데이터 베이스 요약 - 1. 데이터베이스 시스템
1. 데이터베이스 시스템
데이터베이스는 조직의 응용 시스템들이 공유해서 사용하는 운영 데이터(operational data)들이 구조적으로 통합된 모임이다.
데이터베이스의 구조는 사용되는 데이터 모델에 의해 결정된다.
데이터는 프로그램과 질의에 의해 정보로 변환된다.
데이터 -> 질의(수강인원은?) -> 정보(10명)
데이터베이스의 특징
- 데이터의 대규모 저장소로서, 여러 사용자에 의해 동시에 사용됨
- 데이터의 중복을 최소화하면서 통합
- 데이터와 그 데이터에 관한 설명(데이터베이스 스키마 또는 메타데이터[metadata])도 포함
- 프로그램과 데이터 간의 독립성을 제공
- 효율적인 접근과 질의를 제공
데이터베이스 관리 시스템(Database Management System, DBMS)은 데이터베이스를 정의하고, 질의어를 지원하고, 리포트를 생성하는 등의 작업을 수행하는 소프트웨어.
1.1. 데이터베이스 시스템 개요
데이터베이스 스키마는 전체적인 데이터베이스 구조를 뜻하며, 자주 변경되지 않음. 데이터베이스의 모든 가능한 상태를 미리 정의함. 상태는 특정 시점의 데이터베이스의 내용을 의미하며, 시간이 지남에 따라 계속 바뀜.
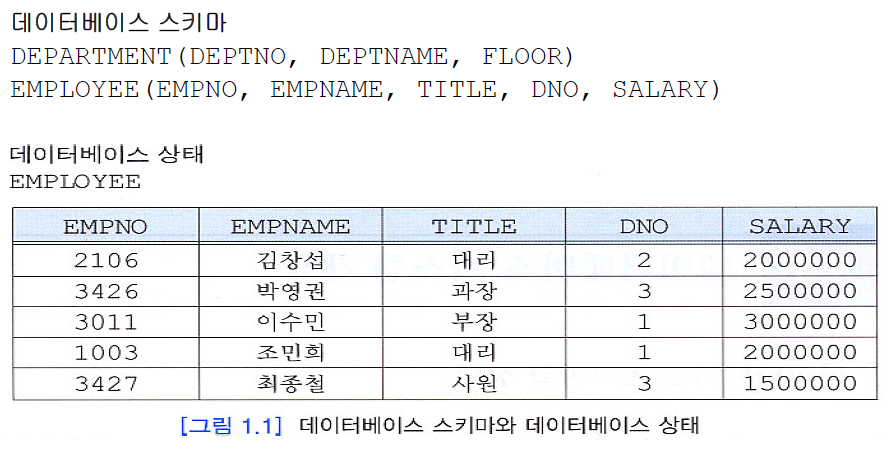
데이터베이스는 시스템 카탈로그(또는 데이터 사전)와 저장된 데이터베이스로 구분할 수 있음. 시스템 카탈로그(system catalog)는 저장된 데이터베이스의 스키마 정보를 유지.
DBMS는 데이터베이스를 생성하고, 데이터를 질의/수정하고, 고장이나 권한이 없는 사용자로부터 데이터를 보호하며, 동시에 여러 사용자가 데이터베이스에 접근하는 것을 제어하는 소프트웨어. SQL은 여러 DBMS에서 제공되는 사실상의 표준 데이터베이스 언어.
데이터베이스는 디스크와 같은 보조기억 장치에 저장됨.
따라서, DBMS에서 정보를 찾기 위해서는 디스크의 블록들을 주기억 장치로 읽어들여야 하며, DBMS 자체도 주기억 장치에 적재되어 실행되어야 함.
1.2. 파일 시스템 vs DBMS
DBMS 이전의 파일 시스템의 구성요소는 순차적인 레코드들이며, 레코드는 연관된 필드들의 모임. 파일에 접근하는 방식은 응용 프로그램 내에 표현되므로, 데이터에 대한 응용 프로그램의 의존도가 높음.
