컴퓨터 네트워킹 요약 - 2. 애플리케이션 계층
2.1. 네트워크 애플리케이션의 원리(Principles of Network Applications)
네트워크 애플리케이션 개발의 중심은 다른 종단 시스템에서 동작하는 프로그램과 네트워크를 통해 서로 통신하는 프로그램을 개발하는 것이다.
새로운 애플리케이션을 개발할 때는 여러 종단 시스템에서 실행 되는 소프트웨어를 작성할 필요가 있다. 링크 계층 스위치와 같이 네트워크 코어 장비에서 실행되는 소프트웨어를 작성할 필요는 없다.
2.1.1. 네트워크 애플리케이션 구조(Network Application Architectures)
애플리케이션 구조는 네트워크 구조(1장의 다섯 계층 구조)와 다르다. 애플리케이션 개발자 관점에서 네트워크 구조는 고정된 채로 애플리케이션에 특정 서비스 집합을 제공한다.
애플리케이션 구조에는 두 가지 우수한 구조(클라이언트-서버 구조 혹은 P2P 구조)가 있다.
클라이언트-서버 구조(client-server architecture)에서 항상 켜져 있는 호스트를 서버라고 부르며, 이는 클라이언트라 불리는 다른 호스트들의 요청을 처리한다.
클라이언트도 가끔 항상 켜져 있을 수 있다. 예를 들어, 클라이언트 호스트에서 실행되는 브라우저는 항상 켜진 웹 서버로 서비스를 요청하는 웹 애플리케이션이다.
하나의 서버 호스트가 많은 클라이언트의 모든 요청에 응답하는 것은 불가능하다. 따라서 많은 수의 호스트를 갖춘 데이터 센터(data center)가 가상 서버를 생성하는 데 흔히 사용된다.
P2P구조에서는 데이터 센터에 있는 서버에 최소로 의존한다(혹은 의존하지 않는다). 대신 애플리케이션은 피어(peer)라는 간헐적으로 연결된 호스트 쌍이 서로 직접 통신하도록 한다. 피어는 서비스 제공자(service provider)가 소유하지 않고, 사용자들이 제어하는 데스크톱 등이다.
특정 서버를 통하지 않고 피어가 통신하므로, 이 구조를 피어-투-피어(peer-to-peer, P2P)라고 한다. 이들 애플리케이션에는 스카이프 등이 있다.
혹은 두 구조를 결합한 하이브리드 구조를 가진 애플리케이션들(instant messaging applications 등)도 있다.
2.1.2. 프로세스 간 통신(Processes Communicating)
프로세스 간의 통신을 위한 규칙은 종단 시스템의 운영체제에 의해 좌우된다. 2개의 다른 종단 시스템에서 프로세스는 컴퓨터 네트워크를 통한 메세지 교환으로 서로 통신한다. 송신 프로세스는 메세지를 만들어서 네트워크로 보낸다.
2.1.2.1. 클라이언트와 서버 프로세스(Client and Server Processes)
통신하는 프로세스 각 쌍에 대해 일반적으로 클라이언트 프로세스와 서버 프로세스 중 하나로 이름 짓는다. 웹에서, 브라우저는 클라이언트 프로세스이고, 웹 서버는 서버 프로세스이다. P2P 파일 공유에서는, 파일을 내려받는 피어를 클라이언트, 파일을 올리는 피어를 서버라고 한다.
클라이언트와 서버 프로세스를 다음과 같이 정의할 수 있다.
2.1.2.2. 프로세스와 컴퓨터 네트워크 사이의 인터페이스(The Interface Between the Process and the Computer Network)
프로세스는 소켓(socket)을 통해 네트워크로 메세지를 보내고 받는다. 소켓은 호스트의 애플리케이션 계층과 트랜스포트 계층 간의 인터페이스다. 또한 애플리케이션과 네트워크 사이의 API(Application Programming Interface)라고도 한다.
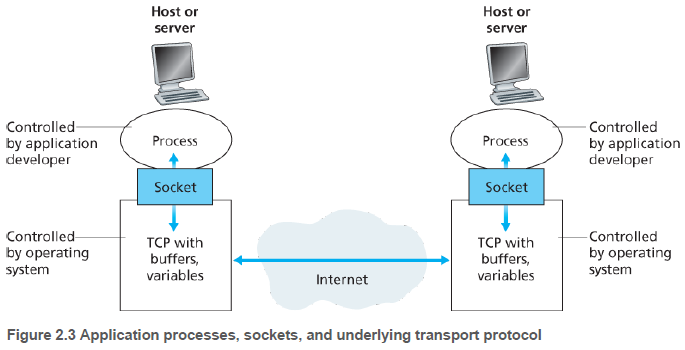
애플리케이션 개발자는 소켓의 애플리케이션 계층에 대한 모든 통제권을 갖지만, 소켓의 트랜스포트 계층에 대한 통제권은 거의 갖지 못한다. 트랜스포트 계층에 대한 통제는, 트랜스포트 프로토콜의 선택, 버퍼와 세그먼트 크기와 같은 매개변수의 설정 뿐이다.
2.1.2.3. 프로세스 주소 배정(Addressing Processes)
수신 프로세스를 식별하기 위해, 호스트의 주소와 그 목적지 호스트 내의 수신 프로세스를 명시하는 식별자가 필요하다. 인터넷에서 호스트는 유일하게 식별되는 IP 주소로 식별된다.
수신 프로세스(수신 소켓)은 목적지 포트 번호(port number)가 사용된다. 일부 응용은 특정 포트 번호가 할당된다. 예를 들어, 웹 서버는 포트 번호 80번으로 식별된다.
2.1.3. 애플리케이션이 이용 가능한 트랜스포트 서비스(Transport Services Available to Applications)
2.1.3.1. 신뢰적 데이터 전송(Reliable Data Transfer)
패킷은 네트워크 내에서 손실될 수 있다. 예를 들어, 라우터의 버퍼에서 오버플로우(overflow)되거나, 패킷의 비트가 잘못되면 노드에서 버려질 수 있다.
만약 프로토콜이 보장된 데이터 전송 서비스를 제공한다면 이를 신뢰적 데이터 전송을 제공한다고 한다. 트랜스포트 계층 프로토콜이 애플리케이션에 제공할 수 있는 한 가지 서비스는 프로세스 간 신뢰적 데이터 전송이다.
트랜스포트 계층 프로토콜이 신뢰적 데이터 전송을 제공하지 않을 때, 데이터가 수신 프로세스에 도착하지 않을 수 있다. 이것은 손실 허용 애플리케이션(loss-tolerant application), 즉 어느 정도의 데이터 손실이 있어도 괜찮은 실시간 오디오/비디오 등에서 쓰일 수 있다.
2.1.3.2. 처리량(Throughput)
트랜스포트 프로토콜이 제공할 수 있는 다른 서비스는 명시된 속도에서 보장된 가용 처리율을 제공한다는 것이다. 애플리케이션은 r bist/se의 보장된 처리율을 요구할 수 있고, 트랜스포트 프로토콜은 가용한 처리율이 적어도 r bps임을 보장한다.
처리율 요구 사항을 갖는 애플리케이션은 대역폭 민감 애플리케이션(bandwidth-sensitive application)이라고 한다. 예를 들어, 인터넷 전화 애플리케이션에게 보장된 처리율을 제공할 수 없다면, 이 애플리케이션은 낮은 속도로 서비스를 처리하거나 포기해야 한다.
탄력적 요구 애플리케이션(elastic application)은 가용한 처리율을 많으면 많은 대로, 적으면 적은 대로 이용할 수 있다. 이메일, 파일 전송 등이 융통성 있는 애플리케이션이다.
