컴퓨터 네트워킹 요약 - 6. 링크 계층: 링크, 접속망, 랜
6.1. 링크 계층 소개(Introduction to the Link Layer)
링크 계층(2계층) 프로토콜을 실행하는 장치를 노드(node)라고 한다. 호스트, 라우터, 스위치, WiFi AP(access point) 등이 노드가 될 수 있다.
통신 경로상의 인접한 노드들을 연결하는 통신 채널은 링크(link)라고 한다. 한 링크에서 전송 노드는 데이터그램을 링크 계층 프레임(frame)으로 캡슐화 해서 링크로 전송한다.
6.1.1. 링크 계층이 제공하는 서비스(The Services Provided by the Link Layer)
(1) 프레임화(Framing): 네트워크 계층 데이터그램을 링크상으로 전송하기 전에 링크 계층 프레임에 캡슐화한다. 몇 가지 다른 프레임 형식이 있다.
(2) 링크 접속(Link access): 매체 접속 제어(medium access control, MAC) 프로토콜은 링크상으로 프레임을 전송하는 규칙에 대해서 명시한다.
(3) 신뢰적 전달(Reliable delivery): 링크 계층 프로토콜이 신뢰적 전달 서비스를 제공하는 경우 데이터그램은 링크상에서 오류 없이 전달된다. 신뢰적 전달 서비스는 무선 링크처럼 오류율이 높은 링크에서 주로 사용된다. 광섬유, 동축케이블, 다수의 꼬임쌍선 링크와 같은 낮은 비트 오류율을 가진 링크에서는 불필요한 오버헤드가 될 수 있다. 이런 이유로 대다수 유선 링크 계층 프로토콜은 신뢰적 전달 서비스를 제공하지 않는다.
(4) 오류 검출과 정정: 수신 노드의 링크 계층 하드웨어는 전송된 프레임 비트를 0->1 또는 반대로 오인할 수 있다. 이러한 비트 오류는 신호의 약화나 전자기 잡음 때문에 생긴다. 오류 검출은 송신 노드에서 프레임에 오류 검출 비트를 설정하고, 수신 노드가 오류 검사를 수행함으로써 가능해진다.
6.1.2. 링크 계층이 구현되는 위치(Where Is the Link Layer Implemented?)
라우터의 라인 카드에 링크 계층을 구현하는 방법은 4장에서 다루었으므로, 이 장에서는 종단 시스템에서 구현하는 것에 대해서 살펴본다.
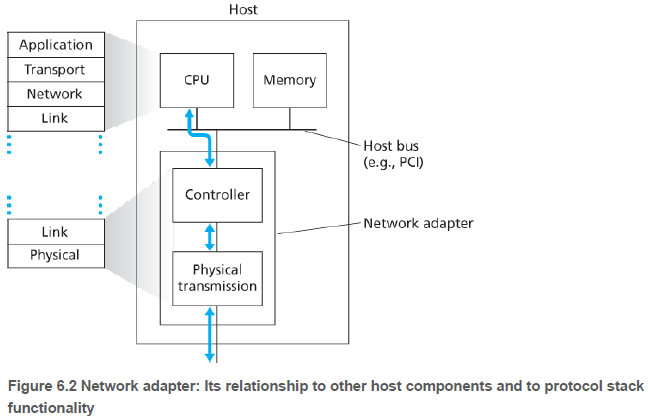
대부분 링크 계층은 네트워크 인터페이스 카드(network interface card, NIC)로 알려진 네트워크 어댑터(network adapter)에 구현된다. 어댑터는 보통 마더보드에 통합되어 있다.
어댑터에는 링크 계층 제어기가 있으며, 제어기는 링크 계층 서비스들(프레임화, 링크 접속 등)의 대다수가 구현되어 있는 특수 용도 칩이다. 링크 계층 제어기의 기능 대부분은 하드웨어로 구현된다.
일부 링크 계층 기능은 호스트 CPU에서 실행되는 소프트웨어에 구현되어 있다. 링크 계층 주소 정보 조립, 제어기 하드웨어의 활성화, 제어기로부터의 인터럽트 등과 같은 기능들은 링크 계층 소프트웨어 구성요소에 구현되어 있다.
6.2. 오류 검출 및 정정 기술(Error-Detection and -Correction Techniques)
비트 오류를 방지하기 위해 송신 노드는 데이터에 오류 검출 및 정정 비트들(error-detection and -correction bits, EDC)을 첨가한다. 데이터와 EDC는 전송 도중 비트가 변경될 수 있다. 수신 노드에서는 수신한 데이터와 EDC로, 수신한 데이터와 데이터가 동일한지 판단한다.
오류 검출 비트를 사용하더라도 미검출된 비트 오류가 있을 수 있다. 더 향상된 오류 검출 및 정정 기술은 더 많은 수의 비트와 많은 계산이 필요하기에, 더 많은 오버헤드를 필요로 한다.
6.2.1. 패리티 검사(Parity Checks)
데이터가 d비트를 갖고 있을 때, 짝수 패리티 기법은 한 비트를 추가하고 그 비트값을 d+1개의 비트들에서 1의 총개수가 짝수가 되도록 선택한다. 홀수 패리티 기법에서는 홀수 개가 되도록 선택한다.
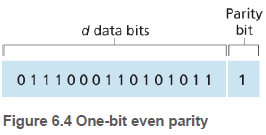
짝수 패리티 기법에서 수신자는 비트 중 1의 개수가 짝수인지 계산한다. 하지만 다중 비트 오류는 잡아낼 수 없다.
보통 오류는 단일 비트로 발생하기 보다는 종종 버스트(burst) 형태로 한꺼번에 몰려서 발생한다. 따라서 좀 더 강력한 오류 검출 기법이 필요하다.
오류 정정 기술에 대한 이해를 돕기 위해 단일 비트 패리티를 간단히 일반화 해보자. 아래 그림은 데이터 d비트를 i개의 행과 j개의 열로 나눈 것이다.
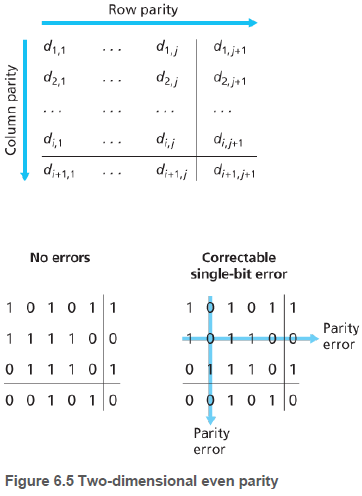
각각의 행과 열에 대해 하나의 패리티값이 계산된다. 이와 같은 2차원 패리티 기법에서는 오류가 생긴 비트를 포함하는 행과 열에 패리티 오류가 생긴다. 따라서 수신자는 단일 비트 오류의 발생을 검출할 수 있을 뿐만 아니라, 오류를 정정할 수도 있다.
오류를 검출 및 정정하는 수신자의 능력을 순방향 오류 정정(forward error correction, FEC)이라고 한다. 네트워크 환경에서 FEC 기술은 3장의 링크 계층 ARQ 기술과 함께 사용될 수도 있다. 수신자가 즉각적인 오류 정정을 할 수 있기에 재전송 횟수를 줄일 수 있고, 송신자가 NAK 패킷을 받고 재전송된 패킷이 수신자로 되돌아가는 왕복 전파 지연 시간을 기다릴 필요가 없다.
6.2.2. 체크섬 방법(Checksumming Methods)
체크섬 기술에서는 데이터를 구성하는 d비트들을 k비트의 정수처럼 다룬다. 간단한 체크섬 방법 중 하나는 이들 k비트 정수들을 더해서 그 결과값을 오류 검출 비트로 사용하는 것이다. 3.3절에서 설명했듯이, 인터넷 체크섬(Internet Checksum)에서 이 방법을 사용한다.
데이터의 바이트를 16비트 정수 단위로 보고, 이를 전부 더한다. 더한 값의 1의 보수가 체크섬이 되며, 이것을 세그먼트 헤더에 넣는다. 수신자는 체크섬을 포함한 데이터 합의 1의 보수를 취한 후, 그 결과가 모두 1인 비트로 구성되어 있는지 확인한다.
트랜스포트 계층은 일반적으로 호스트의 운영체제의 일부로서 소프트웨어로 구현된다. 오류 검출이 소프트웨어로 구현되므로 체크섬처럼 간단하고 빠른 기법이 사용된다.
반면에, 링크 계층에서의 오류 검출은 어댑터안의 전용 하드웨어로 구현되므로 더 복잡한 CRC 연산을 빨리 수행할 수 있다.
6.2.3. 순환중복검사(Cyclic Redundancy Check, CRC)
네트워크에서 널리 사용되는 오류 검출 기술은 순환중복검사 코드이다. CRC 코드는 다항식 코드(polynomial code)로도 알려져있다. 전송되는 비트열에 있는 0과 1값을 계수로 갖는 다항식처럼 비트열을 생각할 수 있고, 비트열에 적용되는 연산을 다항식 연산으로 이해하는 것이 가능하기 때문이다.
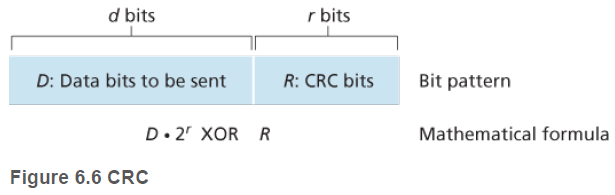
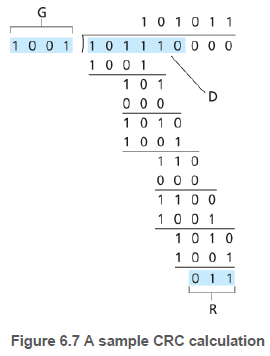
CRC 코드는 먼저 송신자와 수신자가 G로 표기되는 생성자(generator)로 알려진 r+1비트 패턴에 대해서 합의한다. 주어진 데이터 D에 대해 송신자는 r개의 추가 비트 R을 선택해서 D뒤에 덧붙인다. 수신자는 d+r개의 수신 비트를 G로 나눈다. 만일 나머지가 0이 아니면 오류가 발생한 것이다.
모든 CRC 검사는 덧셈의 올림(carry)이나 뺄셈의 빌림(borrow)이 없는 모듈로-2 연산을 사용한다. 이것은 덧셈과 뺄셈이 동일함을 뜻하며, 피연산자를 비트별로 XOR한 것과 같다.