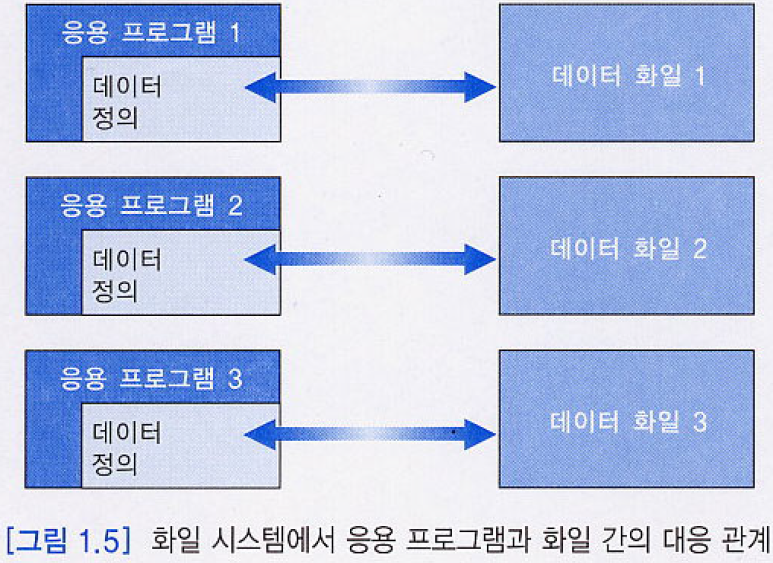

1.3. DBMS 발전 과정
데이터 모델은 데이터베이스의 구조를 기술하는데 사용되는 개념들의 집합(데이터 타입, 데이터 간의 관계 등).
데이터 모델은 사용자에게 내부 저장 방식의 복잡한 사항은 숨기면서 데이터에 대한 직관적인 뷰를 제공하는 동시에, 이들 간의 사상을 제공.
데이터 모델의 분류 예.
(1) 고수준 또는 개념적 데이터 모델(conceptual data model): 사람이 인식하는 것과 유사하게 데이터베이스의 논리적인 구조를 명시. 엔티티-관계(ER: Entity-Relationship) 데이터 모델과 객체 지향 데이터 모델 등.
(2) 표현(구현) 데이터 모델(representation[implementation] data model): 사용자가 이해하는 개념이면서 데이터가 조직되는 방식과 많이 다르지 않음. 계층 데이터 모델, 네트워크 데이터 모델, 관계 데이터 모델(relational data model) 등.
(3) 저수준 또는 물리적인 데이터 모델(physical data model): 데이터베이스에 데이터가 어떻게 저장되는가를 기술. Unifying, ISAM 등.
데이터웨어하우스, 데이터마이닝, OLAP 등 새로운 데이터베이스 응용들이 있으며, 아래 그림과 같이 많은 기능을 제공.
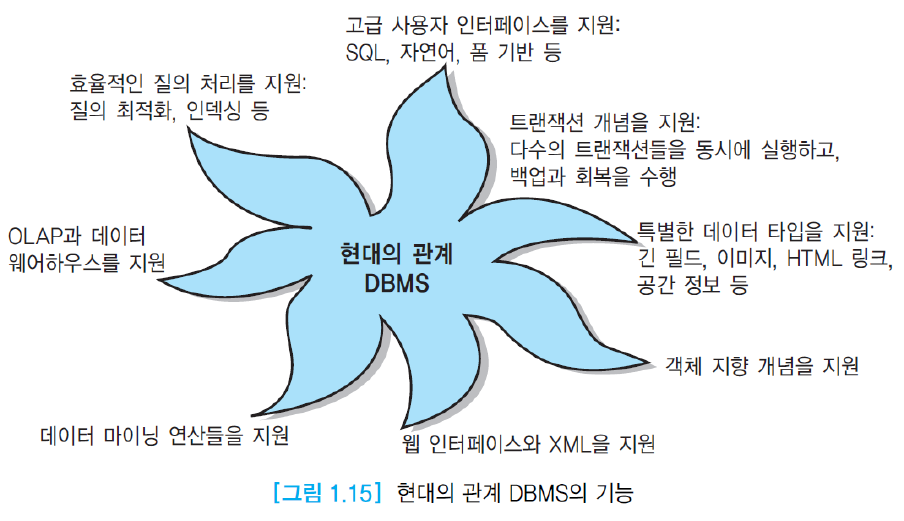
