컴퓨터 네트워킹 요약 - 5. 네트워크 계층: 제어 평면
5.1. 개요(Introduction)
4장에서는 네트워크 계층: 데이터 평면을 보았다.
(1) 라우터별 제어(Per-router control): 라우팅 알고리즘이 모든 라우터 각각에서 동작한다. 라우터는 다른 라우터의 라우팅 구성요소와 통신하여 자신의 포워딩 테이블의 값을 계산하는 라우팅 구성요소를 가지고 있다. 5.3절, 5.4절의 OSPF, BGP 프로토콜이 이 라우터별 제어 방식을 기반으로 한다.
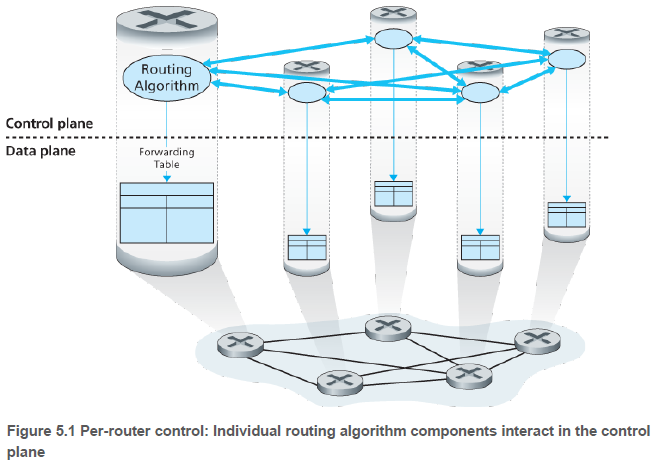
(2) 논리적으로 중앙 집중된 제어(Logically centralized control): 논리적으로 집중된 컨트롤러가 포워딩 테이블을 작성하고 이를 모든 라우터가 사용할 수 있도록 배포한다. 컨트롤러는 각 라우터의 제어 에이전트(control agent, CA)와 상호작용하여 라우터의 플로우 테이블을 구성 및 관리한다. 라우팅 알고리즘과 달리 CA는 서로 직접 상호 작용하지 않으며, 포워딩 테이블을 계산하는 데에도 적극적으로 참여하지 않는다.
논리적으로 중앙 집중된 제어란, 실제로 여러 개의 라우팅 서버에 라우팅 서비스가 구현된다 하더라도, 마치 하나의 중앙 서비스 지점에 있는 것처럼 서비스에 접근한다는 의미이다.
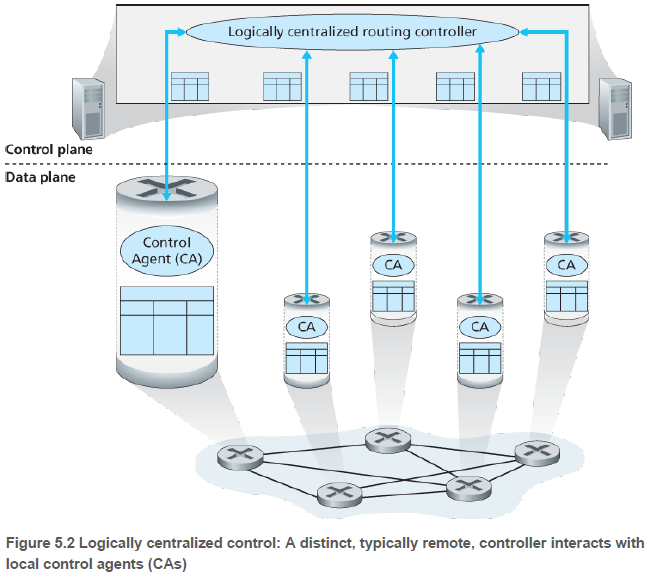
이 장에서는 포워딩 테이블이나 플로우 테이블이 어떻게 만들어지고, 유지, 설치되는지 알아본다.
5.2. 라우팅 알고리즘(Routing Algorithms)
라우팅 알고리즘의 목표는 송신자부터 수신자까지 라우터의 네트워크를 통과하는 좋은 경로를 결정하는 것이다. 일반적으로 좋은 경로란 최소 비용 경로를 말하지만, 네트워크 정책(예: Y 기관 라우터는 Z 기관 네트워크가 보낸 패킷을 전달하지 않는다)과 같은 문제가 고려된다.
라우팅 문제를 나타내는 데에는 노드와 에지를 사용한 무방향성 그래프가 사용된다. 노드는 라우터, 에지는 라우터들 간의 연결된 물리 링크를 나타낸다. 에지는 비용을 나타내는 값을 가지는데, 일반적으로 링크의 물리적인 거리, 링크 속도 등을 반영한다.
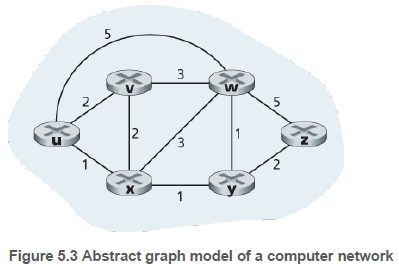
라우팅 알고리즘은 출발지와 목적지 간 최소 비용 경로를 찾는것을 목표로 한다. 라우팅 알고리즘을 분류하는 방법은 여러 가지가 있다.
첫 번째 분류 방법은 중앙 집중형인지 분산형인지이다. (1) 중앙 집중형 라우팅 알고리즘은 네트워크 전체에 대한 완전한 정보를 가지고 최소 비용 경로를 계산한다. 즉, 모든 노드 사이의 연결 상태와 링크 비용을 알아야 한다. 5.2.1절의 링크 상태 알고리즘이 이에 속한다.
(2) 분산 라우팅 알고리즘에서는 어떤 노드도 모든 링크의 비용에 대한 완전한 정보를 갖고 있지 않다. 각 노드는 자신에 직접 연결된 링크에 대한 정보만 가지고, 반복된 계산과 이웃 노드와의 정보 교환으로 최소 비용 경로를 계산한다. 5.2.2절의 거리 벡터 알고리즘이 이에 속한다.