1011 XOR 0101 = 1110
1001 XOR 1101 = 0100
// 위와 유사한 결과를 얻는다.
1011 - 0101 = 1110
1001 - 1101 = 0100
일반 이진 연산에서 처럼, 2k을 곱하는 것은 비트 패턴을 k개의 위치만큼 왼쪽으로 이동하는 것이다. 따라서 주어진 D와 R에 대해, D * 2k XOR R은 위의 그림처럼 d+r비트 패턴을 만든다.
송신자가 R을 계산하는 방법은 다음과 같다. 먼저 다음과 같은 식을 만족하는 n이 있도록 하는 R을 구한다.
D * 2k XOR R = n * G
즉, D * 2k XOR R 을 나머지 없이 G로 나눌 수 있도록 R을 선택해야 한다. 위 식 양쪽에 R을 XOR하면 다음과 같다.
D * 2k = n * G XOR R
두 번째 식은 D * 2k 을 G로 나누면 나머지가 R이 되는 것을 뜻한다. 즉, R을 다음처럼 계산할 수 있다.
R = D * 2k / G 의 나머지
아래 그림은 D=101110, d=6, G=1001, r=3인 경우에 대한 예시이다. 이 경우 전송되는 9개의 비트는 101110011이다.
국제 표준으로 8비트, 12비트, 16비트, 32비트의 생성자 G가 정의되어 있다. 다수의 링크 계층 IEEE 프로토콜에서 채택한 CRC-32 32비트 표준은 다음과 같은 생성자를 사용한다.
GCRC-32=100000100110000010001110110110111
각 CRC 표준은 r개 이하의 연속적인 비트 오류를 모두 검출할 수 있다. 또한 r+1비트보다 큰 길이의 버스트 오류는 1-0.5r의 확률로 검출된다. 그리고 임의의 홀수개의 비트 오류를 검출할 수 있다.
6.3. 다중 접속 링크와 프로토콜(Multiple Access Links and Protocols)
링크 계층 채널에는 두 종류가 있다. 점대점 링크(point-to-point lint)는 링크의 한쪽 끝에 한 송신자와 링크의 다른 쪽 끝에 한 수신자가 있다. PPP(point-to-point protocol)와 HDLC(high-level data link control) 등이 이에 속한다.
브로드캐스크 링크(broadcast link)는 동일한 하나의 공유된 브로드캐스트 채널에 다수의 송신 노드 및 수신 노드들이 연결된다. 이더넷과 무선 랜 등이 이에 속한다.
이 절에서는 다중 접속 문제(multiple access problem), 즉 다수의 송수신 노드들의 공유되는 브로드캐스트 채널로의 접속을 조정하는 문제에 대해 살펴본다. 컴퓨터 네트워크에는 공유되는 브로드캐스트 채널로 보내는 노드들의 전송을 조정하기 위한 다중 접속 프로토콜(multiple access protocol)이 있다.
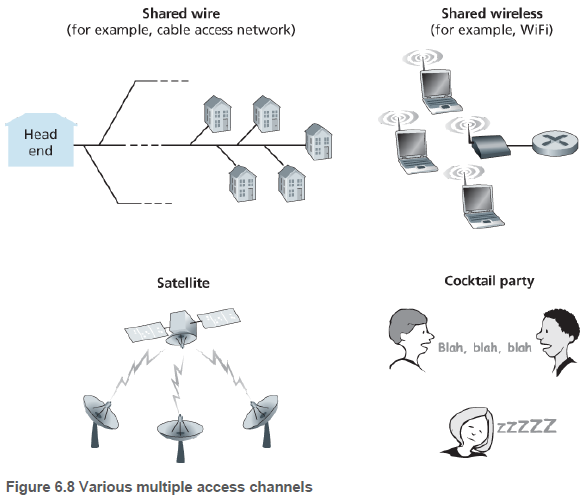
모든 노드들이 프레임을 전송할 수 있으므로, 2개 이상의 노드가 동시에 프레임을 전송할 수 있다. 이런 경우, 모든 노드는 동시에 여러 개의 프레임을 받게 되고, 전송된 프레임들이 각 수신자에서 충돌(collide)한다.
충돌에 관련된 프레임은 손실되며, 브로드캐스트 채널은 충돌 기간만큼 낭비된다. 따라서 전송을 조정할 필요가 있고, 이는 다중 접속 프로토콜의 책임이다.
6.3.1. 채널 분할 프로토콜(Channel Partitioning Protocols)
채널을 공유하는 모든 노드가 브로드캐스트 채널의 대역폭을 분할할 수 있게 해주는 기술을 세 가지가 있다. 여기선 채널이 N개 노드를 지원하고 채널 전송률이 R bps라고 하자.
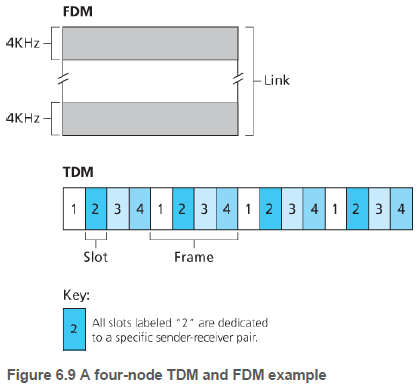
(1) 시분할 다중화(time division multiplexing, TDM)은 시간을 시간 프레임(time frame)으로 나누고, 각 시간 프레임을 N개의 시간 슬롯(time slot)으로 나눈다. 그 후에 각 시간 슬롯은 N개 노드에게 각각 할당된다. 노드는 TDM 프레임에서 자신에게 할당된 시간 슬롯 동안 비트들을 전송한다.
TDM은 충돌을 제거할 수 있고 아주 공정하다. 그러나 전송하려고 하는 노드가 단 하나인 경우에도 노드 전송률이 평균 R/N으로 제한되고, 항상 자신의 차례를 기다려야 한다.
(2) 주파수분할 다중화(frequencydivision multiplexing, FDM)은 R bps의 채널을 다른 주파수(각 R/N의 대역폭을 갖는)로 나눠서 각 주파수를 N개 노드중 하나에게 할당한다. FDM도 충돌을 피하고 대역폭을 균등하게 분할하지만, TDM가 같이 전송하려는 노드가 단 하나일지라도 노드는 R/N의 대역폭으로 한정된다.
(3) (7장 내용) 코드 분할 다중 접속(code division multiple access, CDMA)은 다른 코드를 각 노드에게 할당한다. 그리고 노드는 데이터를 자신의 유일한 코드로 인코딩한다. CDMA 네트워크에서 코드들을 신중하게 선택하면 여러 노드들이 동시에 전송할 수 있고, 다른 노드들에 의해서 전송이 간섭되더라도 각 수신자들이 송신자의 인코딩된 데이터 비트를 수신할 수 있다(수신자는 송신자의 코드를 안다고 가정).
6.3.2. 랜덤 접속 프로토콜(Random Access Protocols)
랜덤 접속 프로토콜에서 전송 노드는 항상 채널의 최대 전송률인 R bps로 전송한다. 충돌이 생기면 충돌과 관련된 각 노드는 프레임이 충돌 없이 전송될 때까지 자신의 프레임을 계속 재전송한다. 단, 프레임을 재전송하기 전에 랜덤 지연 시간 동안 기다린다.
6.3.2.1. 슬롯 알로하(Slotted ALOHA)
슬롯 알로하에 대한 설명에서는 다음과 같이 가정한다.
- 모든 프레임은 L 비트로 구성된다.
- 시간은 L/R초의 슬롯들로 나뉜다(즉, 한 슬롯은 한 프레임 전송에 걸리는 시간과 같다).
- 노드는 슬롯의 시작점에서만 프레임을 전송한다.
- 각 노드는 언제 슬롯이 시작하는지 알 수 있도록 동기화되어 있다.
- 한 슬롯에서 프레임이 출동하면, 모든 노드는 그 슬롯이 끝나기 전에 충돌 발생을 알게 된다.
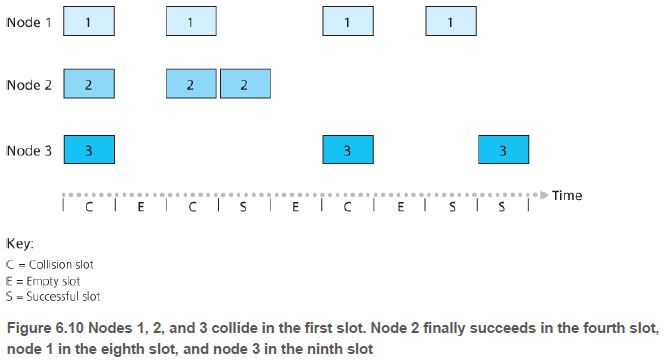
p를 확률(0과 1사이의 숫자)이라 하자, 각 노드에서 슬롯 알로하는 다음과 같이 동작한다.
- 노드는 전송할 프레임이 있으면, 다음 슬롯을 기다리고 그 슬롯에 프레임을 전송한다.
- 만약 충돌하지 않으면, 프레임을 재전송할 필요가 없다.
- 만약 충돌하면, 프레임이 충돌 없이 전송될 때까지 확률 p로 해당 프레임을 다음 슬롯들에서 재전송한다.
슬롯 알로하는 전송하려는 노드가 하나일 때 잘 동작한다. 그러나 여러 노드가 전송하려고 하면 충돌로 인해 슬롯이 낭비되고, 확률적인 전송 정책 때문에 일부 슬롯이 쓰이지 않을 수 있다. 이 프로토콜의 수학적 최대 효율은 37% 이다.
6.3.2.2. 알로하(ALOHA)
알로하에서는 슬롯 개념없이 프레임 충돌 시, 확률 p로 재전송 혹은 프레임 전송 시간동안 기다린다. 노드는 기다리고 나서 프레임을 확률 p로 전송하거나 아니면 확률 1-p로 또 프레임 시간동안 기다린다. 이는 슬롯 알로하의 절반의 효율을 가진다.
6.3.2.3. Carrier Sense Multiple Access (CSMA)
CSMA와 CSMA/CD(CSMA with collision detection) 프로토콜은 아래 두 규칙을 포함한다.
