
- 한 개의 스칼라값(단일 값)
- 한 개의 애트리뷰트로 이루어진 릴레이션
- 여러 애트리뷰트로 이루어진 릴레이션
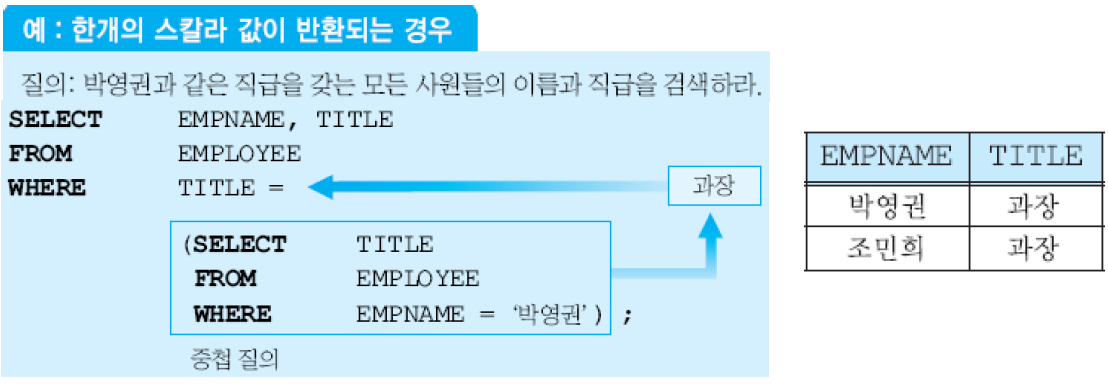
(1) 한 개의 스칼라값이 반환되는 경우. 스칼라(scala): 컬럼 값으로 사용될 수 있는 원자 값 (atomic value)가 반환된다. WHERE 절에서 상수 또는 애트리뷰트가 사용될 위치에 나타날 수 있음.
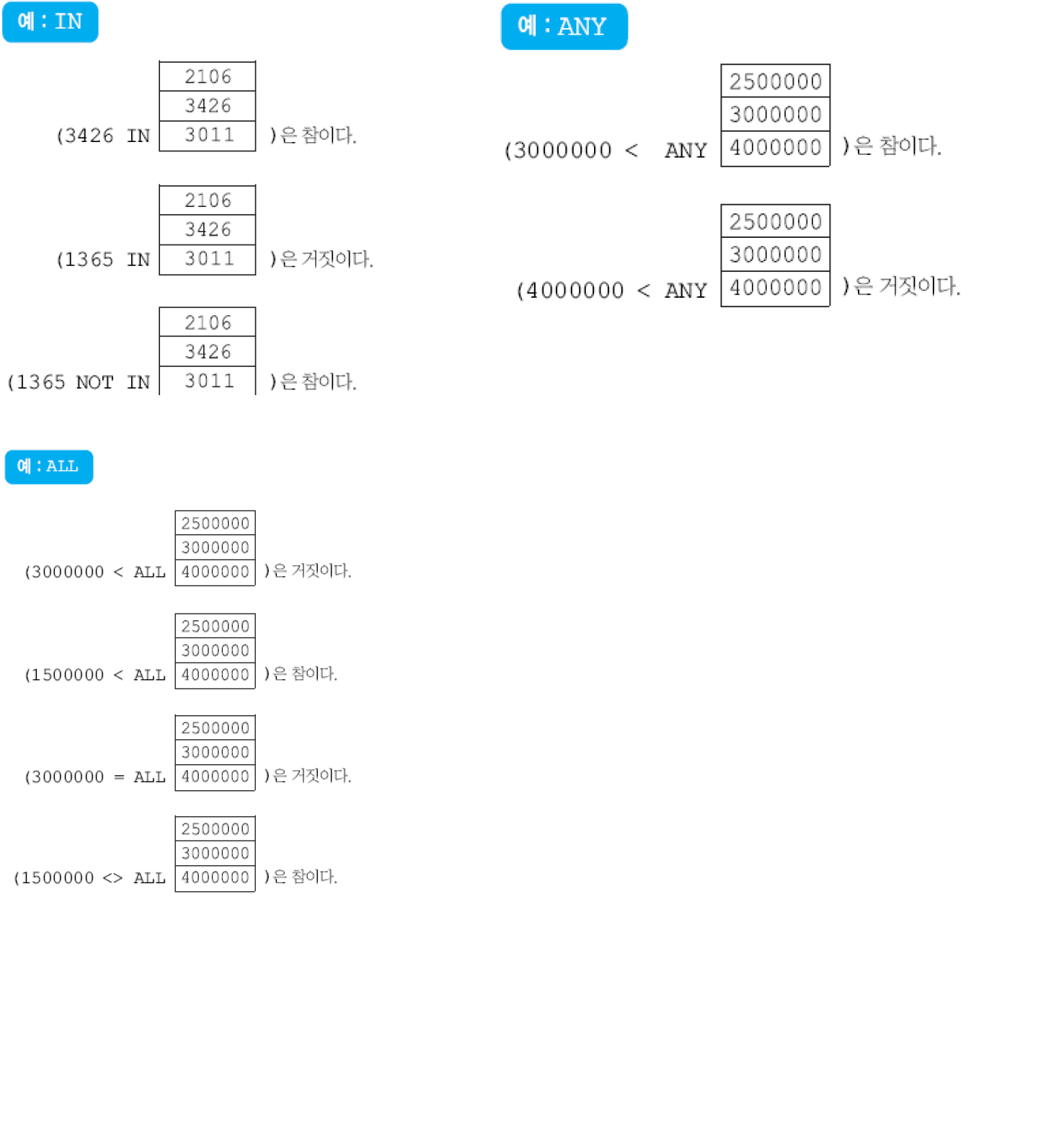