두 번째 분류 방법은 정적 알고리즘과 동적 알고리즘으로 분류하는 것이다. (1) 정적 라우팅 알고리즘(static routing algorithms)에서 경로는 아주 느리게 변하는데, 보통 사람이 개입한 결과(예: 사람이 링크 비용 수정)로 그렇게 된다.
(2) 동적 라우팅 알고리즘(Dynamic routing algorithms)은 네트워크 트래픽 부하(load)나 토폴로지 변화에 따라 라우팅 경로를 바꾼다. 이 알고리즘은 주기적으로, 혹은 토폴로지나 링크 비용의 변경이 있을 때 실행될 수 있다.
세 번째 분류 방법은 라우팅 알고리즘이 부하에 민감한지 아닌지에 따른다. (1) 부하에 민감한 알고리즘(load-sensitive algorithm)에서 링크 비용은 해당 링크의 현재 혼잡 수준을 나타내기 위해 동적으로 변한다. 혼잡한 링크를 우회하는 경로를 택할 수 있다.
(2) 오늘날의 인터넷 라우팅 알고리즘(RIP, OSPF, BGP 등)은 링크 비용이 현재 혼잡 수준을 반영하지 않기 때문에 부하에 민감하지 않다(load-insensitive).
5.2.1. 링크 상태 라우팅 알고리즘(The Link-State (LS) Routing Algorithm)
링크 상태 알고리즘에는 네트워크 토폴로지와 모든 링크 비용이 알려져 있어야 한다. 이는 각 노드가 자신과 연결된 링크의 식별자와 비용을 포함하는 링크 상태 패킷을 네트워크상의 모든 다른 노드로 브로드캐스팅 함으로써 가능하다. 실제로 이 방식은 링크 상태 브로드캐스트 알고리즘에 의해 수행된다.
링크 상태 알고리즘은 다익스트라 알고리즘을 사용할 수 있다. 다익스트라 알고리즘은 하나의 노드에서 네트워크 내 모든 다른 노드로의 최소 비용 경로를 계산한다. 힙 자료 구조를 사용하여 로그급수 시간으로 최솟값을 찾을 수 있다.
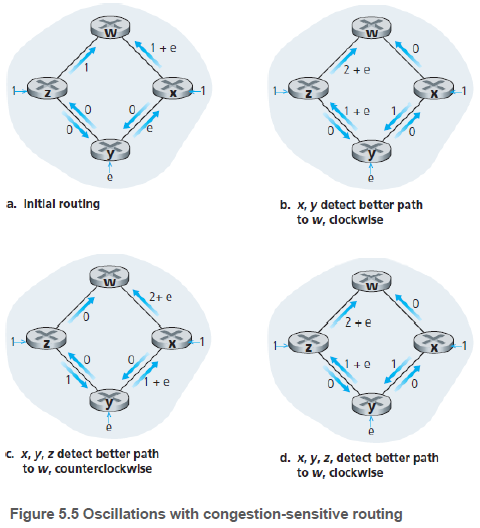
만약 링크 비용이 링크상에 전송 중인 부하를 반영한다면, 문제가 생길 수도 있다. 그림과 같이 동시에 라우터가 더 좋은 경로를 업데이트하여 트래픽을 전달하면, (c)-(d) 상태를 계속 반복할 수도 있다. 이와 같은 진동(oscillation) 문제는 링크 상태 알고리즘뿐 아니라 혼잡이나 지연 시간을 기반으로 링크 비용을 산출하는 모든 알고리즘에서 발생할 수 있다.
해결책으로는 모든 라우터가 동시에 링크 상태 알고리즘을 실행하지 못하도록 하는 방법이 있다. 링크 상태 정보를 송신하는 시각을 랜덤하게 결정한다.
5.2.2. 거리 벡터 라우팅 알고리즘(The Distance-Vector (DV) Routing Algorithm)
DV 알고리즘에서, 각 노드는 직접 연결된 이웃으로부터 정보를 받고, 계산을 수행하며, 계산된 결과를 다시 그 이웃들에게 배포한다. 최소 비용은 벨만-포트(Bellman-Ford) 식을 사용한다. x->y로 가는 경로, 이웃 노드(v)를 거치는 x->v->y 경로 중 작은 값을 택한다.
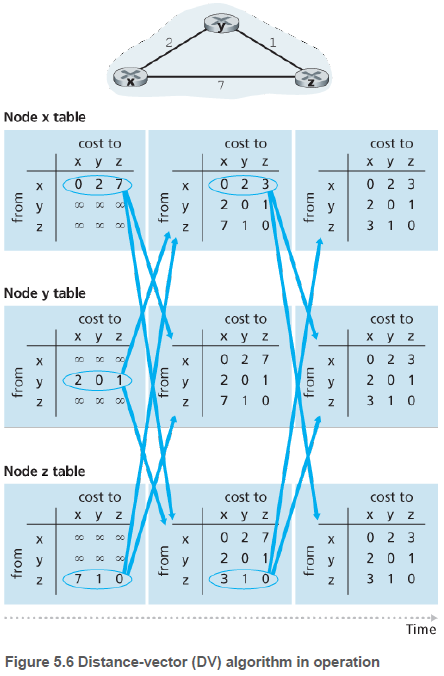
DV 알고리즘에서는 어떤 노드가 자신에게 직접 연결된 링크 중 하나의 비용이 변경된 사실을 알게 되거나, 어떤 이웃으로부터 변경된 거리 벹거를 수신했을 때, 업데이트가 발생한다. 이 변화는 다시 이웃에게 전달되고, 이런 반복은 더 이상의 갱신이 없을 때까지 일어난다.
5.2.2.1. 거리 벡터 알고리즘: 링크 비용 변경과 링크 고장(Distance-Vector Algorithm: Link-Cost Changes and Link Failure)
그림 5.7의 링크 비용 감소(a), 링크 비용 증가(b)의 상황을 나타낸다. 여기서, DV 알고리즘을 이용한 y, z에서 x로의 거리 갱신을 살펴본다.