2.1.3.3. 시간(Timing)
트랜스포트 계층 프로토콜은 시간 보장(timing guarantee)을 제공할 수 있다. 수신 소켓에 정해진 시간내에 도착하도록 하는 서비스는 인터넷 전화, 원격회의 등과 같은 실시간 애플리케이션에 매력적이다.
2.1.3.4. 보안(Security)
트랜스포트 계층 프로토콜은 애플리케이션에 보안 서비스를 제공할 수 있다. 전송되는 모든 데이터를 암호화할 수 있다.
2.1.4. 인터넷 전송 프로토콜이 제공하는 서비스(Transport Services Provided by the Internet)
2.1.4.1. TCP 서비스(TCP Services)
TCP 서비스 모델은 연결지향형 서비스와 신뢰적인 데이터 전송 서비스를 포함한다.
연결지향형 서비스, 애플리케이션 계층 메세지를 전송하기 전에 TCP는 클라이언트와 서버가 서로 전송 제어 정보를 교환하도록 한다. 이 핸드셰이킹(handshaking) 과정은 양쪽에 패킷이 곧 도달하니 준비하라고 알려주 는 역활을 한다. 핸드셰이킹 단계를 지나면, TCP 연결이 두 프로세스의 소켓 사이에 존재한다. 이 연결은 전이중(full-duplex) 연결이며, 메세지 전송을 마치면 연결을 끊어야 한다.
신뢰적인 데이터 전송 서비스, TCP는 애플리케이션의 한쪽이 바이트 스트림을 소켓으로 전달하면, 이를 손실하거나 중복되지 않게 수신 소켓으로 전달한다.
2.1.4.2. UDP 서비스(UDP Services)
UDP는 최소의 서비스 모델을 가진 간단한 전송 프로토콜이다. UDP는 핸드셰이킹을 하지 않으며, 비신뢰적인 전송 서비스(메세지가 수신 소켓에 도착하는 것을 보장하지 않음)를 제공한다. 게다가 수신 소켓에 도착하는 메세지들의 순서가 뒤바뀔 수도 있다.
UDP는 혼잡제어 방식(3장 내용)을 포함하지 않기에, 송신 측이 데이터를 원하는 속도로 하위 계층(네트워크 계층)으로 보낼 수 있다.
2.1.4.3. 인터넷 트랜스포트 프로토콜이 제공하지 않는 서비스(Services Not Provided by Internet Transport Protocols)
오늘날의 인터넷은 때로 시간-민감(time-sensitive) 애플리케이션들에게 만족스런 서비스를 제공할 수 있으나, 시간 혹은 대역폭 보장을 제공할 수는 없다.
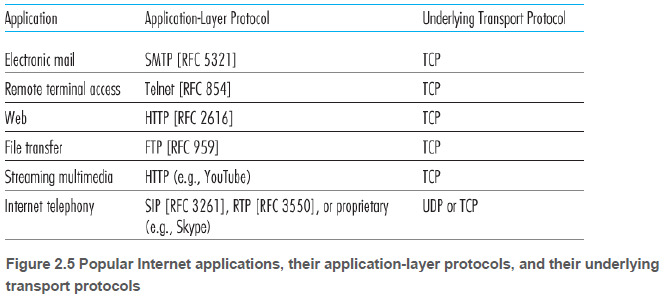
2.1.5. 애플리케이션 계층 프로토콜(Application-Layer Protocols)
애플리케이션 계층 프로토콜은 다른 종단 시스템에서 실행되는 애플리케이션의 프로세스가 서로 메세지를 보내는 방법을 정의한다. 여러 애플리케이션 계층 프로토콜은 RFC에 명시되어 있다.
- 메세지 타입(요청, 응답)
- 메세지 타입의 문법(메세지 내부 필드와 필드간 구별 방법)
- 필드에 있는 정보의 의미
- 언제, 어떻게 메세지를 전송하고, 이에 응답하는지에 대한 규칙
애플리케이션 계층 프로토콜은 네트워크 애플리케이션의 한 요소일 뿐이다. 예를 들어, 웹 애플리케이션은 문서 포맷 표준(HTML), 웹 브라우저(익스플로러 등), 웹 서버(아파티 등) 그리고 웹 애플리케이션 계층 프로토콜(HTTP)을 포함하는 여러 요소들로 구성된다. 따라서 HTTP는 단지 웹 애플리케이션의 한 요소다.
2.1.6. 이 책에서 다루는 네트워크 애플리케이션(Network Applications Covered in This Book)
웹, 파일 전송, 전자메일, 디렉터리 서비스, 비디오 스트리밍, P2P 애플리케이션을 다룬다.
2.2. 웹과 HTTP
웹은 온-디맨드(on-demand) 방식, 즉 사용자들이 원할 때, 원하는 것을 수신한다.
2.2.1. HTTP 개요(Overview of HTTP)
웹의 애플리케이션 계층 프로토콜인 HTTP(HyperText Transfer Protocol)은 웹의 중심이다. 클라이언트, 서버 프로그램은 HTTP 메세지를 교환하여 통신한다.
웹 페이지(web page)는 객체(object)들로 구성된다. 객체는 단일 URL로 지정할 수 있는 하나의 파일(HTML 파일, 이미지 파일 등)이다.
대부분의 웹 페이지는 기본 HTML 파일과 여러 객체로 구성된다. 기본 HTML 파일은 페이지 내부의 다른 객체를 그 객체의 URL로 참조한다. 각 URL은 객체를 갖고 있는 서버의 호스트 이름과 객체의 경로 이름을 갖고 있다. http://www.test.com/tttt/picture.gif* 에서 www.test.com 은 호스트 이름이고, /tttt/picture.gif 는 경로 이름이다.
웹 브라우저(클라이언트라는 용어와 혼용 가능)는 요구한 웹 페이지를 보여주고, 여러 구성 특성을 제공한다. 서버 측을 구현하는 웹 서버는 URL로 지정할 수 있는 웹 객체를 갖고 있다.
HTTP는 웹 클라이언트가 웹 서버에게 웹 페이지를 어떻게 요청하는지와 서버가 클라이언트로 어떻게 웹 페이지를 전송하는지를 정의한다.
HTTP는 TCP를 전송 프로토콜로 사용한다. 클라이언트는 먼저 서버에 TCP 연결을 시작한다. 연결된 이후, 클라이언트는 HTTP 요청 메세지를 소켓 인터페이스로 보내고, 이로부터 HTTP 응답 메세지를 받는다. 마찬가지로, 서버는 소켓 인터페이스로부터 요청 메세지를 받고, 이에 응답 메세지를 보낸다.
TCP가 HTTP에게 신뢰적인 데이터 전송 서비스를 제공하기에, HTTP는 데이터의 손실 또는 TCP 및 하위 계층들이 어떻게 손실 데이터를 복구하는지 걱정할 필요가 없다. 이러한 점이 계층구조의 장점 중 하나이다.
서버는 클라이언트에 관한 어떠한 상태 정보도 저장하지 않는다. 클라이언트가 같은 객체에 대해 계속 요청해도, 이미 보낸 것을 기억하지 않고 그 객체를 또 보낸다. 그렇기에 HTTP를 비상태 프로토콜(stateless protocol)이라고 한다.
2.2.2. 비지속 연결과 지속 연결(Non-Persistent and Persistent Connections)
클라이언트-서버 상호작용이 TCP에서 발생할 때, 두 가지 연결 방식이 있다. 비지속 연결은 각 요구/응답 쌍에 분리된 TCP 연결을 사용하는 것이다. 지속 연결은 모든 요구와 해당하는 응답에 같은 TCP 연결을 사용하는 것이다.
2.2.2.1. 비지속 연결 HTTP
웹 페이지가 기본 HTML 파일과 10개의 JPEG 이미지로 구성된다고 하자. 연결 수행 과정은 다음과 같다.