1.4. DBMS 언어
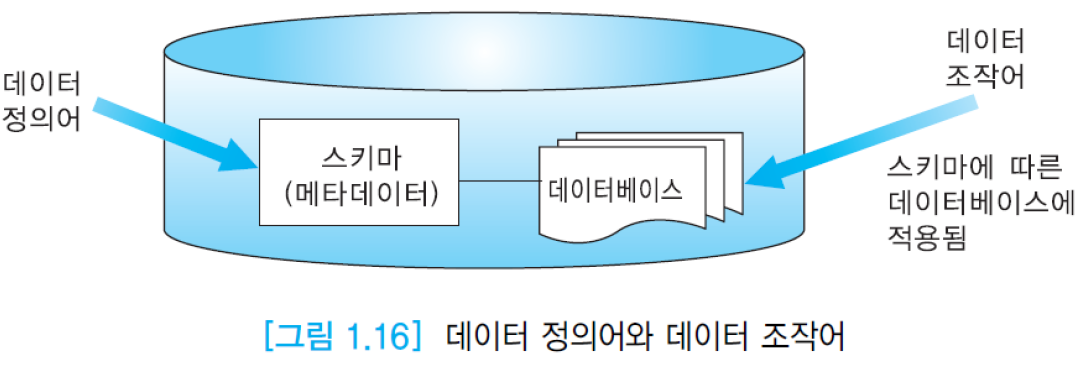
데이터 정의어(DDL, Data Definition Language)를 통해 데이터베이스 스키마를 정의할 수 있다. 스키마에 대한 명세는 시스템 카탈로그에 저장된다. 데이터 모델에서 지원하는 데이터 구조를 생성, 구조의 변경/삭제 등이 가능.
데이터 조작어(DML, Data Manipulation Language)를 통해 데이터를 검색, 수정, 삽입, 삭제 등을 할 수 있다. DBMS에서 사용되는 SQL은 비절차적 언어(non-procedural language)이다. 즉, 사용자는 자신이 원하는것(what)만 명시하고, 어떻게(how) 수행/접근해야 하는지는 DBMS가 결정한다.
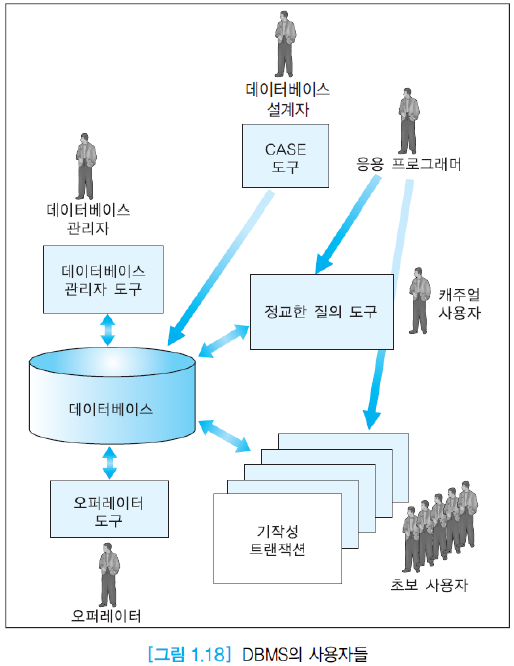
1.5. DBMS 사용자
(1) 데이터베이스 관리자(DBA, Database Administrator)는 조직의 요구를 만족시키기 위해 데이터베이스의 스키마를 생성하고 유지하는 사람/팀. 관리자는 무결성 제약조건, 사용자 역활 관리(권한 부여), 저장 구조 및 물리적 스키마 정의, 백업과 회복, 그리고 표준화 등을 시행한다.
(2) 응용 프로그래머는 데이터베이스 위에서 응용 프로그램이나 인터페이스를 구현한다. 작성된 프로그램은 최종 사용자들이 반복해서 수행하므로 기작성 트랜잭션(canned transaction)이라 불리기도 한다.
