컴퓨터 네트워킹 요약 - 4. 네트워크 계층: 데이터 평면
4.1. 네트워크 계층 개요(Overview of Network Layer)
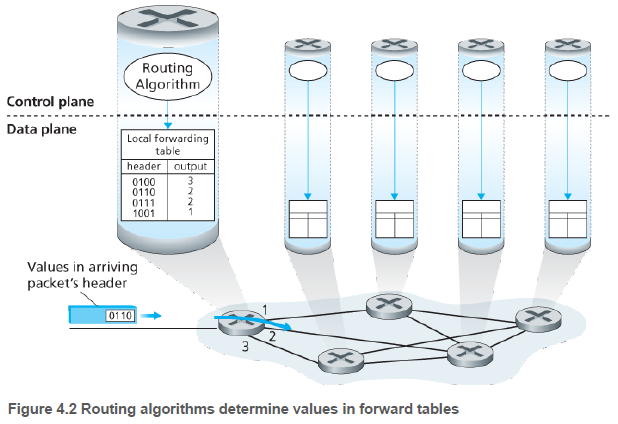
4.1.1. 포워딩과 라우팅: 데이터 평면과 제어 평면(Forwarding and Routing: The Data and Control Planes)
네트워크 계층은 송신 호스트에서 수신 호스트로 패킷을 전달하는 것이다. 네트워크 계층의 중요 기능은 다음과 같다.
- 포워딩(Forwarding): 패킷이 라우터의 입력 링크에 도달했을 때, 그 패킷을 적절한 출력 링크로 이동시켜야 한다.
- 라우팅(Routing): 패킷 경로를 결정해야 한다. 경로를 계산하는 알고리즘을 라우팅 알고리즘(routing algorithm)이라 한다.
포워딩은 짧은 시간(몇 나노초)단위를 갖기에 보통 하드웨어에서 실행된다. 반면에, 라우팅은 데이터그램의 출발지-목적지 경로를 결정하는데 더 긴 시간(보통 초)단위를 갖기에 보통 소프트웨어에서 실행된다.
라우터에는 포워딩 테이블(forwarding table)이 있다. 라우터는 패킷 헤더의 필드 값을 조사하여 패킷을 포워딩한다. 이 값을 포워딩 테이블의 내부 색인으로 사용한다.
4.1.1.1. 제어 평면: 전통적인 접근(Control Plane: The Traditional Approach)
라우팅 알고리즘은 포워딩 테이블의 내용을 결정한다. 라우터의 라우팅 알고리즘은 다른 라우터의 라우팅 알고리즘과 소통하며 포워딩 테이블의 값들을 계산한다(5.2~5.4절 내용).
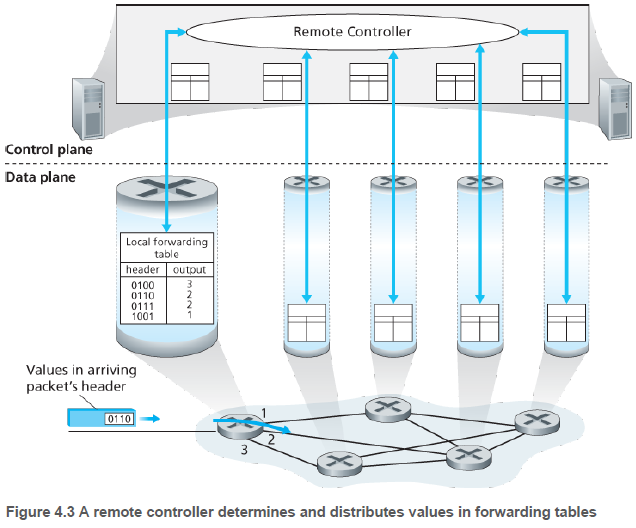
4.1.1.2. 제어 평면: SDN 접근(Control Plane: The SDN Approach)
원격제어가 포워딩 테이블을 계산과 배분하는 동안 라우팅 기기는 포워딩만을 수행하는 제어 평면적 접근 SDN(software defined networking)도 있다. 원격 컨트롤러가 신뢰성과 중복성을 갖춘 원격 데이터 센터에 설치될 수 있으며, 라우터와 메세지를 교환함으로써 소통할 수 있다. 네트워크가 소프트웨어적으로 정의되었을 때, 포워딩 테이블을 계산하는 컨트롤러는 라우터와 상호작용을 하여 소프트웨어에서 실행된다.
4.1.2. 네트워크 서비스 모델(Network Service Model)
네트워크 계층에서 제공할 수 있는 서비스들의 일부는 다음과 같다. 이 외에 수많은 변형들이 있다.
- 보장된 전달: 패킷이 출발지에서 목적지까지 도착하는 것을 보장한다.
- 지연 제한 이내의 보장된 전달: 패킷의 전달 보장뿐만 아니라 호스트간의 특정 지연 제한 안에 전달한다.
- 순서화(in-order) 패킷 전달: 패킷이 목적지에 송신된 순서로 도착하는 것을 보장한다.
- 최소 대역폭 보장: 송신과 수신 호스트 사이에 특정한 비트 속도의 전송 링크를 에뮬레이트(emulates)한다. 송신 호스트가 비트를 특정한 비트 속도 이하로 전송하는 한, 모든 패킷이 수신 호스트까지 전달된다.
- 보안(security): 데이터그램을 송신 호스트에서는 암호화, 수신 호스트에서는 해독을 할 수 있게 한다.
인터넷의 네트워크 계층은 최선형 서비스(best-effort service)라고 알려진 서비스를 제공한다. 이는 패킷 순서, 전송, 지연, 최소 대역폭을 보장하지 않는다.
다른 여러 네트워크 구조는 최선형 서비스보다 좋은 서비스 모델을 정의하고 구현하였다. 예를 들어, ATM 네트워크 구조는 패킷 순서, 지연, 최소 대역폭을 보장한다. 그럼에도 최선형 서비스 모델은 많은 애플리케이션에 “충분히 좋다”라고 입증되고 있다.
4.2. 라우터 내부에는 무엇이 있을까?(What’s Inside a Router?)