- 클라이언트가 서버에 TCP 연결을 시도하고, TCP 연결과 관련된 양쪽에 소켓이 생성된다.
- 소켓을 통해 서버로 HTTP 요청 메세지를 보낸다. 여기에는 기본 HTML 파일의 URL이 포함된다.
- 서버는 기본 HTML 파일을 저장장치에서 가져와 캡슐화를 진행하고 응답 메세지를 클라이언트에게 보낸다.
- 서버는 TCP에게 연결을 끊으라고 한다(클라이언트가 응답 메세지를 받으면).
- 클라이언트가 응답 메세지를 받으면 TCP 연결이 중단된다. 응답 메세지로부터 HTML 파일을 추출하고 10개의 JPEG 객체에 대한 참조를 찾는다.
- 참조되는 각 JPEG 객체에 대하여 처음 네 단계를 반복한다.
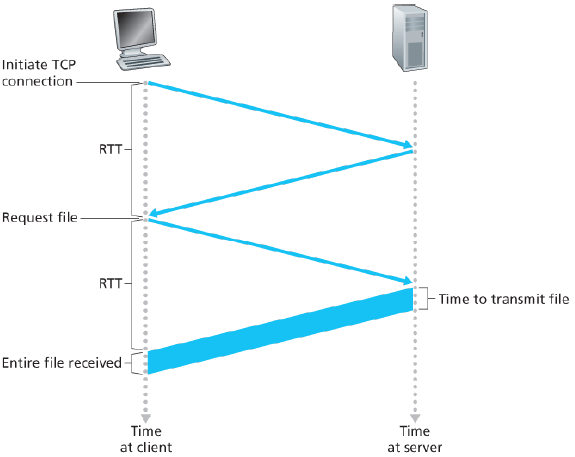
클라이언트가 하이퍼링크를 클릭하면, three-way handshake 가 이루어진다. TCP 연결 요청을 하고, 이에 대한 응답이 받고, 이번에는 파일을 요청하는, 세 번의 과정이 필요하다.
패킷이 클라이언트로부터 서버까지 가고, 다시 클라이언트로 되돌아오는 데 걸리는 시간을 RTT(round-trip time)라고 한다. HTML 파일을 요청하고 수신하는 데에는, TCP 연결 설정(요청/응답)에 1 RTT, 파일 요청-전송에 1 RTT(+ 파일크기에 따른 전송 시간)가 필요하다.
2.2.2.2. 지속 연결 HTTP
비지속 연결은 각 요청 객체에 대한 새로운 연결이 설정되고 유지되어야 하는 단점이 있다. 이는 많은 클라이언트의 요청을 동시에 서비스하는 웹 서버에게 부담을 줄 수 있다.
지속 연결에서는 전체 웹 페이지(앞의 예에서 기본 HTML 파일과 10개 이미지)를 같은 연결틀 통해 보낼 수 있다. HTTP의 기본 설정은 지속 연결이며, 일반적으로 서버는 일정 기간 사용되지 않으면 연결을 닫는다.
2.2.3. HTTP 메세지 포맷
2.2.3.1. HTTP 요청 메세지
전형적인 HTTP 요청 메세지는 다음과 같다. 각 줄은 CR과 LF(carriage return & line feed)로 구별된다.
GET /somedir/page.html HTTP/1.1 // 요청 라인(request line), 아래 네 줄은 헤더 라인(header line)
Host: www.someschool.edu // 호스트
Connection: close // 지속 연결 사용 안함
User-agent: Mozilla/5.0 // 브라우저(파이어폭스)
Accept-language: fr // 언어
// crlf
// 개체 몸체(entity body)
GET 에서는 비어있음(empty)
//
GET 이외에, 서버가 응답 시 요청 객체를 보내지 않는 HEAD(주로 디버깅), 웹 서버 업로드할 객체를 필요로 하는 PUT, 웹 서버에 있는 객체를 삭제하는 DELETE 방식이 있다.
2.2.3.2. HTTP 응답 메세지
전형적인 HTTP 응답 메세지는 다음과 같다.
HTTP/1.1 200 OK // 상태 라인(status line)
Connection: close // 메세지를 보낸후 연결을 닫느냐 마냐
Date: Tue, 18 Aug 2015 15:44:04 GMT // 응답이 생성된 날짜와 시간
Server: Apache/2.2.3 (CentOS) // 아파치 웹 서버
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT // 객체 수정 날짜
Content-Length: 6821 // 객체 바이트 수
Content-Type: text/html // 객체 몸체 내부가 HTML 텍스트
// crlf
// 개체 몸체(entity body)
(data data data ...)
//
일반적인 상태 코드는 다음과 같다.
- 200 OK: 요청 성공, 응답 보내짐
- 301 Moved Permanently: 객체가 이동되었음, 새로운 URL이 적힌 Location: 헤더를 따라감
- 400 Bad Request: 요청을 이해할 수 없음
- 404 Not Found: 요청 문서가 서버에 존재하지 않음
- 505 HTTP Version Not Supported: HTTP 프토로콜 버전을 서버가 지원하지 않음
2.2.4. 사용자와 서버 간의 상호작용: 쿠키(User-Server Interaction: Cookies)
HTTP 서버는 상태를 유지하지 않음으로써 서버 설계를 간편하게 하고, 동시에 수천 개의 TCP 연결을 다룰 수 있다. 그러나 사용자 접속 제한, 맞춤형 콘텐츠 제공 등의 이유로 사용자를 확인 하는것이 필요할 때가 있다.
이를 위해 쿠키를 사용한다. 쿠키는 사이트가 사용자를 추적하도록 해준다.
쿠키에는 네 가지 요소가 필요하다.
- HTTP 응답 메세지 쿠키 헤더 라인
- HTTP 요청 메세지 쿠키 헤더 라인
- 사용자의 브라우저에 사용자 종단 시스템과 관리를 지속시키는 쿠키 파일
- 웹 사이트의 백엔드(back-end) 데이터 베이스
쿠키는 다음과 같이 동작한다. 브라우저가 Set-cookie 헤더가 있는 응답 메세지를 받으면, 특정한 쿠키 파일에 서버의 호스트 네임과 Set-cookie 헤더와 식별번호를 기록한다. 이후부터는 요청 메세지에 식별번호를 포함하는 쿠키 헤더 파일을 넣는다.
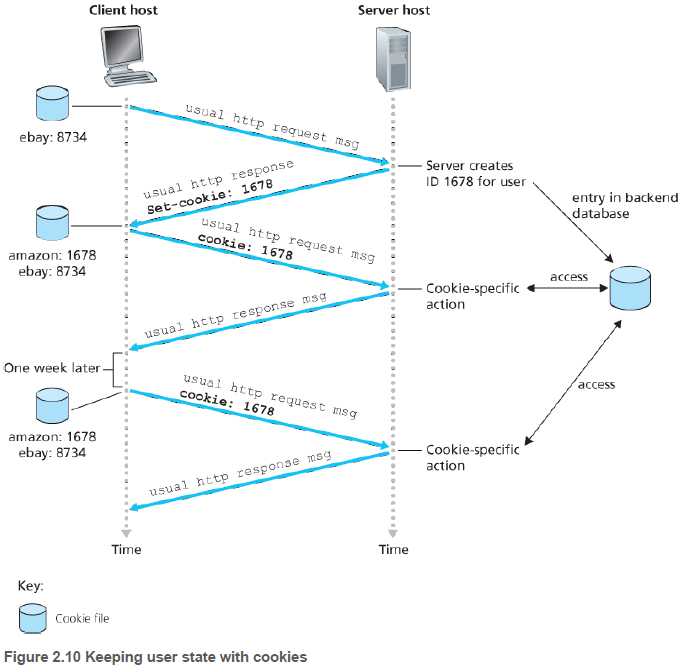
이런식으로 서버가 사용자의 활동을 추적할 수 있고, 사용자 식별, 제품 추천 등을 할 수 있다.