(1) 캐리어 감지(carrier sensing): 다른 노드가 프레임을 채널로 전송하고 있을 때, 노드는 짧은 시간동안 전송이 일어나지 않을 때까지 기다린 후, 전송을 시작한다.
(2) 충돌 검출(collision detection): 다른 노드가 방해(interfering) 프레임을 전송하고 있음을 검출하면, 자신의 전송을 중단하고 랜덤 시간 동안 기다린 후 유휴 시 감지 및 전송 과정(sense-and-transmit-when-idle cycle)을 반복한다.
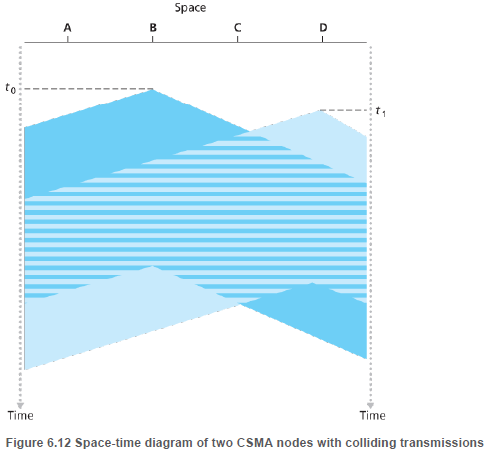
아래 그림은 브로드캐스트 채널의 종단간의 채널 전파 지연(channel propagation delay)를 보여준다. 시간 t0에서 노드 B가 전송을 시작한다.
B가 전송한 비트들이 브로드캐스트 매체를 따라 양방향으로 전파되는데에 0보다 큰 시간이 필요하다. 시간 t1에서 B가 전송한 비트들이 D에 도달하지 못하여, D는 채널이 사용되지 않은 것으로 감지한다. 따라서 D가 비트를 전송하고 충돌이 일어난다.
6.3.2.4. Carrier Sense Multiple Access with Collision Dection (CSMA/CD)
CSMA/CD는 충돌을 감지하면 자신의 전송을 취소한다.
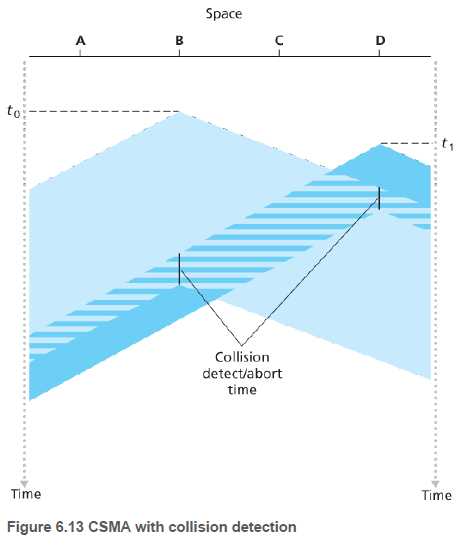
CSMA/CD 프로토콜은 다음과 같이 동작한다.
(1) 어댑터는 데이터그램을 프레임으로 만든 후, 자신의 버퍼에 저장한다.
(2) 어댑터는 채널이 유휴(idle)한 것을 감지하면(채널로부터 어댑터로 들어오는 신호 에너지가 없으면) 프레임 전송을 시작한다. 만일 채널이 바쁜 것을 감지하면, 어떤 신호 에너지도 감지되지 않을 때까지 기다렸다가 프레임을 전송한다.
(3) 어댑터는 전송하는 동안 브로드캐스트 채널을 사용하는 다른 어댑터로부터의 신호 에너지가 있는지 감시한다.
(4) 전송 도중에 다른 어댑터로부터의 신호 에너지를 감지하면, 자신의 프레임 전송을 취소한다.
(5) 어댑터는 전송을 취소한 후 임의의 랜덤 시간만큼 기다린 후 단계 2로 돌아간다.
충돌한 수가 작으면 랜덤 시간을 작게하고, 충돌 노드가 많으면 랜덤 시간을 크게 하는 것이 좋다. 주로, 이진 지수적 백오프(binary exponential backoff) 알고리즘이 사용된다.
충돌을 n번 경험한 프레임을 전송할 때, 노드는 {0, 1, 2, …, 2n} 중에서 랜덤하게 K값을 선택한다. 이더넷의 경우, 노드가 실제로 기다리는 시간은 K * 512비트 시간(이더넷으로 512비트를 전송하는 데 필요한 시간에 K를 곱한 시간)이 되며, n의 최댓값은 10이다.
6.3.2.5. CSMA/CD의 효율(CSMA/CD Efficiency)
dprop는 신호 에너지가 임의의 두 어댑터 사이에서 전파되는 데 걸리는 최대 시간, dtrans는 최대 크기의 이더넷 프레임을 전송하는 데 걸리는 시간이라 하자.
아래의 근사식을 사용하면 dprop이 0에 가깝거나, dtrans이 매우 크면 효율이 1에 근접한다. 전파 지연이 0이면 충돌 노드들이 채널을 낭비하지 않고 즉시 취소하는 것이고, 전송 시간이 매우 크다는 것은 프레임이 채널을 한 번 차지하면 아주 오랫동안 채널을 사용한다는 것이다.
효율 = 1 / (1 + 5 * dprop / dtrans)
6.3.3. 순번 프로토콜(Taking-Turns Protocols)
알로하와 CSMA 프로토콜에서는 단 하나의 노드만이 전송하려고 할 때, 그 노드는 R bps의 처리율을 가진다. 순번 프로토콜은 이에 더해, M개의 노드가 전송하려고 할 때, 각 노드가 거의 R/M bps의 처리율을 가진다.
많은 순번 프로토콜이 있지만, 여기서는 중요한 프로토콜 두 가지만을 살펴본다. (1) 폴링 프로토콜(polling protocol)은 노드 중 하나를 마스터 노드로 지정한다. 마스터 노드는 각 노드를 라운드 로빈 방식으로 폴링한다. 노드 1에게 노드 1이 최대로 보낼 수 있는 프레임 수를 알려주고, 노드 1이 프레임들을 보낸 다음에는 노드 2, … 순으로 알려준다.
이 프로토콜의 단점에는 폴링 지연(노드가 전송할 수 있을음 알리는 데 걸리는 시간)이 있으며, 마스터 노드가 고장 나면 전체 채널이 동작하지 못하게 되는 점도 있다. 블루투스 프로토콜 등이 이에 속한다.
(2) 토큰 전달 프로토콜(token-passing protocol)에서는 토큰이라고 알려진 작은 특수 목적 프레임이 정해진 순서대로 노드 간에 전달된다. 예를 들어, 노드 1은 노드 2에게, 노드 2는 노드 3에게 전송한다. 노드가 토큰을 수신하면, 전송할 프레임이 있을 때만 토큰을 붙잡고, 프레임을 최대 개수까지 전송한 뒤 토큰을 다음 노드로 전달한다.
이 방식에서는 노드 하나가 실패하면 전체 채널이 동작하지 않는다. 또 노드가 잘못해서 토큰을 놓아주지 않으면, 토큰이 다시 돌 수 있도록 하는 회복 절차가 실행되어야만 한다.
6.3.4. DOCSIS: 케이블 인터넷 접속을 위한 링크 계층 프로토콜(DOCSIS: The Link-Layer Protocol for Cable Internet Access)
케이블 접속망은 채널 분할, 랜덤 접속, 순번 프로토콜을 모두 사용한다.
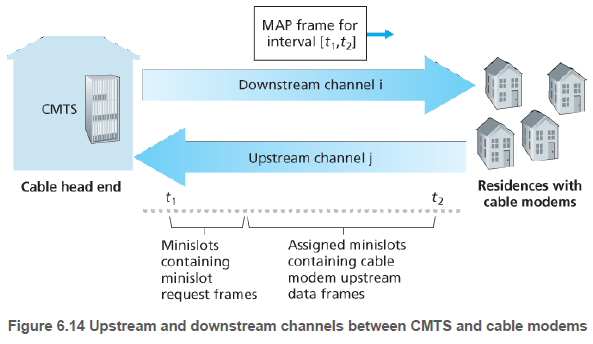
(1.2.1절) 케이블 접속망에서는 보통 수천 개의 자택내 케이블 모델이 케이블망 중계소에 있는 케이블 모뎀 종단 시스템(CMTS)에 연결되어 있다. DOCSIS(Data-Over-Cable Service Interface Specifications)은 케이블 접속망의 구조와 프로토콜들을 정의한다.
DOCSIS는 하향(downstream; CMTS에서 모뎀으로) 및 상향(upstream; 모뎀에서 CMTS으로) 망 세그먼트들을(segments) 다수의 주파수 채널로 나누기 위해 FDM을 사용한다. 하향의 경우 하향 채널로 전송하는 CMTS가 하나뿐이기 때문에 다중 접속 문제는 발생하지 않는다. 그러나 상향의 경우 다수의 케이블 모뎀이 CMTS로 동일한 상향 채널(주파수)을 공유하고, 따라서 충돌이 발생할 수 있다.
이에 대한 해결책으로, 상향 채널은 시간 간격(TDM처럼)으로 나뉘어져 있다. 각 시간 간격은 케이블 모뎀이 CMTS로 전송할 수 있는 일련의 미니 슬롯(minislot)들로 구성되어 있다. CMTS는 하향 채널상으로 MAP 메세지로 알려진 제어 메세지를 보냄으로써 어떤 케이블 모뎀이 MAP 메세지에서 명시한 시간 간격 동안 어떤 미니 슬롯으로 전송할 수 있는지 알려 준다.
케이블 모델은 전송할 데이터가 있음을, 이 용도로 할당된 특정 미니 슬롯들을 사용하여 CMTS에게 알린다. 미니 슬롯 요청은 랜덤 접속 방식으로 전송되기 때문에 충돌이 발생할 수 있다. 케이블 모뎀은 충돌 검출을 하지 않고, 응답을 받지 못한 것을 충돌 발생으로 추정한다.
6.4. 스위치 근거리 네트워크(Switched Local Area Networks)
스위치는 링크 계층에서 동작하기 때문에, 링크 계층 프레임을 교환한다. 네트워크 계층 주소를 인식하지 않으며, 경로를 결정하는 데 라우팅 알고리즘을 사용하지 않는다. 스위치 네트워크에서는 프레임을 전달하기 위해 IP 주소가 아닌 링크 계층 주소를 사용한다.