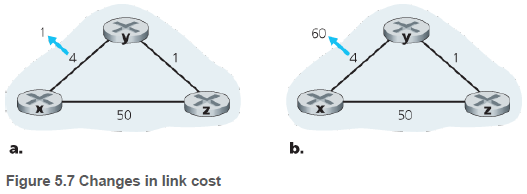
(a) 링크 비용이 감소할 때는 문제가 생기지 않는다. y가 z에게 x로의 거리 변경값을 알리면, z는 최소 비용 2를 계산한다. z가 갱신되었으므로 y에게 이를 알리지만, y는 최소 비용 변화가 없으므로 알고리즘이 끝난다. 비용이 감소하는 좋은 소식은 네트워크에 빠르게 전달된다.
(b) 링크 비용이 증가하면, 문제가 생길 수도 있다. y가 x로의 비용이 60으로 증가했으므로, y에서 x로 가는 최소 경로를 y->z->x 바꾸고 최소 비용을 6으로 바꾼다. y->z->x 경로는 51 여야 하지만, z가 y에게 이전에 알린 최소 경로는 z->y->x, 5이기에 비용이 잘못 계산된다. 만약 이 시각에 패킷을 보내면, 패킷이 y->z->y->z… 로 이동되는 라우팅 루프(routing loop)가 발생한다.
노드 y가 최소 비용을 갱신했으므로, z에게 알린다. y가 x로 가는 최소 비용이 잘못된 6을 알려줬으므로, z도 잘못된 7을(z->y->x) 계산한다. 이런 잘못된 갱신은 z->x 50 비용보다 z->y->x 보다 커질 때까지, 즉 44번 반복된다. 이를 무한 계수 문제(count-to-infinity problem)라고 한다. 비용이 증가하는 나쁜 소식은 네트워크에 천천히 전달된다.
5.2.2.2. 거리 벡터 알고리즘: 포이즌 리버스 추가(Distance-Vector Algorithm: Adding Poisoned Reverse)
포이즌 리버스는 위의 라우팅 루프 문제를 해결할 수 있다. 하지만, 세 개 이상의 노드를 포함한 루프는 감지할 수 없다.
포이즌 리버스를 사용하면, z가 y를 통해 목적지 x로 가는 경로를 설정 할 때, z는 y에게 z->x까지의 거리가 무한대라고 알려준다. 역경로를 차단하는 것이다.
5.2.2.3. 링크 상태 알고리즘과 거리 벡터 라우팅 알고리즘의 비교(A Comparison of LS and DV Routing Algorithms)
어느 알고리즘이 명백히 낫다고 할 수 없으며, 실제도 둘 다 사용된다.
(1) 메세지 복잡성(Message complexity): LS 알고리즘은 링크 비용이 변할 때마다, 새로운 링크 비용이 모든 노드에게 전달되어야 한다. DV 알고리즘은 링크 비용의 변화가, 링크에 연결된 노드의 최소 비용 경로에 변화를 준 경우에만, 새로운 링크 비용을 전파한다. 하지만, 전파에 많은 시간이 걸린다.
(2) 수렴 속도(Speed of convergence): LS 알고리즘은 O(N E)개의 메세지를 필요로 한다. DV 알고리즘은 라우팅 루프, 무한 계수 문제가 발생할 수 있다.
(3) 견고성(Robustness): LS 알고리즘은 잘못된 정보를 브로드캐스트할 수 있다. 그러나 각 노드는 자신의 포워딩 테이블만 계산한다. 이는 경로 계산이 어느 정도 분산되어 수행됨을 의미하고, 어느 정도의 견고성을 제공한다. DV 알고리즘에서는 잘못된 정보가 이웃에게 넘어가고, 이게 다시 이웃의 이웃으로 전달 될 수 있다.
5.3. 인터넷에서의 AS 내부 라우팅: OSPF(Intra-AS Routing in the Internet: OSPF)
앞선 라우팅 알고리즘에서 네트워크를 단순히 상호 연결된 라우터의 집합으로 보았다. 동일한 라우팅 알고리즘을 수행하는 동종의 라우터 집합으로 간주하는 관점은 두 가지 이유에서 중요하다.
(1) 확장: 라우터의 수가 증가함에 따라 라우팅 정보의 통신, 계산, 저장에 필요한 오버헤드가 증가한다. 인터넷처럼 큰 네트워크에서 경로 계산의 복잡성을 감소시킬 방법이 필요하다.
(2) 관리 자치(Administrative autonomy): 인터넷은 ISP들의 네트워크이고, 각 ISP들은 자신의 라우터들로 구성된 네트워크이다. 하나의 조직은 자신의 네트워크를 외부 네트워크에 연결하면서도, 자신이 원하는 대로 네트워크를 운영하고 관리할 수 있어야 한다.
이 두 문제는 라우터들을 자율 시스템(autonomous system, AS)으로 조직화하여 해결할 수 있다. 각 AS는 동일한 관리 제어하에 있는 라우터의 그룹으로 구성된다. AS는 전세계적으로 고유한 AS 번호(autonomous system number, ASN)로 식별된다. AS 번호는 IP 주소처럼 ICANN의 지역 등록 기관에 의해 할당된다. AS 내부에서 동작하는 라우팅 알고리즘을 AS 내부 라우팅 프로토콜(intra-autonomous system routing protocol)이라고 한다. OSPF, IS-IS, EIGRP 프로토콜 등이 이에 속한다.
5.3.1. 개방형 최단 경로 우선 프로토콜(Open Shortest Path First, OSPF)
Open은 라우팅 프로토콜에 대한 명세가 공개적으로 사용 가능함을 의미한다.
OSPF는 링크 상태 정보를 플러딩(flooding)하고 다익스트라 최소 비용 경로 알고리즘을 사용하는 링크 상태 알고리즘이다. 각 라우터는 자신을 루트 노드로 두고, 모든 서브넷에 이르는 최단 경로 트리를 결정하기 위해 다익스트라 알고리즘을 사용한다. 링크들의 비용은 관리자가 구성할 수 있다.
OSPF를 사용하는 라우터는 인접한 라우터만이 아니라, AS 내의 다른 모든 라우터에게 라우팅 정보를 브로드캐스트 한다. 링크 상태가 변경되거나, 정기적으로(예: 30분마다) 링크 상태 정보를 브로드캐스트 한다. 상태 정보는 IP에 의해 전달되므로, OSPF 프로토콜은 신뢰할 수 있는 메세지 전송과 브로드캐스트와 같은 기능을 스스로 구현해야 한다.