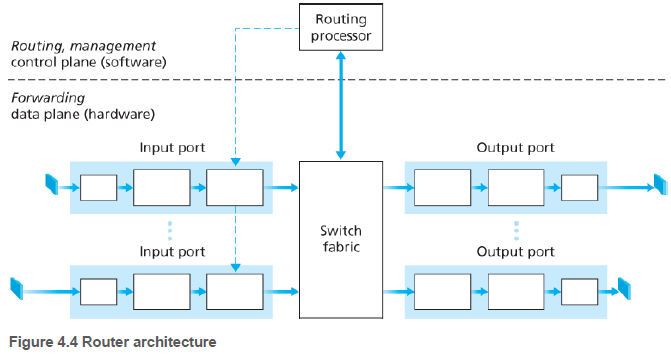
라우터의 네가지 요소를 다음과 같이 정의한다. 여기서 포트라는 용어는 물리적인 입출력 라우터 인터페이스를 의미한다. 애플리케이션 및 소켓과 관련된 포트와는 다르다.
(1) 입력 포트: 입력 포트는 입력 링크의 물리 계층 기능, 입력 링크의 반대편에 있는 링크 계층과 상호 운용하기 위해 필요한 링크 계층 기능을 수행한다. 그리고 검색 기능을 수행하는데, 이는 포워딩 테이블을 참조하여 패킷이 스위칭 구조를 통해 전달되는 라우터 출력 포트를 결정한다. 제어패킷(예: 라우팅 프로토콜 정보를 전달하는 패킷)은 입력 포트에서 라우팅 프로세서로 전달된다.
(2) 스위칭 구조: 스위칭 구조는 입력 포트와 출력 포트를 연결한다. 스위칭 구조는 라우터 내부에 포함되어 있다.
(3) 출력 포트: 출력 포트는 스위칭 구조에서 수신한 패킷을 저장하고, 필요한 링크 계층 및 물리적 계층 기능을 수행하여 출력 링크로 패킷을 전달한다. 링크가 양방향일 때, 출력 포트는 일반적으로 동일한 링크의 입력 포트와 한 쌍을 이룬다.
(4) 라우팅 프로세서: 라우팅 프로세서는 제어 평면 기능을 수행한다. 기존의 라우터에선느 라우팅 프로토콜을 실행하고, 라우팅 테이블과 연결된 링크 상태 정보를 유지 관리하며 포워딩 테이블을 계산한다. SDN 라우터에서는 원격 컨트롤러와 통신하여, 원격 컨트롤러에서 계산된 포워딩 테이블 항목을 수신하고 입력 포트에 이 항목을 설치한다.
라우터의 입력 포트, 출력 포투, 스위칭 구조는 보통 하드웨어로 구현된다. 10Gbps 입력 링크와 64바이트 IP 데이터그램을 생각해보면, 입력 포트는 다른 데이터 그램이 오기 전에 도착한 데이터 그램을 처리하는 데 51.2 ns 밖에 시간이 없다. 더군다나 N개의 포트가 회선 카드(line card)에 결합되어 있으면, 데이터그램-처리 파이프라인은 N배 더 빨라져야 한다. 이는 소프트웨어로 구현하기에는 힘들 정도로 빠른 요구 속도이다.
반면 라우터의 제어기능(라우팅 프로토콜 실행-SDN의 경우 원격 컨트롤러와 소통, 관리 기능 수행 등)은 밀리초나 초 단위로 수행된다. 따라서, 이러한 제어 평면 기능들은 보통 소프트웨어로 구현되며 라우팅 프로세서(보통 일반적인 CPU)에서 실행된다.
4.2.1. 입력 포트 처리 및 목적지 기반 전달(Input Port Processing and Destination-Based Forwarding)
포워딩 테이블은 라우팅 프로세서에서 계산되거나 원격 SDN 컨트롤러에서 수신된다. 포워딩 테이블은 그림 4.4의 입력 회선 카드로 복사되어, 패킷 마다 라우팅 프로세서를 호출할 필요가 없어진다.
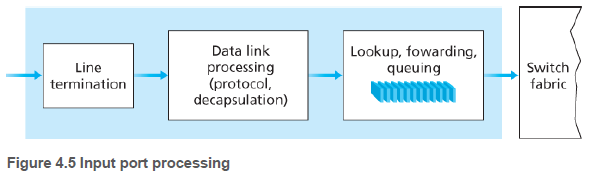
패킷이 32비트 IP 목적지 주소를 갖고, 4개의 링크가 있다고 하자. 그러면 아래와 같이 링크 인터페이스를 결정할 수 있다.
목적지 주소 범위 링크 인터페이스
11001000 00010111 00010000 00000000
~ 0
11001000 00010111 00010111 11111111
11001000 00010111 00011000 00000000
~ 1
11001000 00010111 00011000 11111111
11001000 00010111 00011001 00000000
~ 2
11001000 00010111 00011111 11111111
그 외 3
프리 픽스 링크 인터페이스
11001000 00010111 00010 0
11001000 00010111 00011000 1
11001000 00010111 00011 2
그 외 3
포워딩 테이블에서 라우터는 패킷의 목적지 주소의 프리픽스(prefix)를 테이블의 항목과 대응시킨다. 만약 앞 3개의 엔트리에 대응되지 않으면 최장 프리픽스 매칭 규칭(longest prefix matching rule)을 적용한다. 테이블에서 가장 긴 대응 항목을 찾고, 이에 대응된 링크 인터페이스로 패킷을 보낸다. (4.3절 내용)
프리픽스를 빠르게 찾기 위해, 빠른 검색 알고리즘(lookup algorithms), 내장형 DRAM과 빠른 SRAM, TCAM(Ternary Content Addressable Memories) 등이 활용된다. 검색을 통해 패킷의 출력 포트가 결정되면 패킷을 스위칭 구조로 보낼 수 있다.
4.2.2. 변환기(Switching)
스위칭 구조를 통해 패킷이 입력 포트에서 출력 포트로 전달된다.