2.2.5. 웹 캐싱(Web Caching)
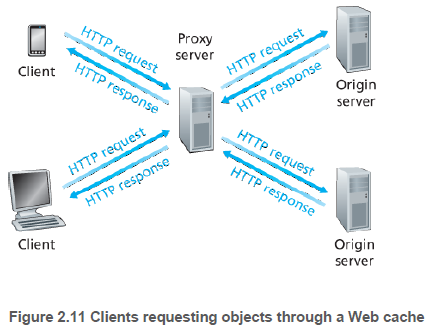
웹 캐시(Web cache; 프록시 서버(proxy server)라고도 함)는 웹 서버를 대신하여 HTTP 요구를 서비스하는 네트워크 개체(entity)이다. 웹 캐시는 최근 호출된 객체의 사본을 저장한다.
브라우저는 HTTP 요구를 웹 캐시에 먼저 보내도록 구성될 수 있다.
- 브라우저가 웹 캐시에 TCP 연결을 통해 객체에 대한 요청을 보낸다.
- 웹 캐시는 객체의 사본이 있으면 응답한다.
- 없다면 웹 캐시가 서버와 TCP 연결을 통해 객체를 요청하고 받는다.
- 웹 캐시는 받은 객체를 자신의 저장장치에 저장하고, 브라우저에게 객체를 보낸다.
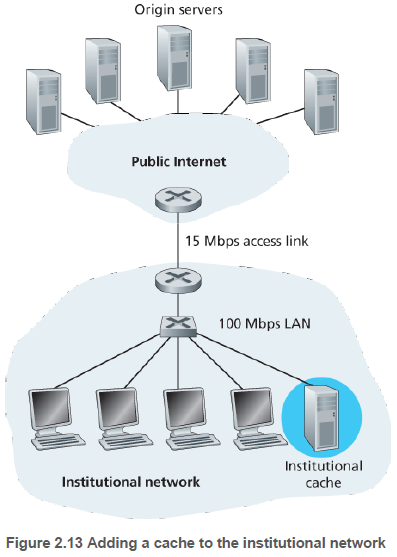
웹 캐싱은 다음과 같은 장점이 있다. 첫째, 요구에 대한 응답 시간을 줄일 수 있다. 둘째, 기관 네트워크에서 인터넷으로 접속하는 링크상의 웹 트래픽을 줄일 수 있다.
예를 들어, 기관 네트워크가 LAN이며, 기관 내의 호스트가 인터넷에 접근하려면 기관 라우터와 인터넷 라우터의 링크를 무조건 접근해야 한다고 하자. 이때, 기관 내 여러 호스트가 인터넷에 동시 접근하여, 이 링크에 트래픽 강도가 올라갈 수 있다. 기관 내에 웹 캐시를 둔다면 사본이 있는 경우 인터넷에 접근할 필요가 없어 트래픽 강도를 줄일 수 있다.
2.2.5.1. 조건부 GET(The Conditional GET)
웹 캐시 내부에 있는 객체의 사본이 최신의 것이 아닐 수 있다. 캐시된 이후에 웹 서버에서 객체가 갱신되었을 수도 있다.
조건부 GET은 이를 해결한다. 브라우저가 웹 캐시에 요청을 보내면, 웹 캐시는 서버에게 요청을 보낸다. 서버는 객체가 갱신되었으면 응답 메세지에 개체를 포함하고, 아니라면 응답 메세지만 보낸다.
웹 캐시와 조건부 GET을 통해 요청 객체를 포함하지 않음으로써 대역폭을 아낄 수 있다.
2.3. 인터넷 전자메일(Electronic Mail in the Internet)
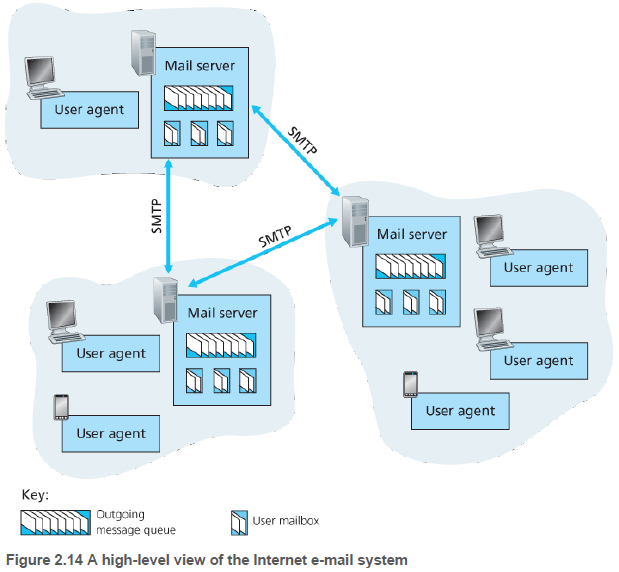
인터넷 전자메일 시스템에는 사용자 에이전트(agent), 메일 서버, SMTP(Simple Mail Transfer Protocol)라는 3개 주요 요소가 있다.
사용자 에이전트는 MS 아웃룩과 같이 메세지 읽기, 전달 등을 제공한다. 사용자가 메세지 작성을 끝내면, 에이전트는 사용자의 메일 서버로 메세지를 보낸다. 거기서 메세지는 메일 서버의 출력 메세지 큐(outgoing message queue)에 들어간다.
각 사용자는 메일 서버안에 메일박스(mailbox)를 갖고 있다. 일반 메세지는 송신자의 에이전트에서 전달이 시작되고, 송신자의 메일 서버를 거친 후에 수신자의 메일 서버로 전달된다. 그리고 수신자의 메일박스에 저장된다.
SMTP는 인터넷 전자메일을 위한 애플리케이션 계층 프로토콜이다. 송신자의 메일 서버로부터 수신자의 메일 서버로 메세지를 전송한다. TCP의 신뢰적인 데이터 전송 서비스를 이용한다.
2.3.1. SMTP
SMTP의 기본 동작은 다음과 같다.
- 사용자가 에이전트에게 메세지를 보내라고 명령한다.
- 에이전트가 메세지를 메일 서버에 보내고, 그곳에서 메세지는 메세지 큐에 놓인다.
- 송신자의 메일 서버에서 동작하는 SMTP가 수신자의 메일 서버에서 동작하는 SMTP 에게 TCP 연결을 한다.
- SMTP 핸드셰이킹 이후에 메세지가 송신되고, 수신자의 메일박스에 놓인다.
- SMTP는 두 메일 서버가 멀리 떨어져 있더라도 중간 서버를 사용하지 않는다.
- TCP 연결에서 수신자의 서버가 죽어 있다면, 재시도를 하다가 포기한다.
- SMTP 핸드셰이킹 과정 동안, SMTP는 송신자의 메일 주소와 수신자의 메일 주소를 제공한다.
- SMTP는 지속 연결을 사용한다.
2.3.2. HTTP와의 비교(Comparison with HTTP)
첫째, HTTP는 원칙적으로 풀(pull) 프로토콜이다. 사용자가 서버로부터 정보를 가져오기 위해 HTTP를 사용한다. 특히, TCP 연결은 파일을 수신할 컴퓨터가 먼저 초기화한다.
반면에 SMTP는 원칙적으로 푸시(push) 프로토콜이다. 송신 메일 서버가 파일을 수신 메일 서버로 보낸다. TCP 연결은 파일을 보내는 컴퓨터에서 먼저 초기화 한다.
둘째, SMTP는 메세지가 7비트 ASCII 포맷일 것을 요구한다. 따라서 7비트 ASCII가 아닌 문자, 이진 데이터(이미지 파일) 등을 포함한다면, 7비트 ASCII로 인코딩되어야 한다. HTTP는 이런 제한이 없다.