OSPF에 구현된 몇 가지 사항들은 다음과 같다. OSPF는 복잡한 프로토콜이며, 다른 추가 사항은 [RFC 238]에 있다.
(1) 보안: 인증을 통해 신뢰할 수 있는 라우터들만이 AS 내부의 OSPF 프로토콜에 참여할 수 있다. MD5 인증을 사용할 수 있다. 이는 모든 라우터에 설정된 공유 비밀키를 기반으로 한다.
각 OSPF 패킷에 대해서, 패킷 내용에 비밀키를 첨부한 후 MD5 해시를 계산한다. 이 해시 값이 포함된 패킷을 받은 라우터는, 미리 설정된 비밀키를 사용하여 패킷의 MD5 해시를 계산하고, 이를 패킷에 포함된 해시값과 비교하여 패킷을 인증한다. Replay attack을 방지하기 위해 순서 번호가 MD5 인증과 함께 사용된다.
(2) 복수 동일 비용 경로(Multiple same-cost paths): 동일한 비용을 가진 여러 개의 경로가 있을 때, 여러 개의 경로를 사용할 수 있다.
(3) 유니캐스트와 멀티캐스트 라우팅의 통합 지원: Multicast OSPF(MOSPF)는 멀티캐스트 라우팅 기능을 제공하기 위한 버전이다. OSPF 링크 상태 브로드캐스트 메커니즘에 새로운 형태의 링크 상태 알림을 추가하였다.
(4) 단일 AS내에서의 계층 지원: AS은 계층적인 영역으로 구성될 수 있다. 한 영역 내의 라우터는 같은 영역 내의 라우터들에게만 링크 상태를 브로드캐스트 한다. 각 영역의 하나 이상의 영역 경계 라우터(area border router)가 영역 외부로의 패킷 라우팅을 책임진다.
백본(backbone) 영역은 모든 영역 경계 라우터(+ 다른 라우터)를 포함한 영역이다. 패킷은 먼저 영역 경계 라우터로 가고, 백본을 통과하여 목적지 영역으로 라우팅된다.
5.4. 인터넷 서비스 제공업자 간의 라우팅: BGP(Routing Among the ISPs: BGP)
패킷을 여러 AS를 통과하도록 라우팅 할 때, 자율 시스템 간 라우팅 프로토콜(inter-autonomous system routing protocol)이 필요하다. 인터넷의 AS들은 경계 게이트웨이 프로토콜(Border Gateway Protocol)이라고 불리는 동일한 AS 간 라우팅 프로토콜을 사용한다. 일반적으로 BGP라고 알려져 있다.
5.4.1. BGP의 역활(The Role of BGP)
패킷의 목적지가 AS 외부에 있을 때 BGP가 필요하다. BGP에서는 패킷이 특정 목적지 주소를 향해서가 아니라, CIDR 형식으로 표현된, 주소의 앞쪽 접두부(prefix)를 향해 포워딩된다. 각 접두부는 서브넷이나 서브넷의 집합을 나타낸다.
라우터의 포워딩 테이블은 (x, I)와 같은 형식의 항목을 갖게 되는데, x는 주소 접두부(예: 138.16.68/22), I는 라우터 인터페이스의 인터페이스 번호이다.
BGP는 라우터에게 다음과 같은 수단을 제공한다. (1) 이웃 AS로부터 도달 가능한 서브넷 접두부 정보를 얻는다. 특히 BGP는 각 서브넷이 자신의 존재를 인터넷 전체에 알릴 수 있도록 한다.
(2) 서브넷 주소 접두부로의 가장 좋은 경로를 결정한다. 경로를 결정하기 위해 BGP의 경로 결정 프로시저를 수행한다. 경로는 도달 가능 정보뿐 아니라 정책에 기반해서 결정된다.
5.4.2. BGP 경로 정보 알리기(Advertising BGP Route Information)
각 AS의 라우터들을 게이트웨이 라우터 또는 내부 라우터이다. 게이트웨이 라우터는 다른 AS에 있는 하나 이상의 라우터와 직접 연결된다. 내부 라우터는 자신의 AS 내에 있는 호스트와 라우터와만 연결된다.
BGP에서 라우터의 쌍들은 반영구적인 TCP 연결을 통해 라우팅 정보를 교환한다. 이 연결은 BGP 연결이라고 불리고, 이를 통해 BGP 메세지가 전송된다.
그리고 두 개의 AS에 걸친 BGP 연결은 외부 BGP(external BGP, eBGP) 연결, 같은 AS 내의 BGP 연결은 내부 BGP(internal BGP, iBGP) 연결이라고 한다. 보통 게이트웨이 라우터들을 직접 연결하는 링크에는 eBGP 연결이 존재한다.
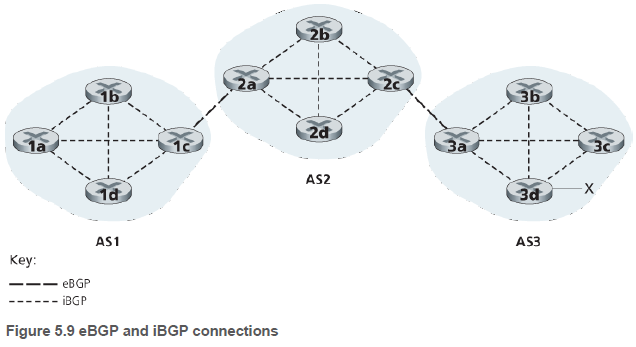
접두부 x에 대한 도달 가능성을 전파하기 위해 iBGP와 eBGP 연결이 모두 사용된다. 게이트웨이 라우터 s1이 인접 게이트웨이 라우터 s2에게 x가 s1 안에 존재한다고 eBGP 메세지를 통해 알린다.
s2는 iBGP 메세지를 통해 AS의 모든 라우터에게 x의 위치를 알린다. 주어진 라우터에서 목적지 서브넷까지 많은 경로가 있을 수 있다.