(3) 최종 사용자(end user)는 질의, 갱신 또는 보고서 생성 등을 위해 데이터베이스를 사용한다.
(4) 데이터베이스 설계자(database designer)는 CASE 도구들을 이용해서 데이터베이스 설계를 한다. 그리고 데이터베이스의 일관성을 유지하기 위해서 정규화를 수행한다.
(5) 오퍼레이터는 DBMS가 운영되고 있는 컴퓨터 시스템과 전산실을 관리한다.
1.6. ANSI/SPARC 아키텍처와 데이터 독립성
ANSI/SPARC 아키텍처는 DBMS 구현에서 많이 사용되며, 3단계로 이루어짐.
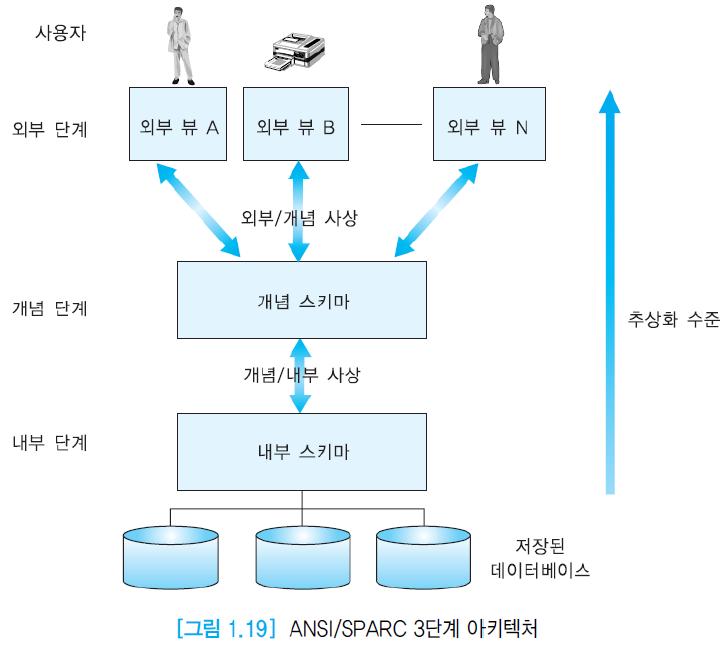
(1) 외부 단계(external level): 각 사용자의 뷰, 여러 부류의 사용자를 위해 동일한 개념 단계에서 서로 다른 뷰가 제공될 수 있음. 일반적으로, 최종 사용자와 응용 프로그래머는 데이터베이스의 일부분에만 관심을 가짐.
(2) 개념 단계(conceptual level): 사용자 공동체의 뷰, 물리적인 구현은 고려하지 않으면서 조직제 전체에 관한 스키마를 포함. 어떤 데이터가 저장되어 있으며, 데이터 간에 어떤 관계가 존재하고, 어떤 무결성 제약조건이 명시되어 있는가를 기술함.
(3) 내부 단계(internal level): 물리적/저장 뷰, 물리적인 데이터 구조에 관한 스키마. 데이터가 어떻게 저장되어 있는가를 기술함. 인덱스, 해싱 등과 같은 접근 경로, 데이터 압축 등을 기술함.
내부 단계 아래는 물리적 단계이며, 이는 DBMS의 지시에 따라 운영체제가 관리함.
DBMS는 세 가지 유형의 스키마 간의 사상을 책임짐.
(1) 외부/개념 사상(external/conceptual mapping)은 외부 단계의 뷰를 사용해서 입력된 사용자의 질의를 개념 단계의 스키마를 사용한 질의로 변환.
(2) 개념/내부 사상(conceptual/internal mapping)은 이를 다시 내부 단계의 스키마로 변환하여 데이터베이스를 접근.
DBMS는 잘 정의되어 데이터 독립성을 제공해야 함. 즉, 상위 단계의 스키마 정의에 영향을 주지 않으면서 어떤 단계의 스키마 정의를 변경할 수 있어야 함. 논리적인 데이터 독립성(logical data independence), 물리적인 데이터 독립성(physical data independence).
1.7. 데이터베이스 시스템 아키텍쳐
데이터베이스 시스템의 모듈들.