셋째, 텍스트, 이미지 등으로 구성된 문서를 다루는 방법이 다르다. HTTPS는 응답 메세지에 각 객체를 캡슐화 한다. SMTP는 모든 메세지의 객체를 한 메세지로 만든다.
2.3.3. 메일 메세지 포맷(Mail Message Formats)
여러 헤더 라인(키워드, 콜론, 값의 순서로 구성됨)으로 구성되고, From: 헤더 라인과 To: 헤더 라인은 필수이다.
From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Searching for the meaning of life.
...
헤더 라인 이후에 메세지 몸체(message body)가 나올 수 있다.
2.3.4. 메일 접속 프로토콜(Mail Access Protocols)
오늘날 메일 서버는 보통 사용자들과 공유하고 사용자들의 ISP들이 유지 관리한다. 따라서 2.3.1의 동작과는 다르다.
- 송신자가 송신자의 메일 서버에 SMTP를 통하여 메세지를 보낸다.
- 송신자의 메일 서버에서 수신자의 메일 서버로 SMTP를 통해 메세지가 보내진다.
- 수신자가 수신자의 메일 서버에서 메세지를 받는다.
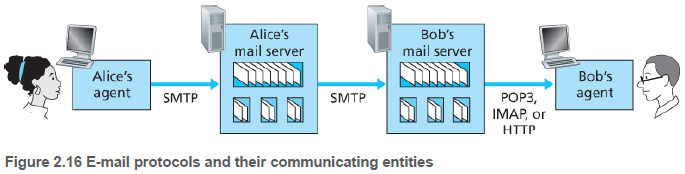
수신자가 메세지를 받을 때는 SMTP를 쓰지 못하고 POP3(Post Office Protocol 3), IMAP(Internet Mail Access Protocol) 등을 사용한다. SMTP가 푸시 프로토콜인 반면, 메세지를 얻는 것은 풀 동작이기 때문이다.
2.3.4.1. POP3
이 프로토콜은 아주 간단하므로 매우 한정된 기능을 가진다. 에이전트가 메일 서버와 TCP 연결을 한다. 이후 인증, 트랜잭션, 갱신 3단계 과정으로 진행한다.
인증은 사용자 이름과 비밀번호를 요구하는 것이다. 트랜잭션은 메세지를 가져오거나, 메세지 삭제 표시 체크/해제 등이 가능하다. 갱신은 삭제 표시된 메세지를 삭제된다.
2.3.4.2. IMAP
POP3는 로컬 컴퓨터 안의 폴더에 메세지를 다운받을 수 있다. 하지만 원격 폴더를 생성하거나 폴더에 메세지를 할당하지는 못한다.
IMAP 서버는 폴더에 각각의 메세지를 연결한다. 처음 메세지가 서버에 도착하면 수신자의 INBOX 폴더와 연결된다. 수신자는 메세지를 새 폴더를 생성하거나, 하나의 폴더에서 다른 폴더로 메세지를 옮길 수 있다.
2.3.4.3. 웹 기반 전자메일
최근에는 거의 모든 사람들이 웹 브라우저를 통해 전자메일을 보내거나 받는다. 이런 경우 사용자 에이전트는 웹 브라우저이고, 사용자는 HTTP를 통해 메일 서버에 있는 원격 메일박스와 통신하게 된다.
수신자가 자신의 메일박스에 있는 메세지를 보고자 할때도 POP3, IMAP이 아닌 HTTP 프로토콜을 사용하여 메세지를 브라우저로 전달한다.
그러나 메일 서버는 여전히 SMTP를 이용하여 메세지를 다른 메일 서버로 전달하거나 수신한다.
2.4. DNS-인터넷의 디렉터리 서비스(DNS—The Internet’s Directory Service)
호스트에 대한 하나의 식별자는 호스트 이름이다. www.google.com 같은 이름은 사용자가 기억하기 쉽다.
하지만 인터넷에서의 호스트 위치에 대한 정보를 제공하지 않는다. 때문에 호스트는 IP 주소로도 식별된다.
2.4.1. DNS가 제공하는 서비스(Services Provided by DNS)
라우터는 IP 주소가 필요하기에, 호스트 이름을 IP 주소로 변환해 주는 디렉터리 서비스가 필요하다. 이를 인터넷 DNS(domain name system)가 수행한다.
DNS는 (1) DNS 서버들의 계층구조로 구현된 분산 데이터베이스이고, (2) 호스트가 분산 데이터베이스로 질의하도록 허락하는 애플리케이션 계층 프로토콜이다.
DNS는 HTTP, SMTP 등 다른 애플리케이션 프로토콜들이 사용자가 제공한 호스트 이름을 IP 주소로 변환하기 위해 사용한다. HTTP의 경우는 다음과 같다.
- 브라우저가 URL로부터 호스트 이름을 추출한다.
- DNS 서버로 호스트 이름을 포함하는 질의를 보낸다.
- 호스트 이름에 대한 IP 주소를 가진 응답을 받는다.
- 브라우저가 IP 주소와 80번 포트를 이용하여 HTTP 서버 프로세스와의 TCP 연결을 초기화한다.
DNS는 다른 서비스도 제공한다.
호스트 엘리어싱(host aliasing): 호스트는 하나 이상의 별명을 가질 수 있다. 정식 호스트 이름(canonical hostname) relay1.west-coast.enterprise.com 은 enterprise.com 같은 별칭을 가질 수 있다. DNS는 제시한 별칭 호스트 이름에 대한 정식 호스트 이름을 얻기 위해 이용될 수 있다.
메일 서버 엘리어싱(mail server aliasing): 만약 핫메일에 계정을 가졌다면 bob@hotmail.com 일 것이다. 그러나 핫메일의 정식 호스트 네임이 relay1.west-coast.enterprise.com 일 수도 있다. MX record는 기업의 메일 서버와 웹 서버가 같은 호스트 이름(별칭)을 갖는 것을 허용한다.
부하 분산(load distribution): cnn.com과 같은 인기 있는 사이트는 여러 서버에 중복되어 있어서, 각 서버가 다른 종단 시스템에 수행되고 다른 IP 주소를 갖는다. 중복 웹 서버의 경우, 여러 IP 주소가 하나의 정식 호스트 이름과 연관되어 있다. DNS 데이터베이스는 이 IP 주소 집합을 갖고 있다가, 각 응답에서 주소를 순환식으로 보낸다.
2.4.2. DNS 동작 원리 개요(Overview of How DNS Works)
DNS의 간단한 설계는 단일 DNS 서버에 중앙 집중 데이터베이스를 두는 것이다. 하지만 이는 아래와 같은 문제점이 있기에, DNS는 분산되도록 설계되었다.
- 서버의 고장: 단일 서버가 고장나면, 전체 인터넷이 작동하지 않는다.
- 트래픽 양: 단일 서버가 모든 질의를 처리해야 한다.
- 먼 거리의 데이터베이스: 질의가 지구 반대편까지 이동해야할 수도 있다.
- 유지관리: 데이터베이스가 거대해지고, 새로운 호스트를 위해 자주 갱신해야한다.
2.4.2.1. 분산 계층 데이터베이스(A Distributed, Hierarchical Database)
DNS는 많은 서버를 이용하고, 이들을 계층 형태로 구성하며 전 세계에 분산시킨다. 대체로 세 유형의 DNS 서버가 있다. 즉, 루트(root) DNS 서버, 최상위 레벨 도메인(TLD, top-level domain) DNS 서버, 책임(authoritative) DNS 서버이다.