5.4.3. 최고의 경로 결정(Determining the Best Routes
BGP 연결을 통해 주소 접두부를 알릴 때, 몇몇 BGP 속성(BGP attributes)을 함께 포함한다. 중요한 속성 두 가지는 AS-PATH와 NEXT-HOP이다.
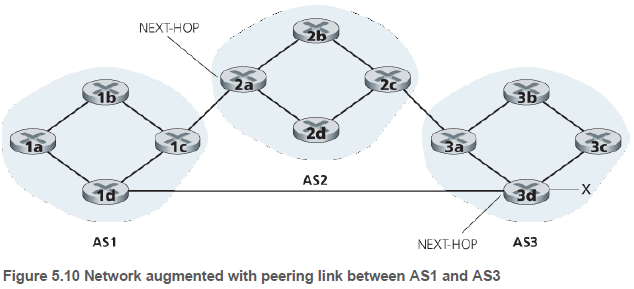
AS-PATH 속성에는 BGP 메세지가 통과하는 AS들의 리스트가 담는다. 이 속성은 메세지의 루프를 감지하는데 쓰일 수도 있는데, 경로 리스트에 자신의 AS가 있으면 메세지를 버린다.
NEXT-HOP 속성은 AS-PATH를 시작하는 라우터 인터페이스의 IP 주소이다. 경로 리스트의 시작이 AS1->AS2 일 때, AS2의 라우터 S1의 첫 번째 인터페이스로 가야한다면, 이 인터페이스 주소를 적는다.
다른 속성들도 있지만, 편의상 각 BGP 경로를 NEXT-HOP, AS-PATH, 목적지 주소 접두부, 이렇게 세 개의 구성요소의 리스트로 기술한다.
5.4.3.1. 뜨거운감자 라우팅(Hot Potato Routing)
가장 단순한 라우팅 알고리즘 중 하나인 뜨거운감자 라우팅에서 라우터는 경로 각각의 시작점인 NEXT-HOP 라우터까지의 경로 비용이 최소가 되는 경로를 선택한다. 그리고 자신의 포워딩 테이블로부터 최소 비용 게이트웨이로 가기 위한 인터페이스 I를 찾아낸다. 마지막으로 항목 (x, I)를 자신의 포워딩 테이블에 추가한다.
기본 아이디어는, 목적지까지의 경로 중 자신의 AS 바깥에 있는 부분에 대한 비용은 신경쓰지 않고, 최소의 비용으로 패킷을 자신의 AS 밖으로 내보내는 것이다.
5.4.3.2. 경로 선택 알고리즘(Route-Selection Algorithm)
목적지에 대해 두 개 이상의 경로가 존재한다면, BGP는 하나의 경로가 남을 때까지 다음의 규칙을 수행한다.
(1) 경로 속성에 지역 선호도(local preference)가 할당된다. 한 경로의 지역 선호도는 라우터에 의해 설정되었거나, 같은 AS 내부의 다른 라우터로부터 학습된 것이다. 지역 선호도의 값은 AS 네트워크 관리자에 의한 정책적인 결정(5.4.5절)이다. 가장 높은 지역 선호값을 가진 경로가 선택된다.
(2) 가장 높은 지역 선호값을 가진 경로가 여러개 있다면, 최단 AS-PATH를 가진 경로가 선택된다. 만약 이 규칙만이 경로 선택에 사용된다면, BGP는 DV 알고리즘을 사용할 것이다. 그리고 거리 값으로는 AS 홉 수를 사용한다.
(3) 남은 경로들에 대해 뜨거운감자 라우팅을 수행한다. NEXT-HOP 라우터까지의 거리가 가장 가까운 경로를 선택한다.
(4) 아직도 하나 이상의 경로가 남아 있다면, 라우터는 BGP 식별자를 사용하여 경로를 선택한다.
5.4.4. IP 애니캐스트(IP-Anycast)
BGP는 종종 DNS에서 흔히 사용되는 IP 애니캐스트 서비스를 구현하는 데도 활용된다. CDN 처럼 DNS 시스템도 DSN 레코드들을 전세계 DNS 서버에 복제할 수 있다. 이런 경우 사용자에게 가장 가까운 서버를 알려주는 것이 바람직하다.
CDN은 BGP 라우팅이 변경되면 하나의 TCP 연결에 속한 패킷들이 웹서버의 서로 다른 복제본으로 도착될 수 있기에, 일반적으로 애니캐스트를 사용하지 않는다. 하지만 애니캐스트를 설명하기 위한 예시로는 적절한하다.
예를 들어, CDN 사업자가 자신의 서버 각각에 동일한 IP 주소를 할당하고, BGP를 활용하여 이 주소를 알린다. BGP 라우터가 이 IP 주소에 대한 복수 개의 경로 알림 메세지를 받으면, 이를 동일한 물리적 위치로의 서로 다른 경로에 대한 정보를 제공받는 것 처럼 생각한다. (실제론 서로 다른 물리적 위치로의 서로 다른 정보이다.) 각 라우터는 BGP 경로 선택 알고리즘을 수행하여 해당 IP 주소로의 최고의 경로를 골라낸다.
사용자가 컨텐츠를 요청하면 CDN은 사용자가 어디에 위치해 있든 상관없이, 서버들이 공통적으로 사용하는 IP 주소를 사용자에게 돌려준다. 사용자가 그 주소로 요청을 보내면 라우터는 그 요청을 BGP 경로 선택 알고리즘이 정의한 가장 가까운 서버로 전달한다.
5.4.5. 라우팅 정책(Routing Policy)
라우터가 경로를 선택하려 할 때 AS 라우팅 정책은 다른 모든 고려사항보다 우선시된다. 즉, 지연 선호도 속성의 값이 AS의 정책에 의해 결정된다.
예제를 통해 BGP 라우팅 정책의 기본 개념을 알아본다. 그림 5.13에는 6개의 AS가 있다. W, X, Y는 액세스 ISP(access ISPs)이고, A, B, C는 백본 제공자 네트워크(backbone provider network)이다.
특히, X는 서로 다른 두 제공자를 통해 네트워크의 다른 부분들과 연결되어 있으므로, 다중 홈(multi-homed) 엑세스 ISP라고도 한다. A, B, C는 트래픽을 서로 직접 보내고, 그들의 사용자 네트워크에 완전한 BGP 정보를 제공한다.