(2) 한 개의 애트리뷰트로 이루어진 릴레이션이 반환되는 경우. 중첩 질의의 결과로 한 개의 애트리뷰트로 이루어진 다수의 투플들이 반환될 수 있음. 외부 질의의 WHERE절에서 IN, ANY(SOME), ALL, EXISTS와 같은 연산자를 사용해야 함.
- IN: 한 애트리뷰트가 값들의 집합에 속하는가를 검사
- ANY: 한 애트리뷰트가 값들의 집합에 속하는 하나 이상의 값들과 어떤 관계를 갖는가를 검사
- ALL: 한 애트리뷰트가 값들의 집합에 속하는 모든 값들과 어떤 관계를 갖는가를 검사
- EXISTS: 중첩 질의의 결과가 빈 릴레이션인지 검사. 빈 릴레이션이면 거짓, 아니면 참.
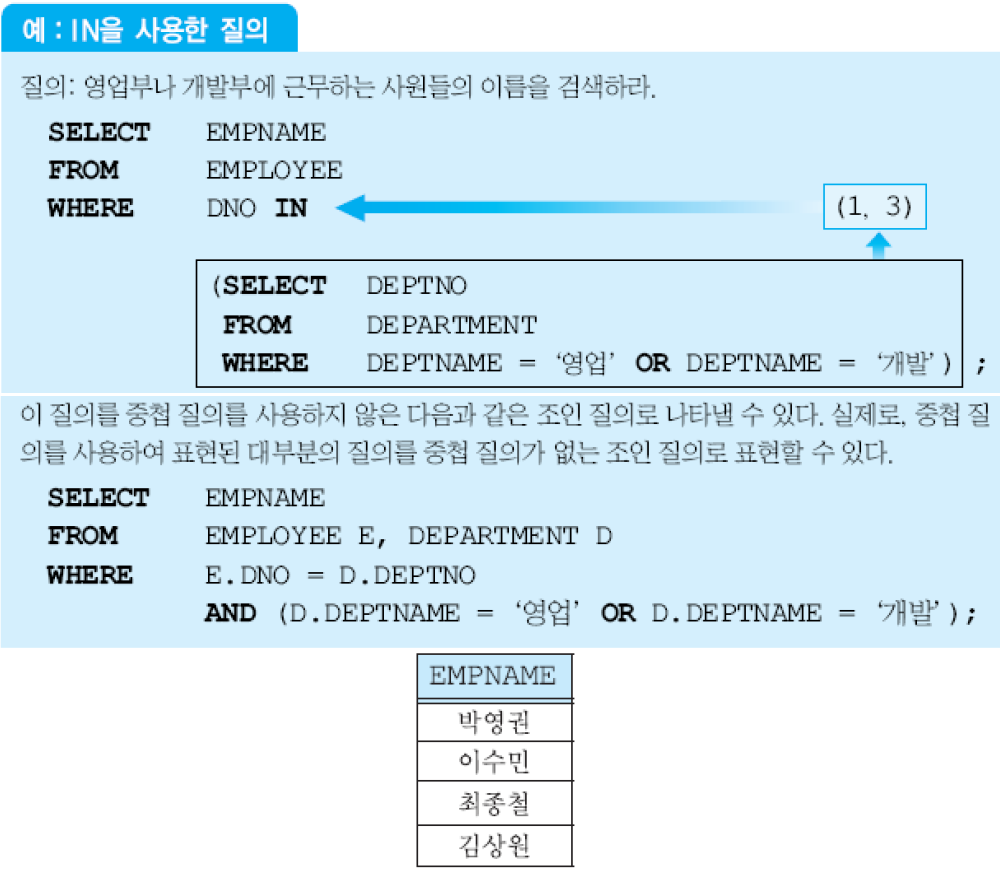
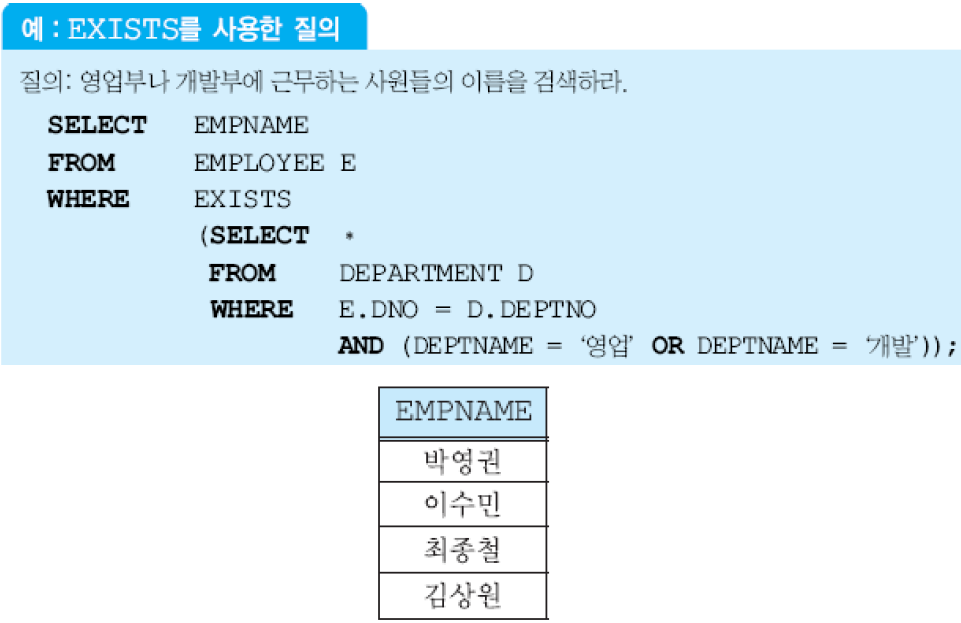
(3) 여러 애트리뷰트들로 이루어진 릴레이션이 반환되는 경우. (2)와 마찬가지로 IN, ANY, ALL, EXISTS 중에 하나를 외부 질의의 WHERE에서 사용할 수 있음. 결과 릴레이션과 호환되는 투플 구조를 갖는 투플을 사용해서 비교해야 함.