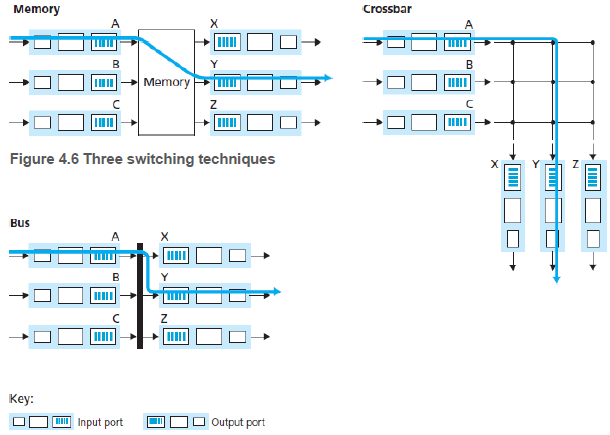
(1) 메모리를 통한 교환: 패킷이 도착하면, 입력 포트는 라우팅 프로세서에게 인터럽트를 보내 패킷을 프로세서 메모리에 복사한다. 그 다음 라우팅 프로세서는 헤더에서 주소를 추출하고 포워딩 테이블에서 출력 포트를 찾은 다음, 패킷을 출력 포트의 버퍼에 복사한다. 목적지 포트가 다른 경우라도 공유 시스템 버스를 통해 한 번에 하나의 메모리 읽기/쓰기 작업을 할 수 있기 때문에 두 패킷을 동시에 전달할 수 없다.
최근 라우터는 회선 카드에서 이를 처리한다. 회선 카드에서 패킷을 처리하고 출력 포트의 메모리에 스위칭(쓰기)한다.
(2) 버스를 통한 교환: 입력 포트가 라우팅 프로세서의 개입 없이 공유 버스를 통해 직접 출력 포트로 패킷을 전송한다. 이는 일반적으로 입력 포트가 출력 포트를 가르키는 스위치 내부 라벨/헤더(switch-internal label(header))을 패킷에 붙이고, 패킷을 버스에 보냄으로써 수행된다. 모든 출력 포트이 패킷을 수신하지만, 라벨과 일치하는 포트만 패킷의 라벨을 제거하고 유지한다.
한번에 하나의 패킷만 버스를 통과할 수 있기 때문에, 다른 패킷들은 대기해야 한다.
(3) 인터커넥션 네트워크(interconnection network)를 통한 교환: 크로스바(crossbar) 스위치가 사용된다. 각 수직 버스는 교차점에서 각 수평 버스와 교차하며, 스위치 구조 컨트롤러에 의해 언제든지 열거나 닫을 수 있다.
크로스바 스위치에서 다른 출력 포트로 보내지는 패킷들은 병렬적으로 전달될 수 있다.
이 외에도 다단계 스위칭 구조, 3단계 논 블록킹(non-blocking) 등 여러 방식이 있다.
4.2.3. 출력 포트 프로세싱(Output Port Processing)
출력 포트 프로세싱은 출력 포트의 메모리에 저장된 패킷을 가져와 출력 링크를 통해 전송한다. 패킷 선택 및 대기열 제거(de-queueing packets), 필요한 링크 계층 및 물리 계층 전송 기능을 수행한다.
4.2.4. 어디에서 큐잉이 일어날까?(Where Does Queuing Occur?)
패킷 큐는 입력 포트와 출력 포트 모두에서 형성될 수 있다.
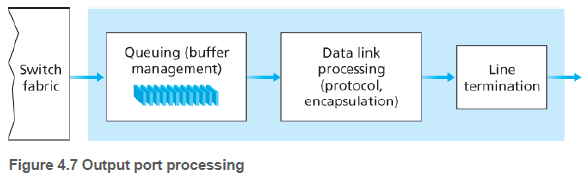
4.2.4.1. 입력 큐잉(Input Queueing)
스위칭 구조 전송속도가 입력 회선 속도에 비해 느리면, 패킷이 스위칭 구조를 통해 출력 포트로 전송되기 위해서 차례를 기다려야 한다. 각 입력 포트의 앞쪽 패킷들이 같은 출력 포트로 가려고 하면 대기해야 한다.
또한 경쟁없는 다른 출력 포트로 가려하는 뒤쪽 패킷들도 앞쪽 패킷이 사라질 때까지 기다려야 한다. 이 현상을 HOL(head-of-the-line) 차단이라고 한다.
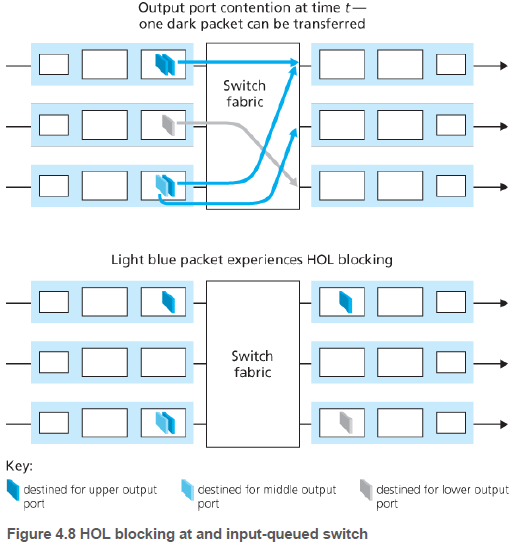
4.2.4.2. 출력 큐잉(Output Queueing)
N개의 입력 포트에서 스위칭 구조 전송속도가 입력 회선 속도보다 N배 빠른 경우에도 출력 포트에서 패킷 큐잉이 발생할 수 있다. 대기 중인 패킷의 수가 출력 포트에서 사용 가능한 메모리보다 많아질 수 있다. 예를 들어, 계속 N개의 패킷이 동시에 들어와 하나의 출력 패킷으로 들어갈 수도 있다.
메모리가 충분하지 않을 때, 들어오는 패킷을 폐기(drop-tail 정책)하거나 큐에 있는 패킷을 삭제할 수 있다. 혹은 큐가 가득차기 전에, 패킷을 폐기하거나 헤더에 기록(mark)하여 송신자에게 혼잡 상태를 알릴 수도 있다.
4.2.5. 패킷 스케줄링(Packet Scheduling)
큐에 있는 패킷을 출력 링크를 통해 전송하는 순서를 결정하는 방법이 있다.
4.2.5.1. First-in-First-Out(FIFO)
First-come-First-served(FCFS) 라고도 알려진 FIFO는 출력 링크 큐에 도착한 순서와 동일한 순서로 출력 링크에서 전송할 패킷을 선택한다.