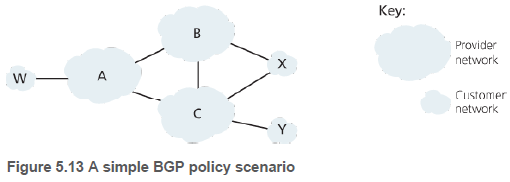
ISP 엑세스 네트워크(W, X, Y)로 들어오는 모든 트래픽은 그 네트워크를 목적지로 해야하며, ISP 엑세스 네트워크에서 나가는 트래픽은 그 네트워크 안에서 생성된 것이어만 한다.
이것은 BGP 경로의 알림 방식을 제어함으로써 수행된다. 예를 들어, X는 B와 C에게 자기 자신을 제외하고는 어떤 다른 목적지로도 경로가 없다고 알린다. X->C-Y의 경로가 있음에도 이 경로를 B에게 알리지 않는다. 따라서 B는 Y(또는 C)로 가야하는 트래픽을 절대 X로 포워딩하지 않을 것이다.
백본 제공자 네트워크들 사이의 경로를 결정하는 방법에 대한 공식적인 표준은 없다. 그러나 상업적 ISP들이 따르는 대략적인 규칙은 ISP 백본 네트워크를 통해 흐르는 트래픽은 해당 ISP의 고객 네트워크를 출발지로 하거나 목적지로 해야 한다는 것이다.
5.4.6. 조각 맞추기: 인터넷에서의 존재 획득(Putting the Pieces Together: Obtaining Internet Presence)
이 절은 IP 주소 지정, DNSS, BGP를 포함하여 개념을 한데 모은다.
회사를 설립하였고, 제품 설명용 웹 서버, 직원용 메일 서버, DNS 서버를 포함한 많은 서버들이 있다고 가정하자. 전 세계 사람들이 웹사이트를 방문할 수 있도록, 직원들이 고객들과 메일을 주고받을 수 있도록 하고 싶다고 하자.
이를 위해 먼저 지역 ISP와 계약하여 IP 주소 범위를 얻고 인터넷 연결을 해야 한다. 그리고 회사의 게이트웨이 라우터와 지역 ISP의 라우터를 연결한다. 물리적 연결과 IP 주소 범위를 얻으면 웹, 메일, DNS 서버 등에 IP 주소를 할당한다.
도메인 이름을 얻기 위해 인터넷 등록 기관과 계약을 한다. DSN 서버의 IP 주소를 등록 기관에 제공한다.
사용자가 웹 서버에 데이터그램을 보내면, 인터넷의 라우터는 어느 출력 포트로 내보내야 하는지 결정하기 위해 자신의 포워딩 테이블에서 해당 항목을 찾는다. 따라서 라우터는 회사의 주소 범위에 해당하는 IP 주소 접두부의 존재를 알고 있어야 한다. 이는 지역 ISP와 계약할 때, 지역 ISP가 BGP를 사용하여 인터넷 라우터들에게 알림으로써 해결된다.
5.5. 소프트웨어 정의 네트워크 제어 평면(The SDN Control Plane)
이 절에서는 네트워크의 포워딩 장비를 “패킷 스위치”(또는 스위치)라 한다.
SDN 구조의 네 가지 특징은 다음과 같다. (1) 플로우 기반 포워딩(Flow-based forwarding): 패킷 포워딩은 전송, 네트워크, 링크 계층의 헤더의 어떤 값들을 기반으로도 이루어질 수 있다. 패킷 포워딩 큐칙은 스위치의 플로우 테이블에 기록된다. SDN은 스위치들의 플로우 테이블 항목들을 계산, 관리, 설치한다.
(2) 데이터 평면과 제어 평면의 분리(Separation of data plane and control plane): 데이터 평면은 스위치들로 구성되고, 이들은 자신들의 플로우 테이블 내용을 기반으로 비교와 실행을 수행한다. 제어 평면은 서버와 스위치들의 플로우 테이블을 결정, 관리하는 소프트웨어로 이루어진다.
(3) 네트워크 제어 기능이 데이터 평면 스위치 외부에 존재(Network control functions: external to data-plane switches): 소프트웨어가 스위치에서 멀리 떨어진 별도의 서버에서 수행된다. 제어 평면은 SDN 컨트롤러와 네트워크 제어 응용들의 집합으로 이루어진다. 컨트롤러는 상태 정보(예: 스위치, 호스트 상태)를 유지하고, 이 정보를 제어 평면에서 동작하고 있는 네트워크 제어 응용들에 제공하며, 응용들이 하부 네트워크 장치들을 모니터하고 제어할 수 있는 수단을 제공한다.
(4) 프로그램이 가능한 네트워크(A programmable network): 네트워크 제어 응용을 통해 네트워크를 프로그램 할 수 있다. 이 응용들은 컨트롤러가 제공하는 API를 이용하여 네트워크 장비들에 있는데이터 평면을 명세하고 제어한다. 예를 들어, 응용은 경로 결정, 접근 제어, 부하 분산 등을 할 수 있다.
하드웨어와 시스템 소프트웨어, 그리고 응용의 분리는 이 세 분야에 개방된 생태계를 만들어냈다고 평가된다. 데이터 평면 스위치, SDN 컨트롤러, 네트워크 제어 응용 각각을 서로 다른 제조사에서 제공하는 것으로 구성할 수 있다.