6.4.1. 링크 계층 주소체계와 ARP(Link-Layer Addressing and ARP)
호스트와 라우터는 링크 계층 주소, 네트워크 계층 주소 둘 다 가진다.
6.4.1.1. MAC 주소(MAC Addresses)
실제로 링크 계층 주소를 가진 것은 어댑터이다. 그러나 스위치는 호스트나 라우터를 연결해주는 인터페이스에 주소를 할당 받지 않는다. 그 이유는 스위치는 데이터그램을 전달하는 일을 하기 때문이다. 호스트나 라우터는 중간에 거쳐 가는 스위치의 주소를 프레임에 명시하지 않는다.
링크 계층 주소는 랜 주소(LAN address) 물리 주소(physical address) 또는 MAC 주소(MAC address)라고도 알려져있다. 대부분의 랜(이더넷과 무선 랜 등)의 경우 MAC 주소는 길이가 6바이트이다. 주로 16진수로 표기되며, 주소의 각 바이트는 2개의 16진수로 표시된다(예: 1A-23-F9-CD-06-9B).
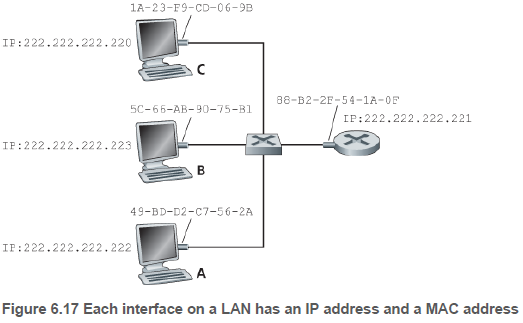
IEEE가 MAC 주소 공간을 관리하기 때문에 어떤 어댑터도 동일한 주소를 갖지 않는다. 그리고 IP 주소는 호스트가 이동하면(예: 다른 지역으로 이사) 변경되지만, MAC 주소는 변경되지 않는다.
어댑터가 프레임을 목적지 어댑터로 전송할 때, 어댑터는 프레임에 목적지 MAC 주소를 넣고, 그 프레임을 랜상으로 전송한다. 스위치는 종종 프레임을 자신의 모든 인터페이스로 브로드캐스트한다. 따라서 어댑터는 자신을 목적지로 하지 않은 프레임을 수신할 수도 있다. 프레임을 수신한 어댑터는 MAC 주소를 검사하고, 자신의 MAC 주소와 일치하지 않으면 이를 폐기한다.
어떤 송신 어댑터는 랜상의 모든 어댑터가 자신이 전송한 프레임을 수신하기를 원한다. 이 경우 프레임의 목적지 주소에 특수한 MAC 브로드캐스트 주소를 넣는다. 6바이트의 주소를 사용하는 랜에서 브로드캐스트 주소는 48개의 1로 된 비트열이다(FF-FF-FF-FF-FF-FF).
6.4.1.2. Address Resolution Protocol (ARP)
네트워크 계층 주소와 링크 계층 주소 사이에 변환은 ARP에서 이루어진다. ARP는 동일한 서브넷상에 있는 호스트나 라우터의 인터페이스의 IP 주소를 MAC 주소로 변환해준다.
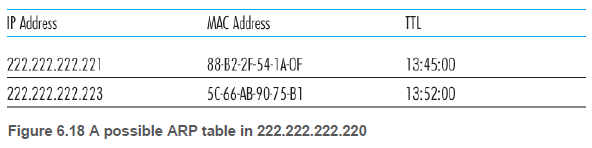
각 호스트와 라우터는 자신의 메모리에 ARP 테이블을 갖고 있다. 이 테이블은 IP 주소와 MAC 주소 간의 매핑 정보를 포함한다. 또한 각 매핑이 언제 삭제되는지를 나타내는 TTL값을 포함한다.
ARP 테이블에 목적지 노드에 대한 항목이 있으면 바로 변환할 수 있다. 하지만 없을 경우, 항목을 추가해야 한다.
이를 위해 송신 노드는 ARP 프로토콜을 사용한다. 먼저 송신 노드는 특수한 ARP 패킷을 구성한다. ARP 패킷은 MAC 주소와 송신/수신 IP주소를 포함하는 필드를 갖고 있으며, 질의/응답 패킷 모두 같은 형식을 가진다. ARP 질의 패킷은 IP 주소에 대응되는 MAC 주소를 결정하기 위해 서브넷의 모든 호스트와 라우터들에게 질의하는 것이다.
송신 노드가 ARP 질의 패킷을 MAC 브로드캐스트 주소를 사용하여 전송하면, IP 주소에 해당하는 호스트/라우터가 MAC 주소를 포함하여 응답 ARP 패킷을 돌려준다. 그러면 송신 노드는 자신의 ARP 테이블을 갱신한다.
6.4.1.3. 서브넷에 없는 노드로의 데이터그램 전송(Sending a Datagram off the Subnet)
서브넷에 없는(즉, 라우터를 지나서 다른 서브넷) 호스트에게 데이터그램을 전송하는 상황을 살펴보자. 우선, 라우터는 인터페이스마다 IP 주소, ARP 모듈, 어댑터를 가지는 것을 기억하자.
송신 어댑터가 자신의 서브넷에서 바로 목적지 MAC 주소를 사용한다면, 서브넷에서 어떤 어댑터도 데이터그램을 받아주지 않을 것이다. 따라서 송신 어댑터는 최종 목적지로의 경로상에 있는 첫 홉(first-hop) 라우터의 IP 주소로 데이터그램을 전송한다. 그러면 라우터는 포워딩 테이블 및 ARP 테이블을 사용하여 데이터그램을 목적지로 전달한다.
6.4.2. 이더넷(Ethernet)
인터넷이 글로벌 네트워킹에 대한 것이라면, 이더넷은 근거리 네트워킹에 대한 것이다. 1990년대 후반경에 대부분의 회사와 대학에서는 랜을 허브(hub) 기반의 스타 토폴로지를 사용하는 이더넷으로 대체하였다.
허브는 프레임이 아닌 각 비트에 대한 처리를 하는 물리 계층 장치이다. 비트가 인터페이스에 도착하면, 허브는 이 비트를 재생하고 에너지 세기를 증가시킨 후 다른 모든 인터페이스로 전송한다.
2000년 초반에 이더넷은 여전히 스타 토폴로지를 사용했지만, 중앙의 허브가 스위치(switch)로 대체되었다. 당분간 스위치를 “충돌 없는” 장치일 뿐만 아니라 전달 패킷 스위치라는 정도로 이해하자. 스위치는 3계층까지 동작하는 라우터와 달리 2계층까지만 동작한다.
6.4.2.1. 이더넷 프레임 구조(Ethernet Frame Structure)
송신 어댑터는 IP 데이터그램을 이더넷 프레임에 캡슐화하고 그 프레임을 물리 계층으로 전달한다. 수신 어댑터는 그 프레임을 물리 계층으로부터 받아서 IP 데이터그램을 추출한 후에 그 IP 데이터그램을 네트워크 계층으로 전달한다.

이와 관련하여, 이더넷의 프레임 6개 필드는 다음과 같다. (1) 데이터 필드: 이 필드는 IP 데이터그램을 운반한다. 이더넷의 최대 전송 단위(MTU)는 1,500바이트이다. 이보다 클 경우 4.3.2절의 단편화가 필요하다.
데이터 필드의 최소 크기는 46바이트이다. 이보다 작으면 데이터 필드를 채워서 46바이트로 만들어야 한다. 그러면 네트워크 계층은 IP 데이터그램 헤더에 있는 길이 필드를 사용하여 임의로 채운 부분을 제거한다.
(2) 목적지 주소: 목적지 어댑터의 MAC 주소를 포함한다. 목적지 어댑터는 자신의 MAC 주소 혹은 MAC 브로드캐스트 주소인 프레임만 수신하며, 그 외의 프레임은 폐기한다.
(3) 출발지 주소: 프레임을 랜으로 전송하는 어댑터의 MAC주소이다.
(4) 타입 필드: 이더넷으로 하여금 네트워크 계층 프로토콜을 다중화하도록 허용한다. 호스트가 IP 이외의 다른 네트워크 계층 프로토콜을 사용할 수도 있다.
이더넷 프레임이 목적지 어댑터에 도착하면, 어댑터는 어떤 네트워크 계층 프로토콜로 데이터 필드의 내용을 전달해야 할지 구분할 필요가 있다. 예를 들어, ARP 프로토콜은 자신만의 타입 번호를 갖고 있으며, ARP 패킷은 ARP 프로토콜로 역다중화된다.
(5) 순환중복검사(CRC): 목적지 어댑터는 CRC를 통해 프레임에 오류가 생겼는지 검출한다.
(6) 프리앰블(Preamble): 이더넷 프레임은 8바이트의 프리앰블 필드로 시작한다. 프리앰블의 첫 7바이트는 10101010 값을 가진다. 마지막 바이트는 10101011이다.
프리앰블의 첫 7바이트는 수신 어댑터를 깨우고, 수신자의 클록을 송신자의 클록에 동기화시키는 역활을 한다. 이런 일은 송신 어댑터가 완벽할 수 없으므로 프레임을 목적지 속도에 맞게 정확하게 전송할 수 없기 때문에 필요하다.
즉, 목표 속도에서 어느 정도 벗어날 수 있으며, 이 정도는 다른 어댑터들에게 미리 알려져 있지 않다. 따라서 수신 어댑터는 프리앰블의 첫 7바이트에 있는 비트들에 맞춤으로써 송신 어댑터의 클록에 맞출 수 있다.
모든 이더넷 기술은 네트워크 계층에 비연결형 서비스(connectionless service)를 제공한다. 즉, 어댑터끼리 핸드셰이킹하지 않고 프레임을 전송한다.
이더넷 기술은 네트워크 계층에게 비신뢰적인 서비스를 제공한다. 예를 들어, 수신 어댑터가 CRC를 통해 프레임을 검사하지만, 프레임이 CRC 검사를 통과했는지 못했는지를 알리지 않는다. 따라서 네트워크 계층으로 전달되는 데이터그램들 중에 손실된 데이터그램이 있을 수도 있다.
목적지 애플리케이션이 손실된 데이터그램을 알 수 있는 방법은, 애플리케이션이 TCP 또는 UDP를 사용하는지에 달려 있다.