SELECT EMPNAME
FROM EMPLOYEE E
WHERE SALARY =< 1500000 AND (E.TITLE, E.DNO) IN
(SELECT TITLE, DNO
FROM EMPLOYEE
WHERE SALARY > 1500000
);
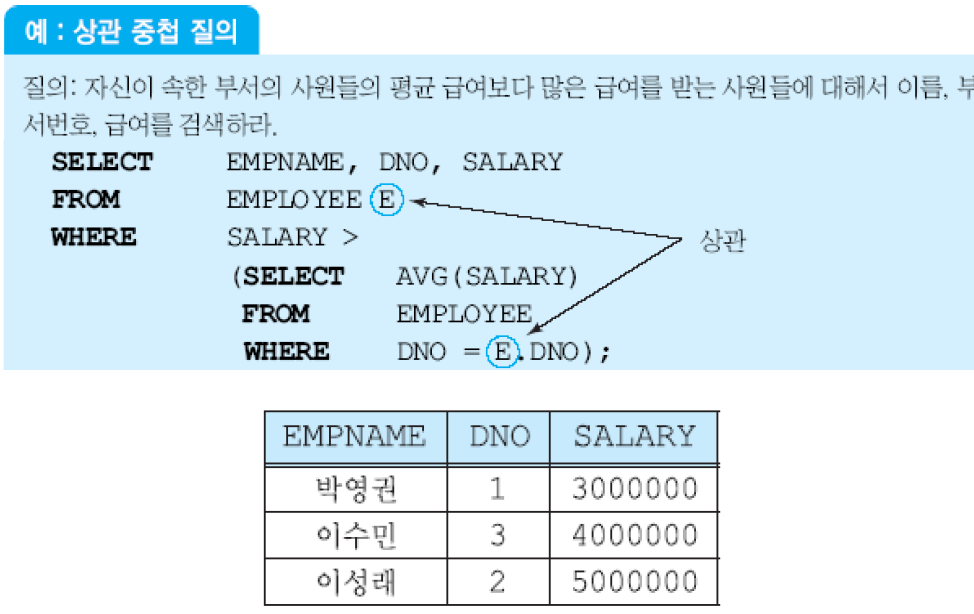
상관 중첩 질의(correlated nested query)는 중첩 질의의 WHERE절에 있는 프레디키트에서 외부 질의에 선언된 릴레이션의 일부 애트리뷰트를 참조하는 질의. 상관 중첩 질의에서는 외부 질의를 만족하는 각 투플이 구해진 후에, 투플의 수만큼 반복적으로 중첩 질의가 수행됨.
반면, 위 중첩 질의(nested query)에서는, 중첩 질의가 한 번 수행되고, 외부 질의가 수행됨.
FROM 절에에서도 저장된 일반 테이블과 함께 중첩 질의를 사용할 수 있음. 중첩 질의는 테이블 이름이 없으므로 alias를 사용하여 이름 부여.
SELECT EMPNAME, DEPTNAME
FROM EMPLOYEE E, (SELECT DEPTNO, DEPTNAME FROM DEPARTMENT) D
WHERE E.DNO = D.DEPTNO AND TITLE = '과장';
INSERT문은 기존의 릴레이션에 투플을 삽입. 릴레이션에 한 번에 한 투플씩 삽입하는 것과 한 번에 여러 개의 투플들을 삽입할 수 있는 것으로 구분.