4.2.5.2. 우선순위 큐잉(Priority Queuing)
패킷은 우선순위 클래스로 분류된다. 예를 들어, 네트워크 관리 정보, 실시간이 필요한 패킷은 높은 우선순위를 받을 수 있다. 각 우선순위 클래스에 큐가 있으며, 동일한 우선순위 패킷들은 일반적으로 FIFO방식이 행해진다.
4.2.5.3. 라운드 로빈과 WFQ(Round Robin and Weighted Fair Queuing (WFQ))
패킷은 우선순위 큐잉과 같이 클래스로 분류된다. 그러나 클래스간 우선순위가 없고, 스케줄러가 클래스 간에 서비스를 번갈아서(예: 1, 2, 1, …) 제공한다.
작업 보존(work-conserving) 큐잉 규칙은 라운드 로빈과 아래 나올 WFQ에도 사용된다. 차례가 된 클래스에 패킷이 없다면, 다음 클래스로 바로 넘어간다.
WFQ는 라운드 로빈과 유사하지만, 각 클래스에 가중치를 준다. 각 클래스마다 다른 양의 서비스 시간을 부여할 수 있다.
4.3. 인터넷 프로토콜(IP): IPv4, 주소지정, IPv6 등(The Internet Protocol(IP): IPv4, Addressing, IPv6, and More)
4.3.1. IPv4 데이터그램 형식(IPv4 Datagram Format)
IP 데이터그램은 총 20바이트의 헤더(옵션 없을 시)를 갖는다. 데이터그램이 TCP 세그먼트를 전송한다면, 총 40바이트의 헤더(IP 헤더 20, TCP 헤더 20)를 전송한다.
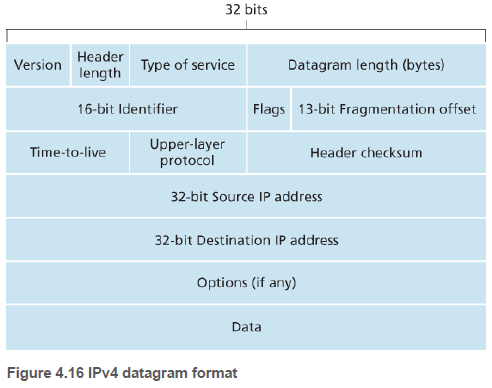
(1) 버전 번호: IP 프로토콜 버전을 명시한다.
(2) 헤더 길이: 헤더에 가변 길이의 옵션을 포함하므로, IP 데이터그램에서 실제 페이로드(payload, 예: 데이터그램에 캡슐화된 세그먼트)가 시작하는 곳을 결정한다.
(3) 서비스 타입: Type of service(TOS) 비트는 서로 다른 유형의 IP 데이터그램을 구별한다. 예를 들어 실시간 데이터그램(전화, 통신 등)과 비실시간 트래픽(FTP)을 구분하는 데 유용하다.
(4) 데이터그램 길이: 바이트로 계산한 IP 데이터그램(헤더와 데이터)의 전체 길이이다.
(5) 식별자, 플래그, 단편화 오프셋(4.3.2절 내용): IP 단편화에 사용된다. IPv6는 단편화를 허용하지 않는다.
(6) TTL(Time-to-live): 네트워크에서 데이터그램이 무한히 순환하지 않도록 한다. 이 필드 값은 라우터가 데이터그램을 처리할 때마다 감소하며, 0이 되면 데이터그램이 폐기된다.
(7) 프로토콜: 데이터그램이 최종 목적지에 도착했을 때만 사용된다. 이 필드 값은 데이터 부분이 전달될 목적지의 전송 계층 프로토콜을 명시한다. 예를 들어, 6은 데이터를 TCP로, 17은 UDP로 전달하라는 의미이다.
(8) 헤더 체크섬: IP 헤더만을 체크섬하여 오류를 검사한다. 보통 오류가 검출된 데이터그램은 라우터에서 폐기된다.
(9) 출발지와 목적지 IP주소: 출발지가 데이터그램을 생성할 때, 출발지와 목적지 IP 주소를 넣는다.
(10) 옵션: 오버헤드, 처리 시간 등의 이유로 거의 사용되지 않는다. 따라서 IPv6에 포함되지 않았다.
(11) 데이터(페이로드, payload): 대부분 전송 계층 세그먼트이나 ICMP 메세지(5.6절)와 같은 다른 유형의 데이터도 담긴다.
4.3.2. IPv4 데이터그램 단편화(Pv4 Datagram Fragmentation)
(6장 내용) 서로 다른 링크 계층 프로토콜들은 전달할 수 있는 최대 데이터그램 크기가 다를 수 있다. 예를 들어, 이더넷 프레임은 최대 1,500바이트, 광역 링크 프레임은 576바이트가 최대 크기이다. 링크 계층 프레임이 전달할 수 있는 최대 데이터 양을 MTU(maximum transmission unit)라 부른다.
데이터그램은 한 라우터에서 다른 라우터로 전송되기 위해 링크 계층 프레임 내에 캡슐화된다. 그런데, 송신자와 목적지 간의 경로의 각 링크가 다른 링크 계층 프로토콜을 사용하여(서로 다른 MTU를 가져), 데이터그램 크기에 따라 문제가 생길 수 있다.
해결책은 IP 데이터그램의 페이로드를 더 작은 IP 데이터그램으로 분할하여 전송하는 것이다. 이러한 작은 데이터그램을 조각(fragment, 단편)이라고 한다.
목적지 호스트는 같은 출발지로부터 일련의 데이터그램을 수신하면, 이를 결합한다. IP 데이터그램의 식별자, 플래그, 단편화 오프셋이 이에 사용된다.
송신자는 일반적으로 보내는 데이터그램마다 식별자 번호를 증가시킨다. 수신자는 식별자 번호를 통해 어느 원본의 데이터그램 조각인지 판단한다.
그리고 데이터그램의 마지막 조각은 플래그 비트가 0, 나머지 조각은 1인것으로 알 수 있다. 오프셋은 조각이 분실되었는지와 재결합 순서를 위해 사용된다.
4.3.3. IPv4 주소체계(IPv4 Addressing)
호스트는 일반적으로 네트워크와 연결되는 하나의 링크를 가지고, 이를 통해 데이터그램을 보낸다. 호스트와 물리적 링크 사이의 경계를 인터페이스(interface)라고 부른다.