6.4.2.2. 이더넷 기술(Ethernet Technologies)
이더넷은 다양한 종류가 있으며, 10BASE-T, 10GBASE-T 등과 같은 약어로 표현된다. 이더넷은 링크 계층과 물리 계층 모두에 대한 명세이며, 동축케이블, 구리선, 광섬유와 같은 다양항 물리 매체상으로 전달된다.
1990년대 중반에 이더넷은 100 Mbps로 표준화되었다. 초기 이더넷 MAAC 프로토콜과 프레임 형식은 그대로 유지되었고 구리선과 광섬유에 대해 더 고속의 물리 계층이 정의되었다. 100 Mbps 이더넷은 꼬임쌍선의 경우 100m, 광섬유의 경우 수 Km로 거리를제 한하며, 다른 건물에 있는 이더넷 스위치 간 연결을 허용한다.
기가바이트 이더넷은 이더넷 표준을 확장한 것이다. IEEE 802.3z라고 알려진 기가비트 이더넷의 표준은 다음과 같다.
(1) 표준 이더넷 프레임 형식을 사용하며, 10/100BASE-T 기술과 하위 호환성을 가져 현재 구축되어 있는 이더넷 장비와 통합될 수 있다.
(2) 공유되는 브로드캐스트 채널뿐만 아니라 점대점 링크도 허용한다. 브로드캐스트 채널의 경우는 허브를 사용하고, 점대점 링크는 스위치를 사용한다. 기가비트 이더넷의 전문용어로 허브는 버퍼를 갖는 분배기(buffered distributor)라고 한다.
(3) 공유되는 브로드캐스트 채널에서는 CSMA/CD를 사용한다. 적절한 효율을 얻기 위해서는 노드 사이의 최대 거리를 제한해야 한다.
(4) 점대점 채널에서는 양방향으로 40 Gbps로 전이중 동작이 가능한다.
현재 많이 사용되는 이더넷은 저장 후 전달 패킷 교환을 하는 스위치 기반의 스타 토폴로지이다. 스위치는 전송을 조절하며 동일 인터페이스로 하나 이상의 프레임을 절대 전달하지 않는다. 또한 현대 스위치는 전이중이며 따라서 스위치와 노드는 간선 없이 동시에 서로에게 프레임을 보낼 수 있다.
다시 말해서 스위치 기반 이더넷 랜에는 충돌이 없으며 따라서 MAC 프로토콜이 필요 없다. 그럼에도 여전히 이더넷이 사용되며, 변함없이 유지된 한 가지가 바로 이더넷 프레임 형식이다.
6.4.3. 링크 계층 스위치(Link-Layer Switches)
스위치의 역활은 들어오는 링크 계층 프레임을 수신해서 출력 링크로 전달하는 것이다. 스위치는 서브넷의 호스트/라우터들에게 투명(transparent)하다.
호스트/라우터는 프레임을 스위치가 아닌 다른 호스트/라우터를 목적지로 해서 랜상으로 보내며, 중간에 스위치가 프레임을 받아서 전달하는 것을 알지 못한다. 프레임이 스위치 출력 인터페이스에 도착하는 속도가 그 인터페이스의 링크 용량을 일시적으로 초과할 수 있다. 이 문제를 해결하기 위해, 스위치 출력 인터페이스는 버퍼를 갖고 있다.
6.4.3.1. 전달 및 여과(Forwarding and Filtering)
여과는 프레임을 인터페이스로 전달할지 또는 폐기할지 결정하는 스위치의 기능이다. 전달은 프레임이 전송될 인터페이스를 결정하고 해당 인터페이스로 보내는 기능이다. 스위치의 여과와 전달은 스위치 테이블(switch table)을 이용한다.
스위치 테이블의 항목에는 (1) MAC 주고, (2) 그 MAC 주소로 가게 하는 스위치 인터페이스, (3) 해당 항목이 만들어진 시점에 대한 정보가 있다.
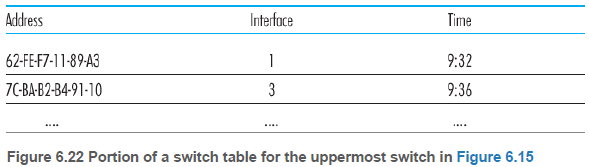
스위치는 프레임이 인터페이스 x에 도착했을 때 다음 세 가지 행동을 할 수 있다. (1) 테이블에 목적지 주소에 대한 항목이 없다. 이 경우 프레임의 복사본을 인터페이스 x를 제외한 모든 인터페이스의 앞에 있는 출력 버퍼로 전달한다. 즉, 목적지 주소에 대한 항목이 없으면 프레임을 브로드캐스트한다.
(2) 테이블에 목적지 주소가 인터페이스 x와 연관된 항목이 있다. 프레임이 목적지가 있는 랜 세그먼트로 이미 브로드캐스트 되었으므로, 프레임을 다른 인터페이스로 전달할 필요가 없다. 프레임을 제거함으로써 여과 기능을 수행한다.
(3) 테이블에 목적지 주소가 인터페이스 y!=x와 연관된 항목이 있다. 이 경우 프레임은 인터페이스 y에 접속된 랜 세그먼트로 전달되어야 한다. 인터페이스 y앞에 있는 출력 버퍼에 프레임을 넣는다.
6.4.3.2. 자가학습(Self-Learning)
스위치는 자신의 테이블을 자동으로, 동적으로, 자치적으로(네트워크 관리자나 구성(configuration) 프로토콜의 개입 없이) 구축한다. 자가학습은 다음처럼 이루어진다.
- 스위치 테이블은 초기에 비어 있다.
- 인터페이스로 수신한 각 프레임에 대해 (1) 프레임의 출발지 MAC 주소, (2) 프레임이 도착한 인터페이스, (3) 현재 시간을 테이블에 저장한다.
- 일정 시간(수명 시간; aging time)이 지난 후에도 해당 주소를 출발지 주소로 하는 프레임을 수신하지 못하면 테이블에서 이 주소를 삭제한다.
스위치는 네트워크 관리자나 사용자의 개입을 요구하지 않으므로 플러그 앤 플레이(plug-and-play) 장치다. 네트워크 관리자는 랜 세그먼트를 스위치 인터페이스에 연결하는 것 이외의 일은 하지 않는다.
6.4.3.3. 링크 계층 스위치의 특성(Properties of Link-Layer Switching)
버스나 허브 기반의 스타 토폴로지와 같은 브로드캐스트 링크가 아닌, 스위치를 사용하면 다음과 같은 장점이 있다.
(1) 충돌 제거(Elimination of collisions): 스위치로 구축된 랜에는 충돌로 낭비되는 대역폭이 없다. 스위치는 프레임을 버퍼링하여 어느 시점이든 세그먼테에 하나 이상의 프레임을 전송하지 않는다. 스위치의 최대 총처리율은 모든 스위치 인터페이스 속도의 합이다.
(2) 이질적인 링크들(Heterogeneous links): 스위치는 링크들을 별개로 분리하기 때문에 랜의 각 링크는 상이한 속도로 동작할 수 있으며 상이한 매체를 사용할 수 있다. 따라서 스위치는 기존 장비를 새로운 장비와 함께 사용할 수 있게 해준다.
(3) 관리(Management): 스위치는 향상된 보안을 제공할 뿐만 아니라 네트워크 관리를 쉽게 할 수 있게 해준다. 예를 들어, 어댑터가 오작동해서 프레임을 계속 보내는 경우, 스위치는 이를 감지하고 어댑터의 연결을 끊는다. 이와 유사하게 케이블이 단절된 경우 이 케이블을 이용해서 스위치에 연결된 호스트의 연결만 끊어진다.
스위치는 대역폭 사용, 충돌률, 트래픽 종류에 대한 통계치를 수집하며, 이 정보를 네트워크 관리자가 사용할 수 있도록 해준다.
6.4.3.4. 스위치 대 라우터(Switches Versus Routers)
라우터는 네트워크 계층 주소를 사용해서 패킷을 전달하는 저장 후 전달(store-and-forward) 3계층 패킷 스위치이다. 스위치는 MAC 주소를 사용해서 패킷을 전달하는 2계층 패킷 스위치이다.
그러나 (4.4절) 일치와 동작(match plus action) 기능을 사용하는 최신 스위치들의 경우, IP 주소를 기반으로 3계층 데이터그램 뿐만 아니라 MAC 주소를 기반으로 2계층 프레임도 전달한다. 실제로, OpenFlow 표준을 사용하는 스위치는 프레임, 데이터그램, 트랜스포트 계층 헤더의 필드들을 사용해서 범용 패킷 전달을 수행할 수 있다.
스위치의 장단점은 다음과 같다. 스위치는 플러그 앤 플레이 장치이다. 스위치는 상대적으로 높은 패킷 여과 및 전달률을 가진다(2계층까지만 패킷을 처리).
그러나, 브로드캐스트 프레임의 순환을 방지하기 위해 스위치 네트워크에 사용되는 토폴로지는 스패닝 트리로 제한된다. 또한 대규모 스위치 네트워크에서는 호스트/라우터가 커다란 ARP 테이블을 갖게 되며 상당한 양의 ARP 트래픽이 생성되고 처리된다. 그리고 브로드캐스트 트래픽의 폭주에 대비한 방안을 제공하지 않는다.
라우터의 장단점은 다음과 같다. 네트워크에 중복된 경로가 있을 때도 패킷은 라우터를 따라 순환하지 않는다(라우터 테이블이 잘못 구성되면 순환할 수 있기에, IP는 순환을 제한하기 위해 헤더 필드를 사용한다). 토폴로지에 제한이 없으며, 출발지와 목적지 간의 최상의 경로를 사용할 수 있다. 브로드캐스트 트래픽의 폭주에 대비한 방화벽 보호 기능이 있다.
그러나, 라우터는 플러그 앤 플레이가 아니다. 또한 3계층 필드까지 처리해야 하므로 스위치보다 패킷당 처리 시간이 더 크다.
| 허브 | 라우터 | 스위치 | |
|---|---|---|---|
| 트래픽 격리 | 아니요 | 예 | 예 |
| 플러그 앤 플레이 | 예 | 아니요 | 예 |
| 최적 라우팅 | 아니요 | 예 | 아니요 |
6.4.4. 가상 근거리 네트워크(Virtual Local Area Networks, VLANs)
VLAN을 지원하는 스위치는 하나의 물리적 근거리 네트워크 기반구조(infrastructure)상에서 여러 개의 가상 근거리 네트워크들을 정의할 수 있게 한다. VLAN에서는 네트워크 관리자가 스위치 포트(인터페이스)를 그룹으로 나눈다.