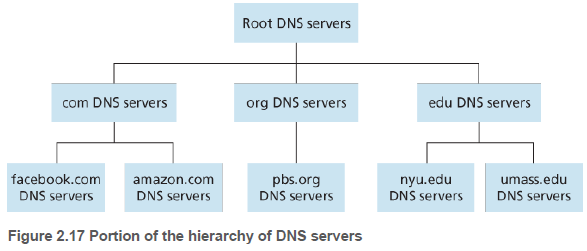
루트 DNS 서버: 인터넷에는 400개 이상의 루트 DNS 서버가 있다. 이 루트 서버들은 13개의 다른 기관에서 관리된다.
최상위 레벨 도메인 DNS 서버: com, org 같은 상위 레벨 도메인과 kr, uk 같은 모든 국가의 상위 레벨 도메인에 대한 TLD 서버가 있다.
책임 DNS 서버: 인터넷에서 접근하기 쉬운 호스트(예: 웹, 메일 서버)를 가진 기관은 공개적인 DNS 레코드를 제공해야 한다. 기관의 책임 DNS 서버는 이 DNS 레코드를 갖고 있다.
이 세 부류들의 서버들은 서로 상호 작용을 한다. 어떤 클라이언트가 www.amazon.com의 IP 주소를 원한다고 가정하자.
- 클라이언트는 루트 서버 중 하나에 접속하고, 루트 서버는 최상위 레벨 도메인 com을 갖는 TLD 서버 IP 주소를 보낸다.
- 클라이언트는 이 TLD 서버 중 하나에 접속하고, 서버는 도메인 amazon.com을 가진 책임 서버의 IP 주소를 보낸다.
- 클라이언트가 책임 서버 중 하나에 접속하면, 서버는 www.amazon.com 의 IP 주소를 보낸다.
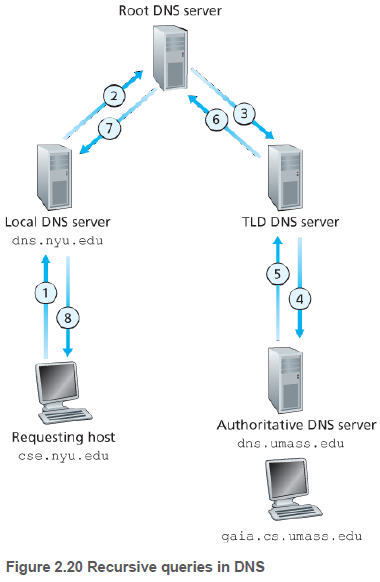
DNS의 다른 중요한 형태는 로컬 DNS 서버이다. ISP들은 로컬 DNS 서버를 갖는다.
호스트가 DNS 질의를 보내면, 이 질의는 먼저 프록시로 동작하는 로컬 DNS 서버에게 전달되고, 로컬 DNS 서버는 위의 1,2,3 같은 동작을 한 후 IP를 돌려준다.
이전 예에서 TLD 서버는 호스트 이름에 대한 책임 서버를 안다고 가정했다. 그러나 일반적으로 그렇지 않다.
대신 TLD 서버는 책임 서버를 아는 중간 DNS 서버만 알고 있다. 따라서 책임 서버에 도달할 때까지 반복적으로 질의가 이루어진다.
응답이 자신에게 직접 보내지는 질의를 반복적 질의(iterative query)라 한다.
자신을 대신하여 필요한 매핑을 얻도록 하는 것은 재귀적 질의(recursive query)라 한다.
이론상, DNS 질의는 반복적이고 재귀적일 수 있다. 일반적으로 요청하는 호스트로부터 로컬 DNS 서버까지 질의는 재귀적이고, 나머지 질의는 반복적이다.
2.4.2.2. DNS 캐싱(DNS Caching)
로컬 DNS 서버는 임의의 DNS 서버로부터 응답을 받을 때마다 이를 저장할 수 있다. 만약 저장된 호스트 이름에 대한 요청이 들어오면, 질의 없이 바로 IP 주소를 제공할 수 있다.
호스트 DNS와 IP 주소 사이의 매핑은 영구적인 것이 아니기 때문에 DNS 서버는 일정 기간 이후에 저장된 정보를 삭제한다.
2.4.3. DNS 레코드와 메세지(DNS Records and Messages)
DNS 서버들은 호스트 이름을 IP 주소로 매핑하기 위한 자원 레코드(resource record, RR)를 저장한다. 자원 레코드는 다음과 같은 필드를 포함하는 4개의 투플(tuple)로 되어 있다. TTL은 자원 레코드의 생존기간이다(캐시에서 제거되는 시간을 결정).
(Name, Value, Type, TTL)
Type=A이면, Name은 호스트 이름이고, Value는 IP 주소이다. (relay1.bar.foo.com, 145.37.93.126, A)
Type=NS이면, Name은 도메인이고, Value는 도메인 내부의 호스트에 대한 IP 주소를 얻을 수 있는 책임 DNS 서버의 호스트 이름이다. (foo.com, dns.foo.com, NS)
Type=CNAME이면, Name은 별칭이고, Value는 정식 호스트 이름이다.
(foo.com, relay1.bar.foo.com, CNAME)
Type=MX이면, Name은 별칭이고, Value는 메일 서버의 정식 이름이다. (foo.com, mail.bar.foo.com, MX)
한 DNS 서버가 책임 서버이면, Type A 레코드를 포함한다. 책임 서버가 아니라면, Type NS 레코드를 포함할 것이고, NS 레코드의 Value 필드에 있는 DNS 서버의 IP 주소를 제공하는 Type A 레코드도 포함할 것이다.
(umass.edu, dns.umass.edu, NS)
(dns.umass.edu, 128.119.40.111, A)
2.4.3.1. DNS 메세지(DNS Messages)
DNS 메세지는 질의 혹은 응답 메세지이며, 다음과 같은 내부 필드를 가지고 있다.
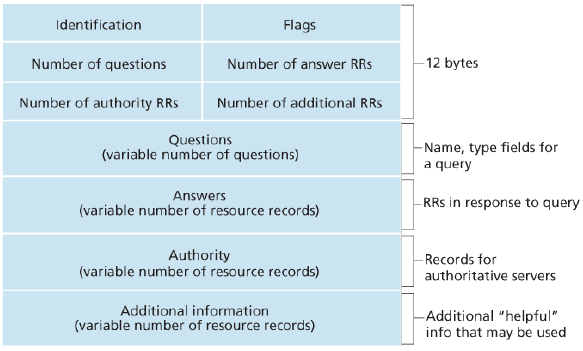
처음 12바이트는 헤더 영역으로, 첫 필드는 식별자이다. 이는 보낸 질의와 수신된 응답 간의 일치를 식별한다. 플래그 필드는 질의/응답 여부, 책임서버 여부, 재귀 요구 여부, 재귀 가능 여부를 나타내는 플래그 비트로 되어있다. 그리고 4개의 개수 필드가 있는데, 아래 네 가지 영역의 발생 횟수를 나타낸다.
질문 영역은 현재 질의에 대한 정보를 포함한다. 질의에 대한 이름, 타입을 가지고 있다.
답변 영역은 원래 질의된 이름에 대한 자원 레코드를 포함한다.
책임 영역은 다른 책임 서버의 레코드를 포함한다.
추가 영역은 다른 도움이 되는 레코드를 포함한다. 예를 들어 메일 서버의 정식 호스트 이름에 대한 IP 주소를 제공하는 Type A 레코드를 포함한다.
2.4.3.2. DNS 데이터베이스에 레코드 삽입(Inserting Records into the DNS Database)
먼저 도메인 이름 networkutopia.com을 등록기관(registrar)에 등록해야 한다. 등록기관은 이름의 유일성을 확인하고 데이터베이스에 넣는다.
도메인 이름을 등록할 때, 등록 기관에 주책임 DNS 서버와 부책임 DNS 서버 둘의 이름과 IP 주소를 제공해야 한다. 그리고 Type NS와 Type A 레코드가 등록된 것을 확인해야 한다.