라우터는 한 링크로부터 데이터그램을 수신하여 다른 링크로 전달하므로, 2개 이상의 연결된 링크를 가진다. 라우터와 링크 사이의 경계 또한 인터페이스라 하는데, 각 링크마다 하나의 인터페이스를 가지므로 라우터는 여러 개의 인터페이스를 가진다.
모든 호스트와 라우터는 데이터그램을 송수신할 수 있으므로, IP는 각 인터페이스가 IP 주소를 갖도록 요구한다. 따라서 기술 면에서 IP 주소는 인터페이스를 포함하는 호스트, 라우터보다는 인터페이스와 관련이 있다.
각 IP주소는 32비트 길이(4바이트)이다. 일반적으로 각 바이트를 십진수로 표현하고 바이트를 점(.)으로 구분하는 십진 표기법(dotted-decimal notation)을 사용한다. 예를 들어, 193.32.216.9이 있으며 이진수로는 아래와 같다.
11000001 00100000 11011000 00001001
모든 인터페이스는 고유한 IP 주소를 갖는다(4.3.4절 NAT 뒤의 인터페이스 예외). 주소는 마음대로 선택할 수 없고, 주소의 일부는 연결된 서브넷(subnet)이 결정한다.
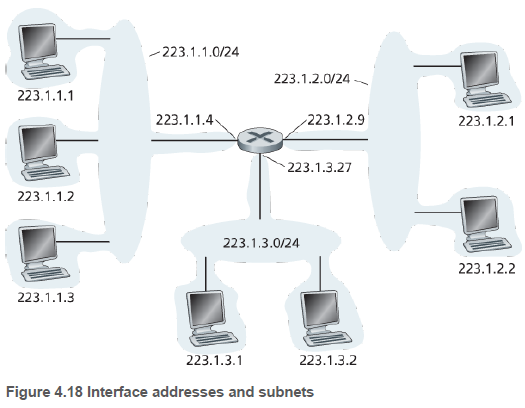
그림에서 왼쪽 3개의 호스트와 연결된 라우터 인터페이스는 모두 223.1.1.xxx 형식의 IP 주소를 갖는다. 즉, 동일한 왼쪽 24비트를 사용한다.
또한 4개의 인터페이스가 중계하는 라우터 없이 (이더넷 LAN 혹은 무선 엑세스포인트로, 6, 7장 내용) 하나의 네트워크에 서로 연결되어 있다. IP 용어로 이 네트워크는 서브넷을 구성한다고 말한다.
IP 주소체계는 이 서브넷에 223.1.1.0/24 라는 주소를 할당하는데, 여기서 /24 는 서브넷 마스크(subnet mask)라 부른다. 이는 32비트 주소의 왼쪽 24비트가 서브넷 주소라는 것을 가리킨다. 네트워크 223.1.1.0/24에 새로 부착할 호스트에는 223.1.1.xxx 형식의 주소가 필요할 것이다.
서브넷의 IP 정의는 여러 호스트가 라우터 인터페이스에 연결된 것만을 의미하지는 않는다. 일반적인 라우터와 호스트를 연결한 시스템에서 서브넷을 정의하기 위해 다음과 같은 방법을 사용할 수 있다.
서브넷을 결정하려면, 호스트나 라우터에서 인터페이스를 분리하고, 고립된 네트워크를 만든다. 이 고립된 네트워크의 종단점은 인터페이스의 끝이 된다. 이렇게 고립된 네트워크 각각을 서브넷이라고 한다.
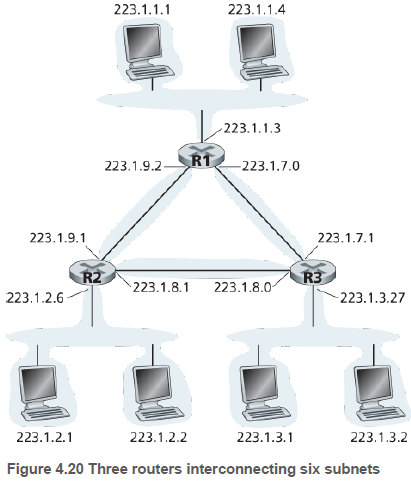
위 그림처럼 호스트들-라우터 3개 외에 라우터-라우터 3개, 총 6개의 고립된 서브넷을 가질 수 있다.
인터넷 주소 할당 방식에는 CIRD(Classless Interdomain Routing)이 있다. 서브넷 주소 체계로서, 32비트 IP 주소를 두 부분으로 나눈다. a.b.c.d/x 에서 x는 첫 부분의 비트 수이다.
a.b.c.d/x 에서 x는 최상위 비트(most significant bit, MSB)를 의미하며, 이를 해당 주소의 프리픽스(prefix) 또는 네트워크 프리픽스라고 부른다. 한 기관은 통상 공통 프리픽스를 갖는 주소 범위의 블록을 할당받는다.
이 경우 기관 장비들의 IP 주소는 공통 프리픽스를 공유한다. 외부 기관의 라우터는 목적지 주소가 내부 기관인 데이터그램을 전달할 때, 단지 앞의 x비트들만 고려한다. 이런 방식은 라우터의 포워딩 테이블 크기를 줄여준다.
주소의 나머지 32-x 비트들은 기관 내부의 장비들을 구별한다. 이 비트들은 기관 내부의 라우터에서 패킷을 전달할 때 사용된다. 이 하위 비트들은 추가 서브넷 구조를 가질 수도 있다.
IP 주소 중 브로드캐스트(broadcast) 주소 255.255.255.255 가 있다. 목적지 주소가 이와 같으면, 데이터그램은 같은 서브넷에 있는 모든 호스트에게 전달된다. 라우터는 선택적으로 이웃 서브넷에 데이터그램을 보낼 수도 있다.
4.3.3.4. 주소 블록 획득(Obtaining a Block of Addresses)
기관은 IP 주소 블록을 얻기 위해, 이미 할당받은 주소의 큰 블록에서 주소를 제공하는 ISP를 접촉해야 한다. 아래와 같이 ISP는 주소 블록을 8개로 나누어, 8개 조직을 지원할 수도 있다.