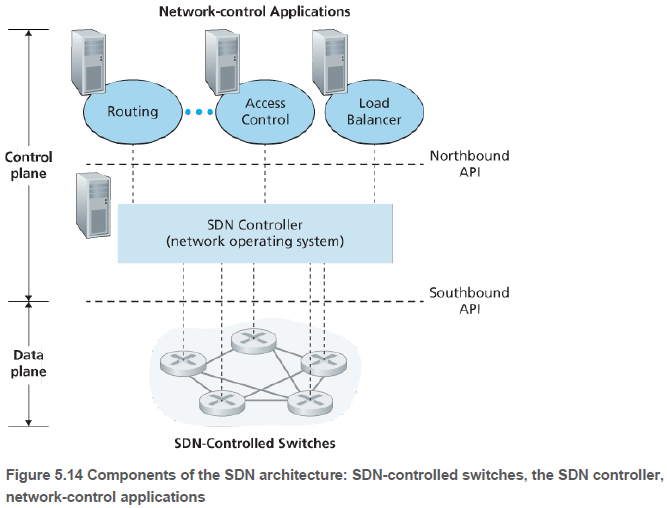
5.5.1. SDN 제어평면: SDN 컨트롤러와 SDN 네트워크 제어 응용들(The SDN Control Plane: SDN Controller and SDN Network-control Applications)
컨트롤러의 기능은 크게 세 개의 계층으로 구성된다.
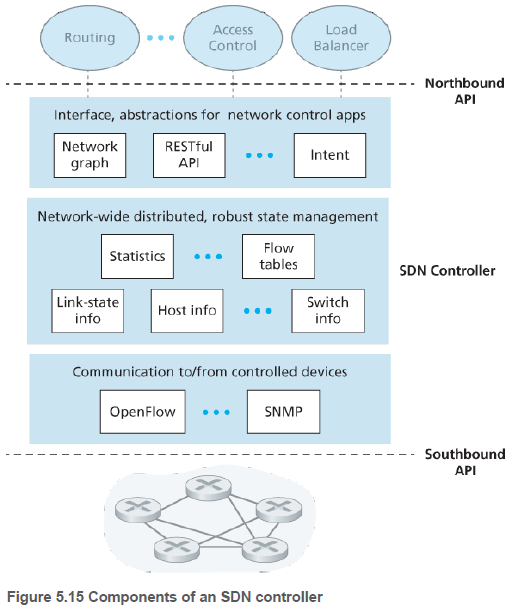
(1) 통신 계층(A communication layer): SDN 컨트롤러와 제어받는 네트워크 장치들 사이의 통신을 담당한다. 컨트롤러가 장치들의 동작을 제어하려면, 이들 사이에 정보를 전달하는 프로토콜이 필요하다. 그리고 장치는 이벤트(예: 연결된 링크 동작 시작/단절)들을 컨트롤러에 알릴 수 있어야 한다.
(2) 네트워크 전역 상태 관리 계층(A network-wide state-management layer): SDN 제어 평면의 제어 결정(예: 포워딩, 방화벽 등을 위해 스위치의 플로우 테이블을 설정하는 일)을 위해서는 컨트롤러가 장치들에 대한 최신 정보를 알아야 한다. 플로우 테이블 복사본 등 네트워크 상태 정보들을 유지한다.
(3) 네트워크 제어 응용 계층과의 인터페이스(The interface to the network-control application layer): 컨트롤러는 노스바운드(northbound) 인터페이스를 통해 네트워크 제어 응용들과 상호 작용한다. 이 API는 응용들이 상태 관리 계층 내의 상태 정보와 플로우 테이블을 읽고 쓸 수 있게 해준다. 응용들은 상태 변화 이벤트가 발생하면 알려달라고 등록해 두고, 장치들에서 이벤트 알림이 오면 적절한 조치를 취할 수 있다.
5.5.2. 오픈플로우 프로토콜
오픈플로우 프로토콜은 SDN 컨트롤러와 SDN으로 제어되는 스위치 또는 오픈플로우 API를 구현하는 다른 장치와의 사이에서 동작한다.
컨트롤러에서 스위치에서 전달되는 메세지들은 다음과 같다.
- 설정: 스위치의 설정 파라미터들을 문의하거나 설정할 수 있다.
- 상태 수정: 스위치의 플로우 테이블 항목을 추가/제거/수정하거나, 스위치의 포트 특성을 설정한다.
- 상태 읽기: 스위치 플로우 테이블로부터 통계 정보와 카운터 값을 얻는다.
- 패킷 전송: 스위치의 지정된 포트에서 특정 패킷을 내보내기 위해 사용된다. 페이로드 부분에 보낼 패킷을 포함한다.
스위치에서 컨트롤러로 전달되는 메세지들은 다음과 같다.
- 플로우 제거: 어떤 플로우 테이블의 항목이 시간이 만료되었거나, 상태 수정 메세지의 결과로 삭제되었음을 알린다.
- 포트 상태: 포트의 상태 변화를 알린다.
- 패킷 전달: 스위치 포트에 도착한 패킷 중에서 플로우 테이블의 어떤 항목과도 일치하지 않은 패킷의 처리를 위해 컨트롤러에게 전달한다. 일치한 패킷 중에서도 일부는 추가 작업을 수행하기 위해 컨트롤러에게 보내지기도 한다.
5.5.3. 데이터 평면과 제어 평면의 상호 작용: 예제(Data and Control Plane Interaction: An Example)
라우팅 알고리즘이 모든 라우터에 구현되고, 링크 상태 업데이트 정보가 라우터 사이에서 플러딩 되는 라우터별 제어에서는 라우팅 알고리즘이 바뀌면 모든 라우터의 소프트웨어를 바꿔야 한다.
SDN에서는 단순히 응용 제어 소프트웨어를 바꿈으로써 원하는 형태의 포워딩 방식을 구현할 수 있다.
예시 시나리오는 다음과 같다.
- 스위치에 링크 단절이 감지되면, 오픈플로우의 포트 상태 메세지를 사용하여 링크 상태의 변화를 SDN 컨트롤러에게 알린다.
- 컨트롤러는 링크 상태 관리자에게 알리고, 관리자는 링크 상태 데이터베이스를 갱신한다.
- 링크 상태 라우팅을 담당하는 네트워크 제어 응용은 링크 상태 변화에 대한 알림을 받는다.
- 응용이 링크 상태 관리자와 접촉하여 갱신된 링크 상태를 가져온다. 그 후 새로운 최소 비용 경로를 계산한다.
- 응용은 갱신되어야 할 플로우 테이블을 결정하는 플로우 테이블 관리자와 접촉한다.
- 테이블 관리자는 오픈플로우 프로토콜을 사용하여 링크 상태 변화에 영향을 받는 스위치들의 플로우 테이블을 갱신한다.