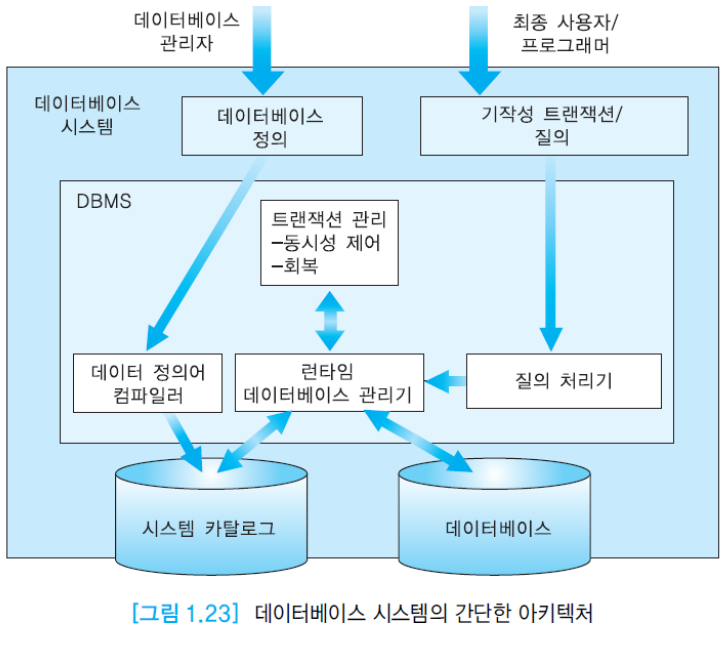
(1) 데이터 정의어 컴파일러(DDL compiler) 모듈: 데이터 정의어를 사용하여 테이블 생성 등을 요청하면, 테이블을 파일 형태로 데이터베이스에 만들고, 이 테이블에 대한 명세를 시스템 카탈로그에 저장.
(2) 질의 처리기(query processor) 모듈: 데이터 조작어를 수행하는 최적의 방법을 찾는 모듈을 통해서 기계어 코드로 번역.
(3) 런타임 데이터베이스 관리기(run-time database manager) 모듈: 디스크에 저장된 데이터베이스를 접근.
(4) 트랜잭션 관리(transaction management) 모듈: 동시성 제어(concurrency control) 모듈, 회복(recovery) 모듈 등을 포함함.
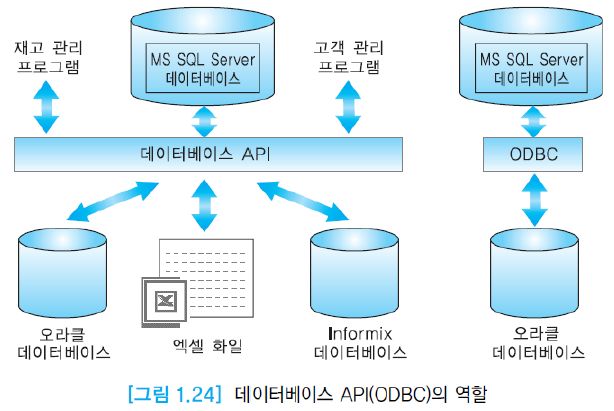
데이터베이스 API(Application Program Interface)는 데이터베이스 접근에 필요한 함수들을 제공. API의 일종인 ODBC(Open Database Connectivity)를 지원하는 DBMS 간에는 서로 상대방의 데이터베이스를 접근할 수 있음.
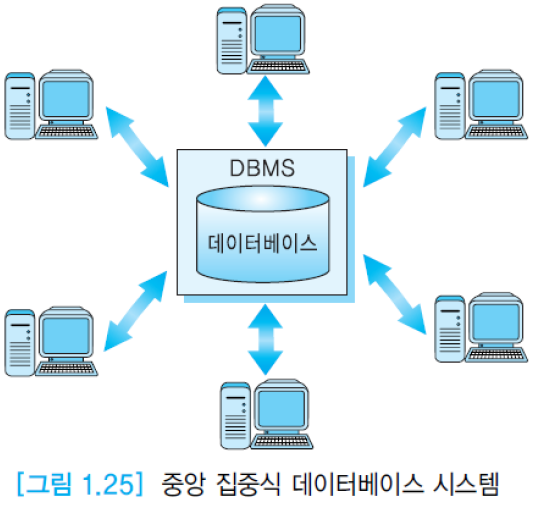
데이터베이스 시스템 운영 방식들.