ISP's block: 200.23.16.0/20 (11001000 00010111 0001)0000 00000000
Organization 0 200.23.16.0/23 (11001000 00010111 0001000)0 00000000
Organization 1 200.23.18.0/23 (11001000 00010111 0001001)0 00000000
Organization 2 200.23.20.0/23 (11001000 00010111 0001010)0 00000000
...
Organization 7 200.23.30.0/23 (11001000 00010111 0001111)0 00000000
ISP는 ICANN(Internet Corporation for Assigned Names and Numbers)로부터 주소 블록을 얻는다. ICANN의 역활은 IP 주소 할당과 DNS 루트 서버관리이다.
4.3.3.5. 호스트 주소 획득: 동적 호스트 구성 프로토콜(Obtaining a Host Address: The Dynamic Host Configuration Protocol, DHCP)
한 기관의 시스템 관리자는 호스트/라우터 인터페이스에 IP 주소를 할당한다. 이는 수동으로 할수도 있지만, 일반적으로 DHCP를 많이 사용한다.
DHCP 설정을 통해, 호스트가 네트워크게 접속하고자 할 때마다 동일한 IP 주소를 할당하거나, 다른 임시 IP 주소를 할당할 수 있다. 또한 DHCP는 서브넷 마스크, 첫 번째 홉 라우터(디폴트 게이트웨이라 부름) 주소, 로컬 DNS 서버 주소 같은 정보를 얻게 해준다. 네트워크에서 자동으로 호스트와 연결해 주기 때문에 플러그 앤 플레이 프로토콜(plug-and-play protocol)또는 제로 구성 프로토콜(zero-configuration protocol)이라고도 한다.
DHCP는 클라이언트/서버 프로토콜이다. 만약 서버가 현재 서브넷에 없다면, 해당 네트워크에 대한 DHCP 서버 주소를 알려줄 DHCP 연결 에이전트(일반적으로 라우터)가 필요하다.
새로운 호스트가 도착할 경우, 수행될 DHCP 프로토콜 4단계의 과정은 다음과 같다.
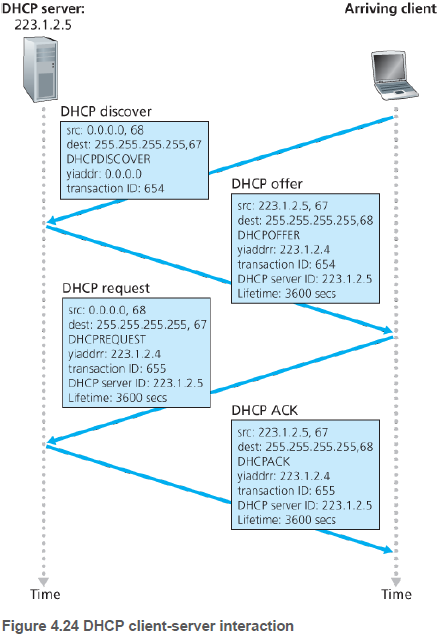
(1) DHCP 서버 발견(DHCP server discovery): 새롭게 도착한 호스트는 DHCP 발견 메세지(DHCP discover message)를 사용한다. 이는 UDP 패킷이며, 목적지 주소는 브로드캐스트 IP 주소 255.255.255.255, 출발지 주소는 0.0.0.0이다.
(2) DHCPP 서버 제공(DHCP server offer(s)): 메세지를 받은 DHCPP 서버는 DHCP 제공 메세지(DHCP offer message)를 클라이언트로 응답한다. 이때에도 브로드캐스트 주소를 사용한다. 이 메세지에는 클라이언트에게 제공될 IP 주소, 네트워크 마스트, IP 주소 임대 기간(IP 주소가 유효한 시간) 등이 있다.
(3) DHCP 요청(DHCP request): 서브넷에는 여러 DHCP 서버가 존재할 수 있기에, 클라이언트는 여러 DHCP 제공 메세지를 통해 최적 위치의 서버를 선택한다. 이후 클라이언트는 설정 파라미터들(configuration parameters)을 서버에게 응답한다.
(4) DHCP ACK: 서버는 요청된 파라미터들을 확인하는 DHCP ACK 메세지로 응답한다.
4.3.4. 네트워크 주소 변환(Network Address Translation, NAT)
네트워크가 커지면 큰 주소 블록을 할당해야 한다. 하지만 인접한 부분이 이미 할당되었다면 문제가 생긴다. 이를 해결하기 위해 NAT을 사용하여 주소를 할당한다.
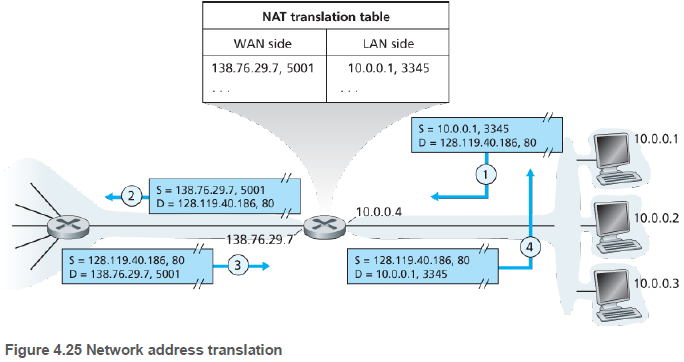
그림은 NAT 가능 라우터의 운영을 보여준다. 라우터의 오른쪽은 홈 네트워크로, 모두 같은 네트워크 주소 10.0.0.0/24를 갖는다. 주소 공간 10.0.0.0/8은 사설망(private network) 또는 홈 네트워크와 같은 사설 개인 주소를 갖는 권역(realm with private addresses)을 위해 [RFC 1918]에 예약된 IP 주소 공간 중 하나이다.
사설 주소를 갖는 권역이란, 네트워크 주소들이 그 네트워크의 내부에 있는 장비에게만 의미가 있는 네트워크를 의미한다. 즉, 주어진 홈 네트워크 내부의 장비는 10.0.0.0/24 주소체계를 이용하여 서로 패킷을 송신할 수 있다.
그러나 홈 네트워크를 벗어나 글로벌 인터넷으로 가는 패킷 전달은 이 주소들을 사용할 수 없다. 왜냐하면, 이 주소들의 블록을 똑같이 사용하는 수십만 개의 네트워크가 있기 때문이다.