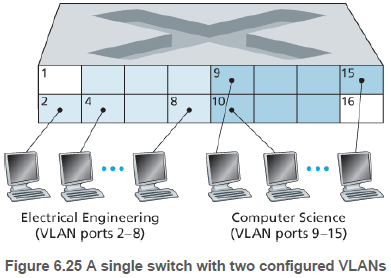
각 그룹은 하나의 VLAN을 구성하며, 한 VLAN의 포트들은 하나의 브로드캐스트 도메인을 형성한다. 즉, 한 포트로부터의 보로드캐스트 트래픽은 그 그룹의 다른 포트에만 도달할 수 있다.
네트워크 관리자는 스위치 관리 소프트웨어를 사용해서 포트가 어떤 VLAN에 속하는지 선언할 수 있어, 그룹에 속한 사용자를 다른 사용자로 이동시킬 때, 물리적 케이블의 연결을 변경시킬 필요가 없다.
포트-VLAN 매핑 테이블은 스위치에서 관리되며, 스위치 하드웨어는 같은 VLAN에 속한 포트들 간에만 프레임을 전달한다.
다른 그룹간의 트래픽은 VLAN 스위치 포트(예: 아래 그림의 포트 1)을 외부 라우터에 연결하고, 이 포트를 다른 그룹 모두에 속하게 하면 된다. 다행히도, 스위치 생산자들은 단일 장치에 VLAN 스위치와 라우터를 모두 포함시킴으로써(별도의 외부 라우터가 필요 없도록) 네트워크 관리자가 이러한 구성을 쉽게 할 수 있게 해준다.
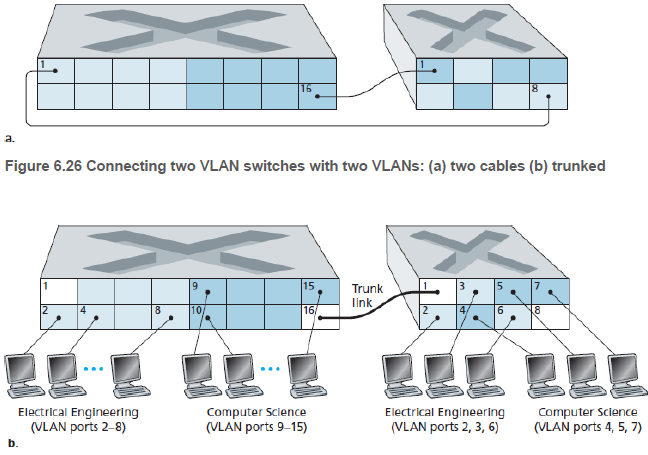
VLAN 스위치들을 연결하는 확장 가능한 방법으로는, 각 스위치의 포트 하나를 같은 그룹에 속하게 하고 이들 포트를 서로 연결하는 방법이다. 하지만 이 방법은 N개의 VLAN이 있는 경우, 연결을 위해 스위치 마다 N개의 포트들이 필요하다.
다른 방법은 VLAN 트렁킹(VLAN trunking)이 있다. 이 방법에서는 스위치 마다 하나의 특수 포트가 2개의 VLAN 스위치를 연결하는 트렁크 포트(trunk port)로 구성되어 있다. 트렁크 포트는 모든 VLAN에 속하며, 한 VLAN에서 전송한 프레임들을 트렁크 링크를 통해 다른 스위치로 전달해 준다.
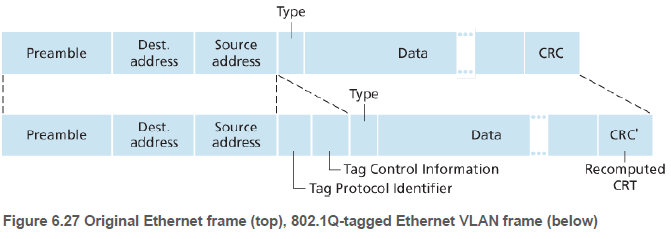
트렁크 포트로 온 프레임이 어떤 VLAN에 속하는지 알 수 있도록, IEEE는 확장된 형태의 이더넷 프레임 형식인 802.1Q를 정의했다. 프레임이 속한 VLAN을 식별해주는 VLAN 태그를 헤더에 추가하였다. VLAN 태그는 송신 스위치에 의해 프레임에 추가되며, 수신 스위치에 의해 사용되고 제거된다.
6.5. 링크 가상화: 링크 계층으로서의 네트워크(Link Virtualization: A Network as a Link Layer)
이 장을 시작할 때, 서로 통신하는 2개의 호스트를 연결하는 물리적인 선(wire)을 링크로 간주하였다. 다중 접속 프로토콜으로 여러 호스트가 공유된 선에 의해서 연결될 수 있고, 선은 여러 매체일 수 있음을 보았다. 따라서 선보다는 채널로 링크를 더 추상화해서 고려할 수 있다.
이더넷 랜에 대한 설명에서 상호연결하는 매체가 스위치 기반구조일 수 있음을 보았다. 하지만, 이더넷 호스트는 하나의 랜 세그먼트, 분산 배치된 스위치 랜 또는 VLAN에 의해서 다른 랜 호스트들과 연결되었는지 여부를 구분 못할 수 있다.
두 호스트들 사이의 다이얼업(dialup) 모뎀 연결에서 링크는 전화 네트워크(데이터 전송과 시그널링을 위한 스위치, 프로토콜 스택 등을 가진 논리적으로 분리된 광역 전화 통신 네트워크)이다. 그러나 인터넷 링크 계층 관점에서 이 연결은 단순히 “선”처럼 보인다. 이런 점에서 인터넷은 전화 네트워크를 호스트들 사이의 링크 계층 연결을 제공하는 링크 계층 기술로 간주하여, 전화 네트워크를 가상화한다.
이 절에서는 다중 프로토콜 레이블 스위칭(Multiprotocol Label Switching, MPLS) 네트워크에 대해서 살펴본다. MPLS는 자체적인 패킷 형식과 전달 방식을 사용하며, 네트워크 계층이나 링크 계층에 해당한다. 그러나 인터넷 관점에서 MPLS는 전화 네트워크나 스위치 이더넷처럼, IP 장치를 상호연결하는 데 사용되는 링크 계층 기술로 다뤄질 수 있다.
6.5.1. 다중 프로토콜 레이블 스위칭(MPLS)
MPLS의 목표는 가능한 경우에 데이터그램을 선택적으로 레이블링(labeling)해서, 라우터로 하여금 목적지 IP 주소가 아닌 고정 길이 레이블(labels)을 기반으로 데이터그램을 전달할 수 있도록 목적지 기반 IP 데이터그램 전달 하부구조를 확장시키는 것이다.
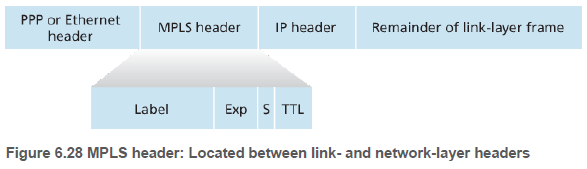
MPLS 가능(MPLS-capable) 라우터에 의해 처리되는 링크 계층 프레임에는 MPLS 헤더가 추가된다. 이는 2계층(예: 이더넷) 헤더와 3계층(예: IP)헤더 사이에 위치한다. 이 프레임은 MPLS 가능 라우터들 사이에서만 전송될 수 있다.
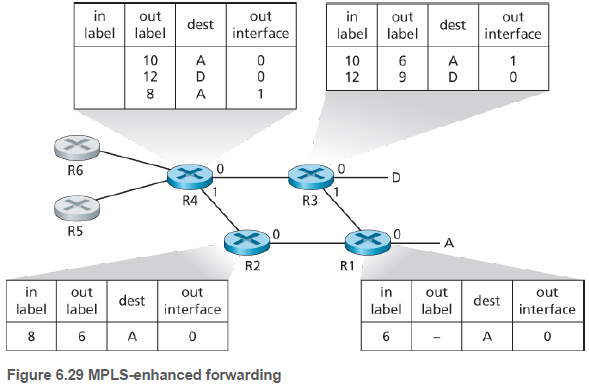
MPLS 가능 라우터는 MPLS 레이블을 포워딩 테이블에서 찾아 출력 인터페이스로 데이터그램을 전달한다. 그렇기에 레이블 스위치 라우터(label-switched router)라고도 불린다.
MPLS 가능 라우터는 IP 주소를 볼 필요도 없고, 포워딩 테이블에서 최장 프리픽스 대응을 찾을 필요도 없다. 아래 그림에서 MPLS 가능 라우터 R1부터 R4는 패킷의 IP 헤더를 건드리지 않고 동작한다. MPLS 가능 라우터들 간에 테이블을 분배하는 시그널링 프로토콜에 대한 자세한 사항은 RFC 3468 참고하라.
MPLS는 스위칭 속도를 향상시키고 트래픽 관리 기능을 제공한다. 5장에서 다룬 IP 라우팅 프로토콜은 목적지로의 최소비용경로 하나만 지정한다.
반면 MPLS는 여러 경로를 제공하기 때문에(위 그림 R4 테이블의 목적지 A가 두개), 네트워크 운영자는 트래픽을 여러 경로로 보낼 수 있다. 이것은 MPLS를 사용해서 트래픽 엔지니어링(traffic engineering)을 제공하는 하나의 방식이다.
MPLS는 경로 복구, 가상 사설 네트워크(virtual privatenetwork, VPN)을 구현하는 데도 사용될 수 있다.
6.6. 데이터 센터 네트워킹(Data Center Networking)
구글, 아마존과 같은 인터넷 기업들은 수십만 대의 호스트를 지원하고, 동시에 여러 종류의 다양한 클라우드 애플리케이션(예: 검색, 전자메일, 전자상거래)을 지원하는 대규모 데이터 센터를 구축하고 있다. 데이터 센터는 호스트들 간 상호연결 및 데이터 센터와 인터넷 간 상호연결을 위해 자체 데이터 센터 네트워크를 갖고 있다.