(1) 중앙 집중식 데이터베이스 시스템(centralized database system): 데이터베이스 시스템이 하나의 컴퓨터에서 운영됨.
(2) 분산 데이터베이스 시스템(distributed database system): 데이터베이스가 여러 곳에 분산되어 있고, 네트워크로 서로 연결됨.
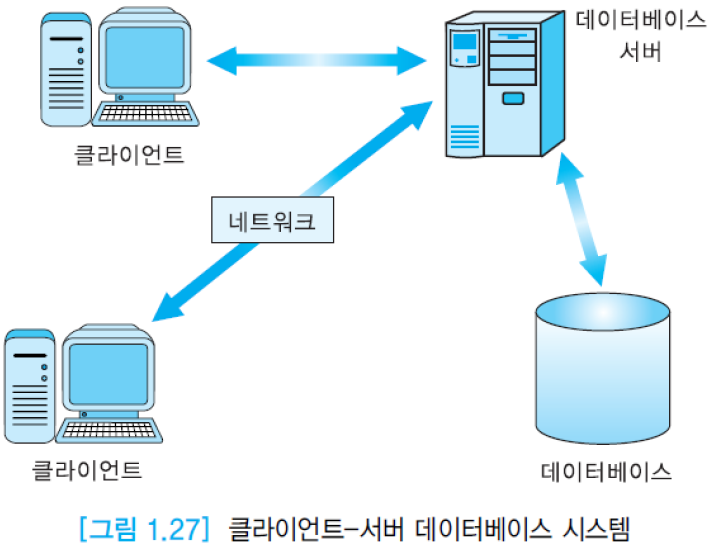
(3) 클라이언트-서버 데이터베이스 시스템(client-server database system): 클라이언트는 사용자 인터페이스를 관리하고, 응용 프로그램들을 수행하고, 데이터베이스 서버에 접근함. 서버는 데이터베이스를 저장하고 DBMS 를 운영함. 또한 클라이언트에서 온 질의를 최적화하고, 권한 검사, 동시성 제어 등을 수행함.
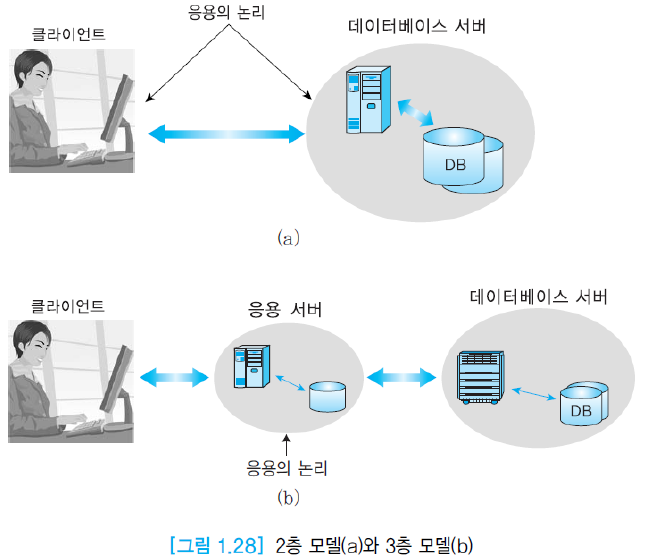
데이터베이스를 사용하는 예전 응용 프로그램은 2층 모델을 사용하였음. 클라이언트의 응용 프로그램이 서버에 있는 데이터베이스 시스템에 직접 접근.
그러나 요즘은 3층 모델을 사용한다. 클라이언트는 단지 프론트-엔드(front-end)처럼 동작하고 서버와 통신만 수행한다. 대신 서버가 데이터베이스 시스템에 접근하여 필요한 정보를 제공한다. 비지니스 로직(business logic)이 서버안에 있어, 어떤 조건 아래서 어떤 동작을 수행할지를 명시한다.
댓글남기기