NAT 라우터는 외부세계로는 하나의 IP 주소를 갖는 하나의 장비로 동작한다. 홈에서 인터넷으로 가는 트래픽은 출발지 IP 주소 136.76.29.7 을 가지고, 반대로 들어오는 트래픽은 목적지 주소 136.76.29.7을 가져야 한다.
이 경우 홈 네트워크의 주소는 NAT 가능 라우터에서 얻는다. 라우터는 ISP의 DHCP 서버로부터 주소를 얻고, 라우터가 제어하는 홈 네트워크의 주소 공간에서 DHCP 서버를 실행하여 컴퓨터에게 주소를 제공한다.
WAN으로부터 NAT 라우터로 데이터그램이 도착하면, 라우터는 NAT 변환 테이블(NAT translation table)을 사용해 데이터그램을 내부 호스트에게 전달한다. 테이블에는 IP 주소와 포트 번호가 포함되어 있다. 즉, 포트번호가 호스트 주소 지정에 사용된다.
호스트가 웹서버에 접속하려고 할 때, 호스트가 NAT 라우터에 데이터그램을 전달하면, 라우터가 출발지 주소(+ 포트 번호)를 바꾼다. 그리고 응답으로 라우터에 오는 데이터그램의 포트 번호를 보고, 대응되는 호스트에게 전달한다.
4.3.5. IPv6
32비트 IP 주소 공간이 부족해짐에 따라 IPv6가 개발되었다.
4.3.5.1. IPv6 데이터그램 포맷(IPv6 Datagram Format)
IPv6의 중요한 변화는 다음과 같다. (1) 확장된 주소 기능: IP 주소 크기가 128비트로 확장되었다. 기존의 Unicast(1대 1 통신), Multicast(멀티캐스트 그룹내 아무나 받을 수 있음), Broadcast(서브넷 내 아무나) 주소 외에 Anycast 주소가 도입되었다. Anycast 에서는 그룹 내의 가장 가까운 수신자가 받는다. 예를 들어 클라이언트의 DNS 질의를 가장 근접한 DNS 서버가 처리하되, 이 서버가 고장나면 그 다음 가까운 서버가 받는다.
(2) 간소화된 40바이트 헤더: IPv4의 많은 필드가 생략되거나 옵션으로 남겨졌다. 40바이트 고정 길이 헤더는 라우터가 데이터그램을 더 빨리 처리하게 해준다.
(3) 흐름 라벨링(Flow labeling): IPv6는 정의하기 어려운 흐름(flow)을 가지고 있다. [RFC 2460]은 “비 디폴트(non-default) 품질 서비스나 실시간 서비스와 같은 특별한 처리를 요청하는 송신자에 대해 특정 흐름에 속하는 패킷 라벨링(labeling)”을 가능하게 한다고 한다. 예를 들어, 오디오/비디오 전송은 흐름으로 처리될 수 있다.
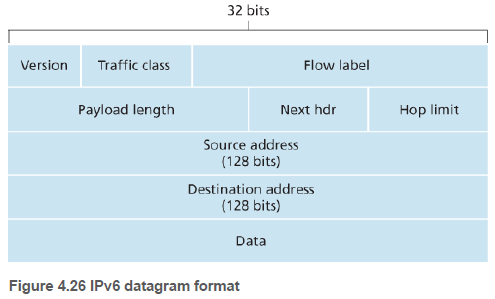
IPv6 데이터그램의 구조는 다음과 같다. (1) 버전: 이 필드에서 IPv6 값은 6이며, 4로 설정한다고 IPv4가 되지는 않는다.
(2) 트래픽 클래스: IPv4의 TOS필드와 비슷하며, 데이터그램에 우선 순위를 부여하는데 사용된다.
(3) 흐름 라벨: 데이터그램의 흐름을 인식하는데 사용된다.
(4) 페이로드 길이: 데이터그램에서 40바이트 헤더 뒤에 나오는 데이터의 바이트 길이이다.
(5) 다음 헤더(Next header): IPv4의 프로토콜 필드와 같다. 데이터그램의 데이터가 전달될 프로토콜(예: TCP, UDP …)을 구분한다.
(6) 홉 제한(Hop limit): IPv4의 TTL과 같다. 라우터가 데이터그램을 전달할 때마다 1씩 감소하고, 0이 되면 버려진다.
(7) 출발지/목적지 주소: 128비트 주소이다.
(8) 데이터: IPv6 데이터그램의 페이로드 부분이다.
아래와 같은 필드는 더 이상 존재하지 않는다. (1) 단편화/재결합: IPv6에서는 단편화와 재결합을 출발지/목적지 호스트만이 수행한다. 데이터그램이 너무 커서 출력 링크로 전달할 수 없다면, 라우터는 데이터그램을 폐기하고 송신자에게 알린다.
(2) 헤더 체크섬: 트랜스포트 계층 프로토콜(예: TCP, UDP)과 데이터 링크 프로토콜(예: 이더넷)이 체크섬을 수행하므로 네트워크 계층 체크섬이 생략되었다.
(3) 옵션: 옵션 필드가 제거되어 고정 길이 IP 헤더를 갖게 되었다. 그러나 TCP/UDP 헤더가 IP 패킷에서 다음 헤더(next header)가 될 수 있는 것 처럼, 옵션 필드도 IPv6 헤더에서 다음 헤더 중 하나가 될 수 있다. ??
4.3.5.2. IPv4에서 IPv6로의 전환(Transitioning from IPv4 to IPv6)
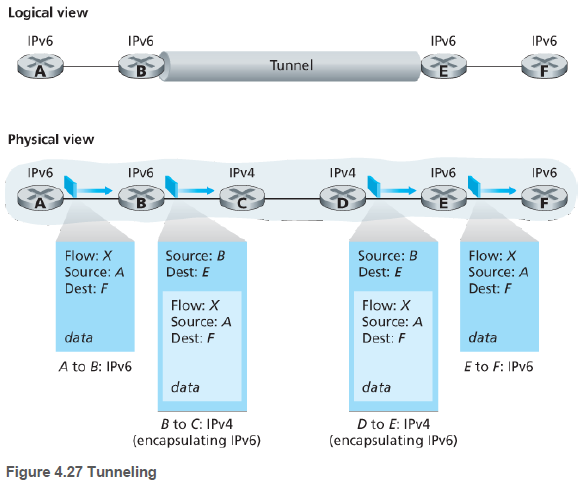
널리 사용되는 전환 방법은 터널링(tunneling)[RFC 4312]을 포함한다. IPv6를 사용하는 송신 라우터와 수신 라우터 경로에 있는 라우터들이 IPv4를 사용한다고 하자.