데이터 센터의 호스트들은 피자 박스 모양의 블레이드(blade)라고도 불리는 호스트로, CPU, 메모리, 디스크 저장장치를 갖고 있다. 호스트들은 20~40대의 블레이드를 적재할 수 있는 랙(rack)에 적재된다. 랙의 맨 위에는 TOR(Top of Rack) 스위치라고 불리는 스위치가 있으며, 이는 랙에 있는 호스트들을 연결해 주고 데이터 센터의 다른 스위치들과 연결된다.
데이터 센터 네트워크는 하나 이상의 경계(border) 라우터를 가지며, 이는 데이터 센터 네트워크를 공중(public) 인터넷으로 연결해준다. 따라서 데이터 센터 네트워크는 랙을 서로 연결해 주고, 랙을 경계 라우터로 연결해 준다.
6.6.1. 부하 균등화(Load Balancing)
데이터 센터에서는 외부로부터 요청이 들어오면 먼저 부하 균등화기(load balancer)로 보내며, 이는 요청을 호스트의 부하 상태에 따라서 분배하여 호스트 간의 부하를 균등하게 한다.
부하 균등화기는 패킷의 목적지 IP 주소뿐만 아니라 목적지 포트 번호(4계층)를 보고 결정하기 때문에 4계층 스위치라고도 한다. 또한 부화 균등화기는 호스트의 공용 외부 IP 주소를 내부 IP 주소로 변환해주고, 그 반대 방향도 변환해주는 NAT와 유사한 기능을 제공한다. 이렇게 해서 클라이언트가 호스트와 직접 통신하지 못하게 하며, 내부 네트워크 구조를 숨겨 보안을 제공한다.
6.6.2. 계층적 구조(Hierarchical Architecture)
그림 6.30과 같이 계층구조 설계를 사용함으로써 데이터 센터는 수십만 대의 호스트까지 확장할 수 있다.
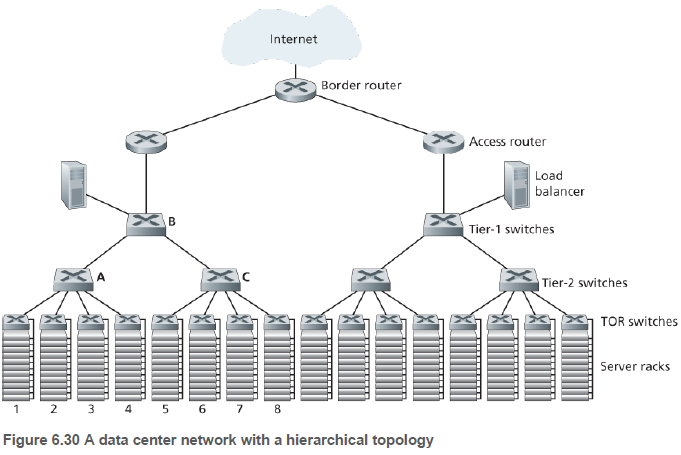
데이터 센터는 애플리케이션의 가용성을 높이기 위해 여분의 네트워크 장비와 링크를 포함시킨다. 예를 들어, TOR 스위치는 2개의 2단 스위치에 연결되며, 접속 라우터, 1단 스위치, 2단 스위치를 이중으로 구성할 수 있다.
이 구조에서는 서로 다른 랙에 있는 호스트들이 동시에 다른 호스트에 트래픽을 보내면, 처리율이 떨어질 수도 있다.
6.6.3. 데이터 센터 네트워크 동향(Trends in Data Center Networking)
지연과 처리율 성능을 향상시키기 위해, 새로운 상호연결 구조와 네트워크 프로토콜들이 개발/사용되고 있다.
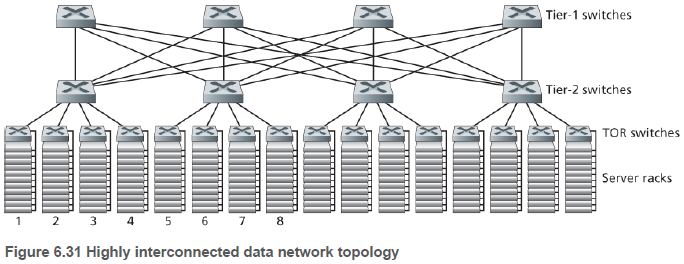
구조에는 위 그림처럼 완전 연결 토폴로지(fully connected topology), 선박 컨테이너(shipping container) 기반의 모듈화된 데이터 센터(modular data center, MDC) 등이 있다.
라우팅 프로토콜 방법에는 호스트마다 네트워크 인터페이스 카드를 여러 개 설치한 후, 여러 대의 스위치에 연결하는 방법이 있다. 그러면 호스트들이 알아서 스위치 간 트래픽 라우팅을 할 수 있다.
다른 동향은, 클라우드 제공자가 어댑터, 라우터, 프로토콜 등 데이터 센터에 있는 것들을 구축하거나 커스터마이징한다는 것이다.
또 다른 동향은, 근처 건물들에 데이터 센터를 복제함으로써 가용 구역(availability zone)을 확보해서 신뢰성을 향상시키는 것이다.
6.7. 총정리: 웹페이지 요청에 대한 처리(Retrospective: A Day in the Life of a Web Page Request)
6장까지 프로토콜 스택을 다루었다. 지금까지 내용을 총정리하고자 한다. 예제로, 웹 페이지를 다운로드 하는 요청을 해결하는 것과 관련된 프로토콜에 대해 살펴본다.
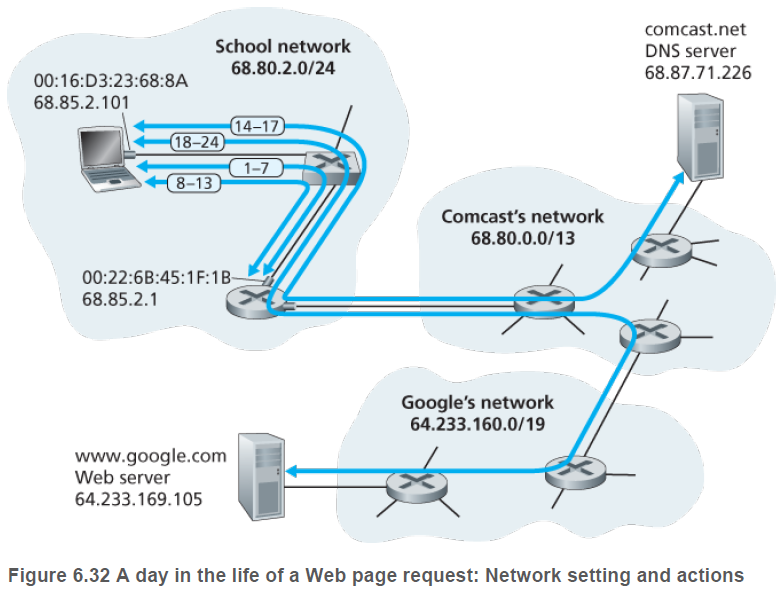
학생이 학교의 이더넷 스위치에 랩톱(laptop)을 연결하고, 웹 페이지(www.google.com)을 다운로드하는 것을 보여 준다.
6.7.1. 시작하기: DHCP, UDP, IP 그리고 이더넷(Getting Started: DHCP, UDP, IP, and Ethernet)
학생은 랩톱을 켠 후 학교 이더넷 스위치에 연결되어 있는 이더넷 케이블에 연결한다. 여기서, 학교 라우터는 ISP comcast.net에 연결되어 있고, comcast.net은 이 학교에 DNS 서비스를 제공하며, DNS 서버는 학교 네트워크가 아닌 comcast 네트워크에 있다. DHCP 서버는 라우터에서 실행되고 있다고 가정하자(일반적인 상황임).
학생이 랩톱을 네트워크에 연결하면, 랩톱은 로컬 DHCP 서버로부터 IP 주소를 얻기 위해 DHCP 프로토콜을 실행한다.
(1) 랩톱의 운영체제는 DHCP 요청 메세지를 만들고, 이를 목적지 포트 67(DHCP 서버)과 출발지 포트 68(DHCP 클라이언트)를 갖는 UDP 세그먼트에 넣는다. 이 세그먼트는 브로드캐스트 IP 목적지 주소(255.255.255.255)와 출발지 IP 주소(0.0.0.0, 랩톱은 아직 IP 주소가 없다)을 갖는 IP 데이터그램에 들어간다.
(2) IP 데이터그램은 이더넷 프레임에 들어간다. 스위치에 연결된 모든 장치(DHCP 서버도 포함)에 이 프레임이 브로드캐스트 될 수 있도록, 이더넷 프레임의 목적지 MAC 주소는 FF:FF:FF:FF:FF:FF로 설정된다. 프레임의 출발지 MAC 주소는 랩톱의 MAC 주소가 된다.
(3) 이더넷 프레임은 랩톱이 처음으로 이더넷 스위치에 전송한 프레임이다. 스위치는 프레임을 자신의 모든 출력 포트로 브로드캐스트한다.
(4) 라우터는 이더넷 프레임을 수신하고, 이로부터 IP 데이터그램을 추출한다. 데이터그램의 브로드캐스트 IP 목적지 주소는, 이 IP 데이터그램이 노드의 상위 계층 프로토콜에 의해서 처리되어야 함을 의미한다. 따라서 데이터그램의 페이로드(UDP 세그먼트)가 UDP로 역다중화되고, UDP 세그먼트로부터 DHCP 요청 메세지가 추출된다. 이제 DHCP 서버는 DHCP 요청 메세지를 갖게 된다.
(5) 라우터에서 실행되고 있는 DHCP 서버가 CIDR 블록 68.85.2.0/24에 있는 IP 주소들을 할당할 수 있다고 가정하자. 이 예제의 경우, 학교에서 사용하는 모든 IP 주소는 comcast의 주소 블록 내에 있는 것들이다. DHCP 서버가 랩톱에 주소 68.85.2.101을 할당했다고 가정하자. DHCP 서버는 이 IP 주소와 DNS 서버의 IP 주소(68.87.71.226), 디폴트 게이트웨이 라우터의 IP 주소(68.85.2.1), 서브넷 블록(68.85.2.0/24; 네트워크 마스크)를 포함하는 DHCP ACK 메세지를 만든다. DHCP ACK 메세지는 UDP 세그먼트에 들어가고, UDP 세그먼트는 IP 데이터 그램에 들어가며, IP 데이터그램은 이더넷 프레임에 들어간다. 이더넷 프레임은 출발지 MAC 주소로 라우터 인터페이스의 MAC 주소(00:22:6B:45:1F:1B)를, 목적지 MAC 주소로 랩톱의 MAC 주소(00:16:D3:23:68:8A)를 갖는다.