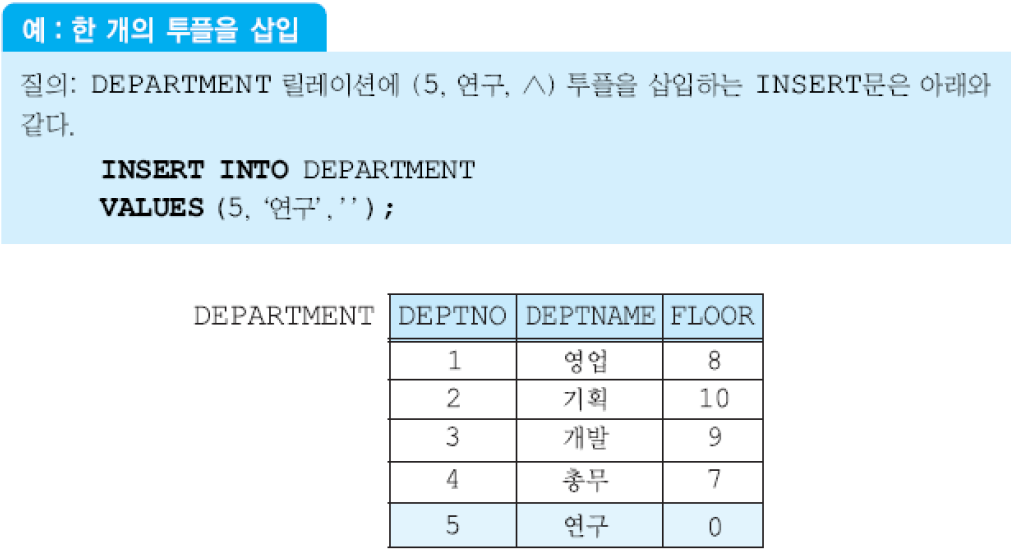
(1) 릴레이션에 한 번에 한 투플씩 삽입하는 INSERT문
INSERT INTO 릴레이션(애트리뷰트1, ..., 애트리뷰트n)
VALUES (값1, ..., 값n);
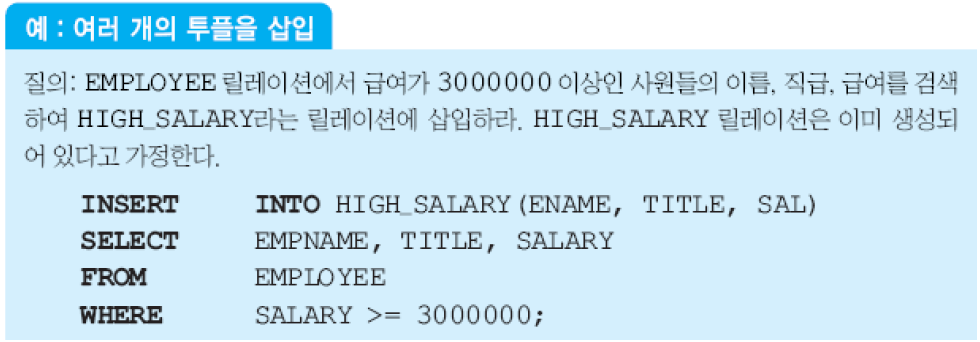
(2) 릴레이션에 한 번에 여러 개의 투플들을 삽입하는 INSERT문
INSERT INTO 릴레이션(애트리뷰트1, ..., 애트리뷰트n)
SELECT ... FROM ... WHERE ...;
DELETE문은 한 릴레이션으로부터 한 개 이상의 투플들을 삭제함.
DELETE FROM 릴레이션
WHERE 조건;

UPDATE문은 한 릴레이션에 들어 있는 투플들의 애트리뷰트 값들을 수정.
UPDATE 릴레이션
SET 애트리뷰트 = 값 또는 식[, …]
WHERE 조건;

4.6. 트리거(trigger)와 주장(assertion)
트리거는 명시된 이벤트가 발생할 때마다 DBMS가 자동적으로 수행하는, 사용자가 정의하는 문(프로시저). 데이터베이스의 무결성을 유지하기 위한 도구. 테이블 정의시 표현할 수 없는 기업의 비즈니스 규칙들을 시행하는 역할.
트리거 표현 요소
- 트리거를 활성화시키는 사건인 이벤트 (event)
- 트리거가 활성화되었을 때 수행되는 테스트인 조건 (condition)
- 트리거가 활성화되고 조건이 참일 때 수행되는 문(프로시저)인 동작 (action)

이벤트의 가능한 예로는 테이블에 투플 삽입, 투플 삭제, 투플 수정 등.
조건은 임의의 형태의 프레디키트.
동작은 데이터베이스에 대한 임의의 갱신.
어떤 이벤트가 발생했을 때 조건이 참이 되면 트리거와 연관된 동작이 수행되고, 그렇지 않으면 아무 동작도 수행되지 않음. 이벤트가 일어나기 전(before)에 동작하는 트리거와 일어난 후(after)에 동작하는 트리거로 구분.
하나의 트리거가 활성화되어 이 트리거의 SQL문이 수행되고, 연쇄적으로 다른 트리거가 활성화될 수 있음.