그럼 송신 라우터는 IPv4 데이터그램을 생성하고, 데이터 필드에 IPv6 데이터그램을 넣는다. 경로에 있는 라우터들은 그대로 IPv4 를 사용하고, 수신 라우터가 IPv6가 들어있는 것을 파악하고 이를 꺼낸다.
4.4. 일반적인 포워딩 및 소프트웨어 기반 네트워크(Generalized Forwarding and SDN)
목적지 IP 주소를 검색(“매칭”) 후 패킷을 스위칭 구조로 지정된 출력 포트로 전달(“액션”)하는 두 단계의 목적지 기반 포워딩을 4.2.1절에서 설명했다. 프로토콜 스택의 다른 계층에서 다른 프로토콜과 관련된 여러 헤더 필드에 대해 “매칭”을 수행할 수 있는 일반적인 “검색 추가 작업(match-plus-action)” 방법을 생각해 보자.
검색 추가 작업 테이블은 목적지 기반 포워딩 테이블의 개념을 일반화한다. 포워딩 결정이 네트워크 계층/링크 계층의 송신/수신 주소에 의해 결정될 수도 있으므로, 이 절에서 포워딩 장치는, 3계층의 라우터 또는 2계층의 스위치 보다는, 패킷 스위치로 보다 정확하게 설명된다.
패킷 스위치의 검색 추가 작업 테이블은 원격 컨트롤러를 통해 계산, 설치 및 업데이트 된다. OpenFlow는 명확하고 간결한 방식으로 SDN 개념 및 기능을 도입하였기에, 이 절에서 이를 살펴본다.
OpenFlow의 플로우 테이블(flow table)로 알려진 검색 추가 작업의 포워딩 테이블의 각 항목은 다음을 포함한다.
- 들어오는 패킷은 헤더 필드 값들의 집합과 매칭된다.
- 패킷들이 플로우 테이블의 항목에 매치될 때 업데이트되는 카운터 집합(set of counters)이 있다.
- 패킷이 플로우 테이블의 항목과 일치될 때 수행되는 동작들의 집합이 있다.
4.4.1. 매치(Macth)
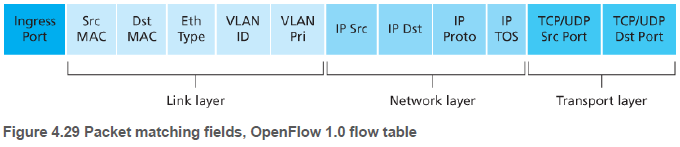
(1.5.2절) 패킷 스위치에 도달하는 링크 계층 프레임은 페이로드로 네트워크 계층 데이터 그램, 전송 계층 세그먼트를 포함한다. 따라서, 검색 추가 작업 규칙에서 매치될 수 있는 필드는 MAC 주소, 이더넷 타입, IP 주소, IP 프로토콜, TCP 포트 등 여러 가지가 있다.
4.4.2. 액션(Action)
각 플로우 테이블 항목은, 항목에 일치하는 패킷처리를 결정하는 액션 목록을 가지고 있다. 가장 중요한 액션들은 다음과 같다.
- 포워딩(Forwarding): 패킷을 출력 포트로 전달하거나, 브로드캐스트, 멀티캐스트, 원격 컨트롤러로 전송 등이 가능하다.
- 드롭핑(Dropping): 아무 동작이 없는 플로우 테이블 항목은, 일치된 패킷을 삭제한다.
- 수정필드(Modify-field): 패킷이 출력 포트로 전달되기 전에, 패킷 헤더 필드의 값을 수정할 수 있다.
4.4.3. 매칭-플러스-액션 작업의 OpenFlow 예(OpenFlow Examples of Match-plus-action in Action)
4.4.3.1. 첫 번째 예: 간단한 포워딩(A First Example: Simple Forwarding)
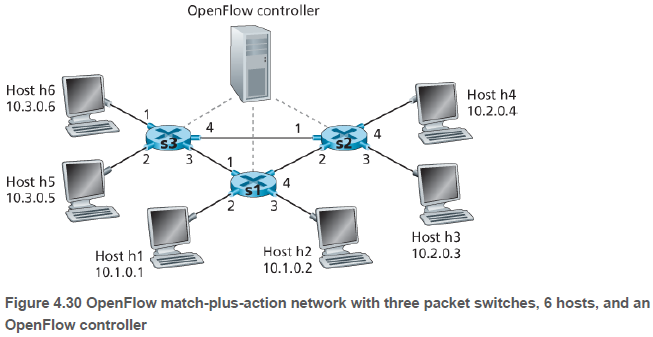
s1 라우터의 1번 포트로 IP 주소의 앞 16비트가 10.3 인 패킷이 오면, 4번 포트로 포워딩한다.
s1 Flow Table (Example 1)
Match Action
Ingress Port = 1; IP Src = 10.3.*.*; IP Dst = 10.2.*.* Forward(4)
... ...
4.4.3.2. 두 번째 예: 부하 균등화(A Second Example: Load Balancing)
s2 라우터에 h3, h4가 올 수 있고, 각각 다른 쪽으로 포워딩한다.
s2 Flow Table (Example 2)
Match Action
Ingress port = 3; IP Dst = 10.1.*.*; Forward(2)
Ingress port = 4; IP Dst = 10.1.*.*; Forward(1)
... ...
4.4.3.3. 세 번째 예: 방화벽(A Third Example: Firewalling)
s2 라우터가 s3에 연결된 호스트에서 보낸 트래픽만 수신하려고 한다. 출발지 IP 주소 10.2..를 항목에 넣지 않는다.
s2 Flow Table (Example 2)
Match Action
IP Src = 10.3.*.*; IP Dst = 10.2.0.3 Forward(3)
IP Src = 10.3.*.*; IP Dst = 10.2.0.4 Forward(4)
... ...
댓글남기기