(6) 이더넷 프레임은 라우터에 의해서 스위치로 전송된다(유니캐스트). 스위치는 자가학습을 하며, 이전에 랩톱으로부터 이더넷 프레임을 수신했기 때문에 00:16:D3:23:68:8A를 목적지로 하는 프레임은 랩톱으로 가는 출력포트로만 전달되어야 한다는 것을 안다.
(7) 랩톱은 DHCP ACK를 포함하는 이더넷 프레임을 수신한 후, 이더넷 프레임으로부터 IP 데이터그램을 추출하고, IP 데이터그램으로부터 UDP 세그먼트를 추출하며, UDP 세그먼트로부터 DHCP ACK 메세지를 추출한다. 학생의 DHCP 클라이언트는 자신의 IP 주소와 DNS 서버의 IP 주소를 기록하고, 자신의 IP 포워딩 테이블에 디폴트 게이트웨이의 주소를 저장한다. 랩톱은 자신이 속한 서브넷 68.85.2.0/24의 외부를 목적지 주소로 하는 모든 데이터그램을 디폴트 게이트웨이로 보내게 된다. 이 시점에서 랩톱은 자신의 네트워킹 구성요소들을 초기화하고 웹 페이지 가져오기(fecth)를 처리할 준비를 한다(DHCP 4단계 중 마지막 두 단계만 실제로 필요함을 주목하라).
6.7.2. 여전히 시작하기: DNS와 ARP(Still Getting Started: DNS and ARP)
학생이 웹 브라우저에 URL로 www.google.com을 입력하면 웹 브라우저에 구글 홈페이지가 출력되도록 하는 긴 이벤트들이 시작된다. 학생의 웹 브라우저는 www.google.com으로 HTTP 요청 메세지를 보내기 위해 TCP 소켓을 생성하는 절차를 시작한다. 소켓을 생성하기 위해서 랩톱은 www.google.com의 IP 주소를 알아야만 한다. DNS 프로토콜이 이름을 IP 주소로 변환해 주는 서비스를 제공한다.
(8) 랩톱의 운영체제는 DNS 질의 메세지를 생성하며, 이때 질문 부분(question section)에 www.google.com 을 넣는다. DNS 질의 메세지는 목적지 포트가 53(DNS 서버)인 UDP 세그먼트에 들어간다. UDP 세그먼트는 목적지 IP 주소 68.87.71.226(DNS 서버)과 출발지 IP 주소 68.85.2.101(랩톱)인 IP 데이터그램에 들어간다.
(9) 랩톱은 IP 데이터그램을 이더넷 프레임에 넣는다. 이 프레임은 학생의 학교 네트워크에 있는 디폴트 게이트웨이 라우터로 보내진다(링크 계층에서 주소가 주어짐). 랩톱은 디폴트 게이트웨이 라우터의 IP 주소(68.85.2.1)를 (5) 에서 알게 되지만, MAC 주소는 알 수 없다. MAC 주소를 얻기 위해서 랩톱은 ARP 프로토콜을 사용하게 된다.
(10) 랩톱은 목적지 IP 주소 68.85.2.1을 포함한 ARP 질의 메세지를 생성하며, ARP 메세지는 브로드캐스트 목적지 주소(FF:FF:FF:FF:FF:FF)를 갖는 이더넷 프레임에 포함되어 스위치로 전송된다. 스위치는 모든 연결된 장치로 프레임을 전달한다.
(11) 디폴트 게이트웨이 라우터는 프레임을 수신하고, ARP 메세지로부터 목표 IP 주소 68.85.2.1을 찾아서 자신의 인터페이스의 IP 주소와 일치하는 것을 알게 된다. 따라서 디폴트 게이트웨이 라우터는 IP 주소에 대응하는 MAC 주소 00:22:6B:45:1F:1B를 포함한 ARP 응답 메세지를 만든다. ARP 응답 메세지를 목적지 주소 00:16:D3:23:68:8A (랩톱)인 이더넷 프레임에 넣어서 스위치로 보내며, 스위치는 프레임을 랩톱으로 전달한다.
(12) 랩톱은 프레임을 수신해서, 디폴트 게이트웨이 라우터의 MAC 주소를 알게 된다.
(13) 이제 랩톱은 디폴트 게이트웨이 라우터의 MAC 주소로 DNS 질의 메세지가 포함된 이더넷 프레임을 보낼 수 있다. 랩톱은 프레임을 스위치로 보내고, 스위치는 프레임을 디폴트 게이트웨이 라우터로 전달한다.
6.7.3. 여전히 시작하기: DNS 서버로의 인트라-도메인 라우팅(Still Getting Started: Intra-Domain Routing to the DNS Server)
(14) 디폴트 게이트웨이 라우터는 프레임을 받아서 DNS 질의가 포함된 IP 데이터그램을 추출한다. 라우터는 데이터그램의 목적지 주소(68.87.71.226)를 포워딩 테이블에서 찾아서 데이터그램을 그림 6.32의 comcast 네트워크의 좌측 라우터로 보내야한다는 것을 알게 된다. IP 데이터그램을, 학교 라우터를 comcast의 좌측 라우터로 연결해 주는 링크에 적합한 링크 계층 프레임에 넣고, 프레임을 이 링크를 통해 전송한다.
(15) comcast의 좌측 라우터는 프레임을 수신한 후, IP 데이터그램을 추출해서 데이터그램의 목적지 주소(68.87.71.226)를 확인한다. 그리고 인터넷 인터-도메인 라우팅 프로토콜인 BGP와 comcast의 인트라-도메인 프로토콜(RIP, OSPF, IS-IS 등)에 의해 채워진 포워딩 테이블을 사용하여, DNS 서버로 전달할 출력 인터페이스를 결정한다.
(16) DNS 질의가 포함된 IP 데이터그램이 DNS 서버에 도착한다. DNS 서버는 DNS 질의 메세지를 추출한 후 DNS 데이터베이스에서 이름 www.google.com 을 찾아서 이에 해당하는 IP 주소(64.233.168.105)를 포함하는 DNS 자원 레코드(resource record)를 찾는다(DNS 서버에 이 레코드가 캐싱되어 있다고 가정). 캐싱된 데이터는 google.com에 대해 책임(authoritative) DNS 서버가 준 것이다. DNS 서버는 호스트 이름에 대한 IP 주소 정보를 포함하는 DNS 응답 메세지를 만들어서 UDP 세그먼트에 넣은 후, UDP 세그먼트를 랩톱을 목적지로 하는 IP 데이터그램에 넣는다. 이 데이터그램은 comcast 네트워크를 통해 학교 라우터로 가서 이더넷 스위치를 통해 랩톱으로 전달된다.
(17) 랩톱은 DNS 메세지로부터 서버 www.google.com 의 IP 주소를 추출한다. 이제 www.google.com 서버에 접속할 준비가 되었다.
6.7.4. 웹 클라이언트-서버 상호작용:TCP와 HTTP(Web Client-Server Interaction: TCP and HTTP)
(18) 랩톱은 www.google.com의 IP 주소를 얻었으므로, HTTP GET 메세지를 www.google.com 으로 보내는 데 사용할 TCP 소켓을 생성할 수 있다. TCP 소켓을 생성할 때, 랩톱의 TCP는 www.google.com의 TCP와 3-방향 핸드셰이크를 수행한다. 랩톱은 목적지 포트 80(HTTP 용)을 갖는 TCP SYN 세그먼트를 생성하고, TCP 세그먼트를 목적지 IP 주소가 64.233.169.105(www.google.com)인 IP 데이터 그램에 넣은 후, IP 데이터그램을 목적지 MAC 주소가 디폴트게이트 웨이 라우터인 프레임에 넣어서, 이 프레임을 스위치로 전송한다.
(19) 학교, comcast, google 네트워크에 있는 라우터들은 데이터그램을 (14)~(16)에서처럼 각 라우터의 포워딩 테이블으 사용해서 www.google.com 쪽으로 전달한다. comcast, google 네트워크 사이의 도메인 간 링크상으로 패킷을 전달하는 데 사용되는 라우터의 포워딩 테이블 항목은 BGP 프로토콜에 의해서 결정된다.
(20) www.google.com 에서 TCP SYN 메세지는 데이터그램으로부터 추출되어서 포트 80과 연관된 환영(welcome) 소켓으로 역다중화된다. 이후 연결(connection) 소켓이 구글 HTTP 서버와 랩톱 사이의 TCP 연결을 위해서 생성된다. TCP SYNACK 세그먼트를 생성해서 랩톱을 목적지로 하는 데이터그램에 넣은 후, www.google.com을 첫-홉(first-hop) 라우터로 연결해 주는 링크에 적합한 링크 계층 프레임에 넣는다.
(21) 데이터그램은 google, comcast, 학교 네트워크를 통해 랩톱의 이더넷 카드에 도착한다. 데이터그램은 (18)에서 생성된 TCP 소켓으로 운영체제에서 역다중화된다(이 소켓은 연결된 상태가 된다).
(22) 랩톱의 소켓을 바이트를 www.google.com로 보낼 준비가 되었다. 학생의 브라우저는 가져올 URL이 포함된 HTTP GET 메세지를 생성한다. HTTP GET 메세지를 소켓으로 보내며, 이는 TCP 세그먼트의 페이로드가 된다. TCP 세그먼트를 데이터그램에 넣어서 보내면 (18)~(20)에서처럼 www.google.com으로 전달된다.
(23) www.google.com에 있는 HTTP 서버는 TCP 소켓으로부터 HTTP GET 메세지를 읽고, HTTP 응답 메세지를 생성하고, 요청된 웹 페이지의 콘텐츠를 HTTP 응답 메세지의 바디(body)에 포함시켜서 TCP 소켓으로 보낸다.
(24) HTTP 응답 메세지를 포함하고 있는 데이터그램은 google, comcast, 학교 네트워크를 통해 전달되어 랩톱에 도착한다. 학생의 웹 브라우저 프로그램은 소켓에서 HTTP 응답 메세지를 읽어서, HTTP 응답 메세지의 바디로부터 웹 페이지에 대한 html을 추출한 후 웹 페이지를 출력한다.
댓글남기기