2.5. P2P 파일 분배(Peer-to-Peer File Distribution)
P2P 구조는 간헐적으로 연결되는 호스트 쌍들(피어라고 부름)이 서로 직접 통신한다.
2.5.1. P2P 구조의 확장성(Scalability of P2P Architectures)
클라이언트-서버 구조와 P2P구조에서 커다란 파일을 한 서버에서 다수의 호스트(피어라고 부름)로 분배할 때 P2P 구조가 더 빠르다.
N개의 호스트가 있을 때, 클라이언트-서버 구조는 서버 혼자 N번 업로드해야 하지만, P2P 구조에서 각 피어는 수신한 파일의 임의의 부분을 다른 피어들에게 재분배할 수 있어서 서버를 도울 수 있다.
N개의 피어들이 파일의 복사본을 얻는 데 걸리는 최소 분배 시간이 P2P 구조의 경우가 항상 작다. 또한 N이 늘어나도 최소 분배 시간에 상한선이 있다.
따라서 P2P 구조를 가진 애플리케이션은 자가 확장성을 가진다. 이 확장성은 피어가 비트의 소비자이자 재분배자인 것의 결과이다.
2.5.2. 비트토렌트(BitTorrent)
비트토렌트는 파일 분배를 위한 인기 있는 P2P 프로토콜이다. 비트토렌트 용어로, 특정 파일 분배에 참여하는 피어들의 모임을 토렌트(torrent)라고 부른다.
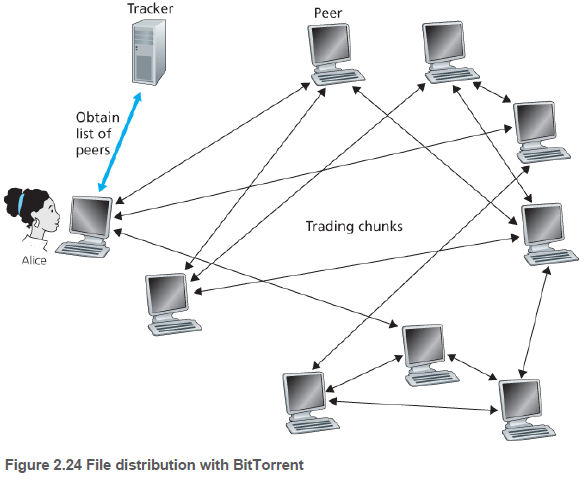
토렌트에 참여하는 피어들은 서로에게서 같은 크기의 청크(chunk)를 다운로드한다. 피어가 청크를 다운로드할 때, 피어는 또한 청크를 다른 피어들에게 업로드한다.
비트토렌트는 복잡한 프로토콜이기 때문에, 중요한 기법들만 기술한다. 각 토렌트는 트랙커(tracker)라고 부르는 기반구조 노드를 갖고 있다. 트랙커는 토렌트에 참여한느 피어들을 추적한다.
새로운 사용자가 토렌트에 가입할 때, 트랙커는 참여하고 있는 피어 집합에서 랜덤하게 피어들의 부분 집합을 선택하여 이 피어들의 IP 주소를 사용자에게 보낸다. 사용자는 선택된 모든 피어들과 TCP 연결을 하고, 이들을 이웃 피어라고 부른다.
어느 청크를 요청할 것인가를 결정하는 데 있어, 사용자는 가장 드문 것 먼저(rarest first)라고 하는 기술을 사용한다. 사용자가 가지고 있지 않은 청크 중에서, 이웃들 중에 가장 드문 청크(가장 적은 반복 복사본을 가진 청크)를 요구한다. 이런 방법으로 가장 드문 청크들은 더 빨리 재분배되어, 토렌트에 각 청크의 복사본 수가 동일하게 된다.
어느 피어에게 청크를 보낼 지를 결정하기 위해 현명한 교역(trading) 알고리즘을 사용한다. 이는 사용자에게 가장 빠른 속도로 데이터를 제공하는 이웃들을 주기적으로 갱신한다.
그리고 임의로 한 이웃을 추가로 선택하여, 이들에게 청크를 보내고, 나머지에게는 청크를 보내지 않는다. 피어는 더 좋은 파트너를 만날 때까지 교역을 계속한다. 이런 교역을 위한 보상 방식을 TFT(tif-for-tat)이라고 한다.
2.6. 비디오 스트리밍과 컨텐츠 분배 네트워크(Video Streaming and Content Distribution Networks)
2.6.1. 인터넷 비디오(Internet Video)
녹화된 비디오는 서버에 저장되어 사용자가 비디오 시텅을 서버에게 온디맨드(on-demand)로 요청한다.
비디오는 이미지의 연속으로서 일정한 속도로 표시된다. 비디오는 압축될 수 있는데, 많이 압축할 수록 비디오 품질은 하락하고 필요 비트 전송률도 낮아진다. 비트 전송률이 높아질수록 이미지 품질이 좋아지고 사용자 시청 환경이 향상된다.
고화질 4K 스트리밍은 10Mbps 이상의 비트 전송률이 필요하다. 영상시간이 67분인 2Mbps 비디오는 1GByte의 저장공간 및 트래픽을 소비한다.
스트리밍 비디오에서 중요한 성능 척도는 평균 종단간(end-to-end) 처리량이다. 연속재생을 위해, 네트워크는 압축된 비디오의 전송률 이상의 평균 처리량을 스티리밍 애플리케이션에 제공해야한다.
2.6.2. HTTP 스트리밍 및 대쉬(HTTP Streaming and DASH)
HTTP 스트리밍에서 비디오는 HTTP 서버 내의 특정 URL을 갖는 일반적인 파일로 저장된다. 그리고 요청이 들어오면, HTTP 응답 메세지 내에서 비디오 파일을 전송한다.
HTTP 스트리밍은 똑같이 인코딩된 비디오를 전송하고, 클라이언트들이 서로 다른 가용 대역폭을 가졌기에 문제가 되었다. 이로 인해 HTTP 기반 스트리밍인 DASH(Dynamic Adaptive Streaming over HTTP)가 개발되었다.
DASH에서 비디오는 여러 개의 서로 다른 버전으로 인코딩 되며, 각 버전은 서로 다른 비트율과 품질 수준을 갖고 있다. 클라이언트는 동적으로 비디오를 몇 초 분량의 길이를 가지는 비디오 조각(chunk) 단위로 요청한다. 가용 대역폭이 충분할 때에는 높은 비트율의 버전을, 적을 때는 낮은 비트율의 버전을 요청한다.
DASH를 사용할 때, 각 비디오 버전은 HTTP 서버에 서로 다른 URL을 가지고 저장된다. HTTP 서버는 비트율에 따른 각 버전의 URL을 제공하는 매니패스트(manifest) 파일을 가지고 있다. 그러므로 DASH는 클라이언트가 서로 다른 품질 수준을 자유롭게 선택할 수 있도록 허용한다.
2.6.3. 콘텐츠 분배 네트워크(Content Distribution Networks, CDN)
전 세계의 사용자들에게 비디오 데이터를 분배하기 위해, 비디오 스트리밍 회사들은 CDN을 이용한다. CDN은 다수의 지점에 분산된 서버들을 운영하며, 이곳에 비디오 및 다른 형태의 웹 콘텐츠 데이터의 복사본을 저장한다. 사용자는 최선의 서비스와 사용자경험(user experience)을 제공할 수 있는 지점의 CDN 서버로 연결된다.
CDN은 각 클러스터마다 서로 다른 복사본을 가지고 있다. 사용자가 지역 클러스터에 없는 비디오를 요청하면, 중앙서버나 다른 클러스터로부터 전송받아 저장하고 사용자에게 제공한다. 자주 사용되지 않는 비디오 데이터는 삭제된다.