5.5.4. SDN: 과거와 미래(SDN: Past and Future)
과거 에탄(Ethane) 프로젝트[Casado 2007]는 오픈플로우 프로젝트 빠르게 진화하였다.
미래의 SDN 아키텍처와 기능을 개발하기 위해 많은 연구 노력이 이루어지고 있다. 네트워크 기능 가상화(NFV)로 알려진 SDN의 일반화는 단순한 상용 서버, 스위칭 및 저장소를 가진 복잡한 미들박스(전용 하드웨어 및 미디어 캐싱/서비스를 위한 고유의 소프트웨어를 가진 미들박스)를 혁신적으로 교체하는 것을 목표로 한다.
5.6. 인터넷 제어 메세지 프로토콜(ICMP: The Internet Control Message Protocol)
인터넷 제어 메세지 프로토콜은 호스트와 라우터가 서로 간에 네트워크 계층 정보를 주고받기 위해 사용된다. 예를 들어, “목적지 네트워크에 도달할 수 없음” 같은 오류 메세지가 있다.
ICMP 메세지는 IP 페이로드로 전송된다. 메세지에는 타입과 코드 필드가 있고, 메세지가 처음 생성되도록 한 IP 데이터그램의 헤더와 첫 8바이트를 가진다(송신자가 오류를 발생시킨 패킷을 식별할 수 있도록 하기 위해).
오류 상태, 에코 응답, 출발지 억제(혼잡제어), TTL 만료 등을 알리기 위해 사용된다. 라우터, 호스트 등이 메세지를 보낼 수 있다.
5.7. 네트워크 관리와 SNMP(Network Management and SNMP)
이 절에서는 네트워크 관리의 기초, 네트워크 관리에 사용되는 구조, 프로토콜, 정보 저장소만을 다룬다. 장애 식별, 이상 발생 탐지, 의사 결정 프로세스 등은 포함되지 않았다.
5.7.1. 네트워크 관리 프레임워크(The Network Management Framework)
네트워크 관리의 핵심 요소들은 다음과 같다.
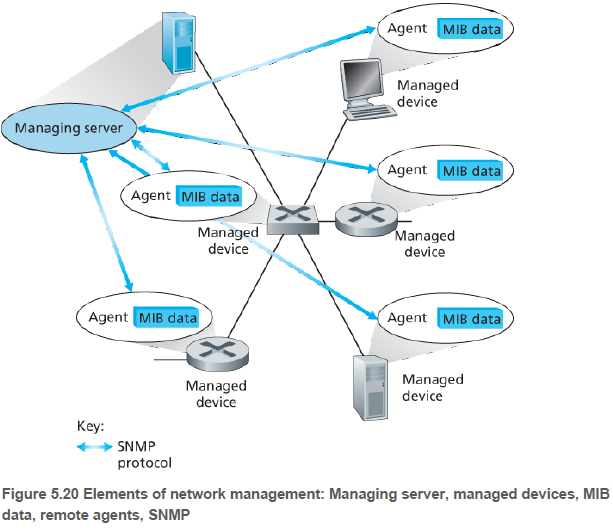
(1) 관리 서버(managing server)는 일반적으로 사람과 상호 작용하는 응용이다. 네트워크 관리 활동이 일어나는 장소로서, 관리 정보의 수집, 처리, 분석 등을 제어한다. 여기서 네트워크 동작을 제어하기 위한 작업이 시작되며, 네트워크 관리자는 네트워크 장치들과 상호 작용한다.
(2) 피관리 장치(managed device)는 관리 대상 네트워크에 존재하는 네트워크 장비(소프트웨어 포함)들이다. 장치 내부에는 피관리 객체(managed object)라고 불리는 것들이 있다. 이는 피관리 장치 내부의 하드웨어 일부(예: 네트워크 인터페이스 카드는 호스트나 라우터의 하나의 구성요소이다.), 그리고 하드웨어와 소프트웨어 요소에 대한 설정 매개변수들이다.
(3) 피관리 객체에 관련된 정보들은 MIB(Management Information Base)에 저장된다. 이 정보들은 관리 서버에서 이용될 수 있고, 버려지는 IP 데이터그램의 개수, 소프트웨어 버전, 상태 정보 등 여러 정보가 담겨질 수 있다.
(4) 각 피관리 장치에는 네트워크 관리 에이전트(network management agent)가 있다. 이는 관리 서버와 통신하면서, 관리 서버의 제어에 따라 피관리 장치에 행동을 취하는 프로세스이다.
(5) 네트워크 관리 프로토콜(network management protocol)은 관리 서버와 피관리 장치들 사이에서 동작하면서, 네트워크 관리자가 네트워크를 관리(테스트, 설정, 분석 등)할 수 있도록 도구를 제공한다.
5.7.2. The Simple Network Management Protocol (SNMP)
SNMP는 관리 서버와 에이전트 사이에서 네트워크 관리 제어 및 정보 메세지를 전달하기 위해 사용된다. SNMP의 가장 흔한 사용 형태는 요청-응답 모드(request-response mode)이다.
관리 서버가 에이전트에게 MIB 객체 값 질의/수정 등을 하고 응답 받는다. 다른 형태는 에이전트가 예외 상황(링크 인터페이스 활성/비활성화)를 알리기 위해 트랩 메세지(trap message)를 서버에 보내는 것이다.
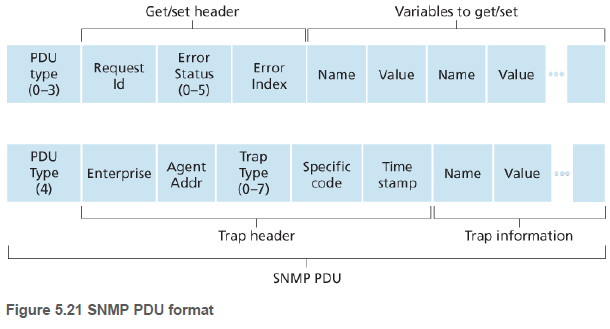
SNMP는 PDUs(protocol data units)로 알려진 여러 타입의 메세지를 정의한다. MIB 객체 값 가져오기, 설정하기 등이 있다.
댓글남기기