주장 (ASSERTION)은 SQL3에 포함되어 있으나 대부분의 상용 관계 DBMS가 아직 지원하고 있지 않음. 트리거는 제약조건을 위반했을 때 수행할 동작을 명시하는 것이고, 주장은 제약조건을 위반하는 연산이 수행되지 않도록 함.
// 주장의 구문
CREATE ASSERTION 이름
CHECK 조건;
트리거보다 좀더 일반적인 무결성 제약조건.
DBMS는 주장의 프레디키트를 검사하고, 만일 참이면 데이터베이스 수정이 허용됨.
대부분의 주장은 NOT EXISTS를 포함.
‘모든 x가 F를 만족한다’를 이와 동치인 ‘¬ F를 만족하는 x가 존재하지 않는다’로 표시하기 때문.

4.7. 내포된 SQL (embedded SQL)
SQL이 호스트 언어의 완전한 표현력을 갖고 있지 않기 때문에 모든 질의를 SQL로 표현할 수는 없음. SQL은 호스트 언어가 갖고 있는 조건문, 반복문, 입출력, 사용자와의 상호 작용, 질의 결과를 GUI로 보내는 등의 기능을 갖고 있지 않음.
C, C++, 코볼, 자바 등의 언어로 작성하는 프로그램에 SQL문을 삽입하여, 데이터베이스를 접근하는 부분을 SQL이 맡고 SQL에 없는 기능은 호스트 언어로 작성하는 것이 필요. 호스트 언어에 포함되는 SQL문을 내포된 SQL이라 부름. 데이터 구조가 불일치하는 문제(impedance mismatch 문제)가 있음.
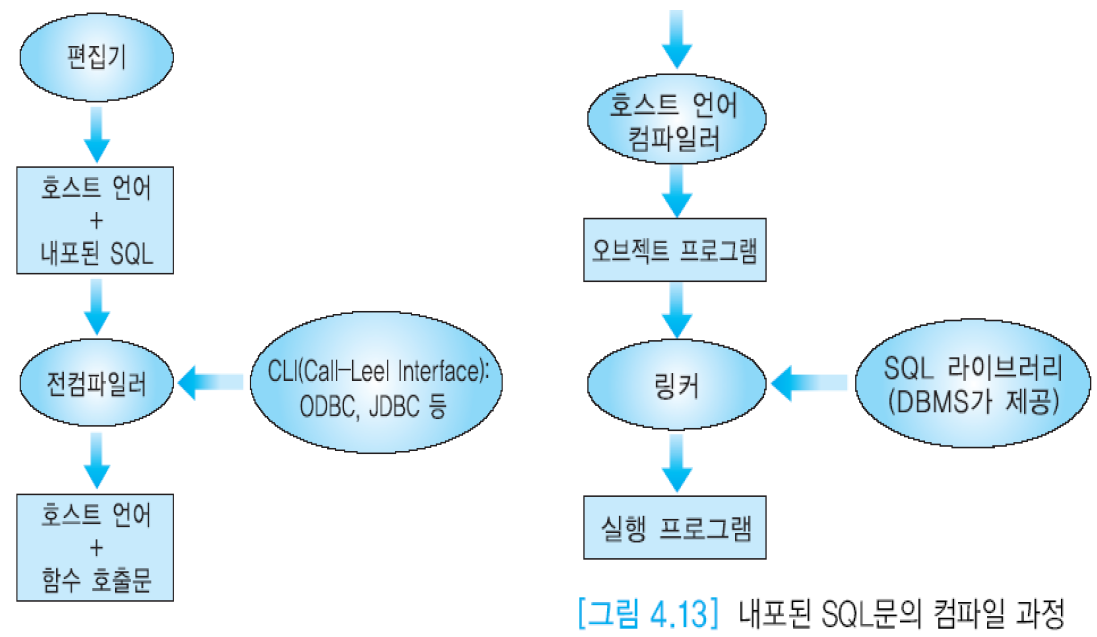
내포된 SQL은 성능측면에서는 좋지만, 전컴파일러(precompiler)가 사용되어 특정 데이터베이스 제품에만 사용 가능하다. 반면, ODBC와 같은 API는 여러 데이터베이스 제품 접근에 사용될 수 있다.
댓글남기기