2.6.3.1. CDN 동작(CDN Operation)
CDN은 사용자의 비디오 재생 요청을 가로채, (1) 사용자에게 가장 좋은 CDN 클러스터를 선택하고, (2) 요청을 클러스터의 서버로 보낸다.
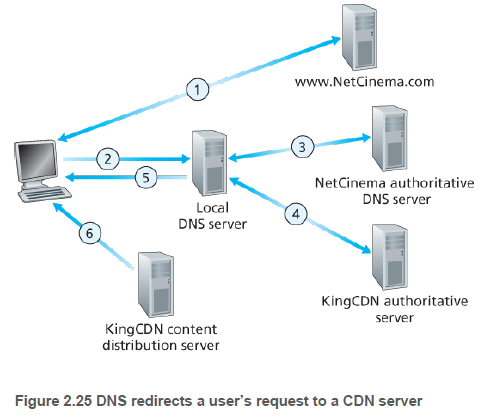
요청을 가로채고 다른 곳으로 연결하는 절차는 다음 예와 같다. NetCinema 라는 콘텐츠 제공자가 KingCDN이라는 CDN 업체를 이용해 비디오를 사용자에게 분배한다고 하자.
- 사용자가 NetCinema 웹페이지를 방문한다.
- 사용자가 http://video.netcinema.com/6Y7B23V 링크를 클릭하면, video.netcinema.com에 대한 DNS query를 보낸다.
- 로컬 DNS 서버(LDNS)는 요청을 NetCinema 책임 DNS 서버로 전달한다. 책임 DNS 서버는 kingCDN의 호스트 이름을 LDNS에게 알려준다.
- LDNS가 KingCDN 책임 서버에 요청을 보내고, KingCDN의 콘텐츠 서버의 IP 주소를 받는다. 이때 사용자가 접근할 CDN 서버가 결정된다.
- LDNS가 사용자에게 IP 주소를 알려주고, 사용자가 비디오에 대한 요청을 한다.
2.6.3.2. 클러스터 선택 정책(Cluster Selection Strategies)
앞에처럼 CDN은 사용자의 LDNS서버가 요청을 보냈기에 LDNS서버의 IP 주소를 알게 된다. 간단한 클러스터 선택은 이를 사용하여, 사용자에게 지리적으로 가장 가까운 클러스터를 할당한다.
하지만 문제점은 지리적으로 가까워도 네트워크 경로가 길 수도 있고, LDNS가 사용자로부터 멀 수도 있다는 점이다. 대안으로 CDN은 주기적으로 사용자와 클러스터간의 지연 및 손실 성능에 대한 실시간 측정(ping, DNS query 등)을 수행하기도 한다.
2.6.4. 사례연구(Case Studies)
2.6.4.1. 넷플릭스(Netflix)
아마존 클라우드를 사용한다. 영화의 스튜디오 마스터 버전을 클라우드 시스템에 업로드한다. 스마트폰, TV 등 다양한 플레이어 기기 사양에 작접하도록 각 영화의 여러 가지 형식의 비디오를 생성한다.
2.6.4.2. 유튜브(YouTube)
구글/유튜브의 디자인 및 프로토콜는 독점적이다. DASH와 같은 적응적 스트리밍 대신에 사용자가 스스로 버전을 선택하게 하였다. 여러 버전의 비디오 버전을 생성한다.
2.6.4.3. KanKan
CDN-P2P 스트리밍 시스템을 사용한다. 총 P2P 트래픽이 비디오 재생에 충분하면, 사용자는 CDN에서 스트리밍을 중단하고 피어를 통해서만 한다.
2.7. 소켓 프로그래밍: 네트워크 애플리케이션 생성(Socket Programming: Creating Network Applications)
두 형태의 네트워크 애플리케이션이 있다.
먼저 RFC 2616 (표준 HTTP 프로토콜)에 따라 클라이언트-서버 프로그램을 작성하면, 다른 개발자가 만든 프로그램에 제대로 상호작용할 수 있다. 이 프로토콜과 연관된 잘 알려진(well-known) 포트 번호(예를 들어 HTTP는 80)를 사용해야 한다.
혹은 개인이 프로그램에 완전한 제어를 가지고 공개되지 않은(개인이 정한) 프로토콜을 사용하면, 다른 개발자가 만든 프로그램과 상호작용 할 수는 없다. 그리고 잘 알려진 포트 번호를 사용하지 말아야 한다.
2.7.1. UDP를 이용한 소켓 프로그래밍(Socket Programming with UDP)
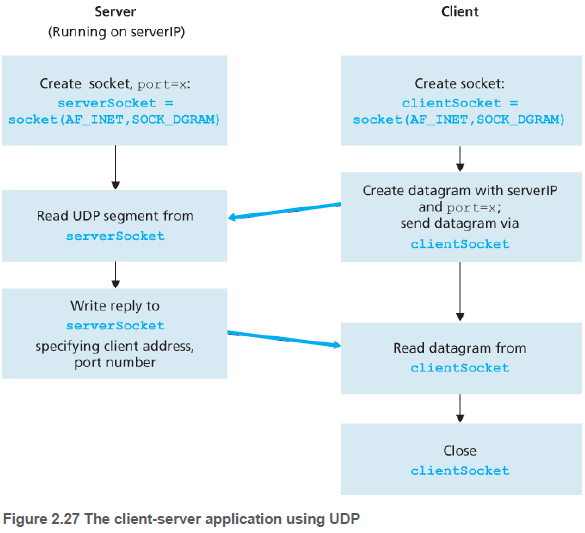
// UDPClient.py
from socket import *
// 호스트 이름 혹은 서버의 IP 주소
// 호스트 이름을 사용하면 IP 주소를 얻기 위해 DNS 검색이 수행됨
serverName = 'hostname'
serverPort = 12000
// AF_INET 은 IPv4를 의미, 4장 내용
// SOCK_DGRAM 은 UDP 소켓을 의미
clientSocket = socket(AF_INET, SOCK_DGRAM)
message = raw_input('Input lowercase sentence:')
// message.encode() 문자열 타입을 바이트 타입으로 변환
// sendto() 는 목적지 주소 (serverName, serverPort) 를 패킷에 붙이고 소켓으로 보냄
// 출발지 주소도 붙이나 이는 자동으로 수행됨
clientSocket.sendto(message.encode(), (serverName, serverPort))
modifiedMessage, serverAddress = clientSocket.recvfrom(2048)
print(modifiedMessage.decode())
clientSocket.close()
// UDPServer.py
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_DGRAM)
// 포트 번호를 소켓에 할당한다
// 서버 IP 주소의 12000 포트로 패킷을 보내면 해당 소켓으로 패킷이 전달된다
serverSocket.bind(('', serverPort))
print('The server is ready to receive')
while True:
message, clientAddress = serverSocket.recvfrom(2048)
// 대문자로 바꾸고 다시 보냄
modifiedMessage = message.decode().upper()
serverSocket.sendto(modifiedMessage.encode(), clientAddress)
2.7.2. TCP 소켓 프로그래밍(Socket Programming with TCP)
UDP와 달리 TCP는 연결지향 프로토콜로, 데이터를 보내기 전에 TCP 연결을 설정(handshake and establish)해야 한다. TCP 연결의 한쪽은 클라이언트 소켓에 연결되고, 다른 쪽은 서버 소켓에 연결된다.
TCP 서버는 클라이언트로부터의 초기 접속을 처리하는 환영(welcome) 소켓을 가져야 한다. 클라이언트는 TCP 소켓을 생성할 때, 이 환경 소켓의 IP 주소와 포트 번호를 명시한다. 소켓을 생성한 후 세 방향 핸드셰이크를 하고 TCP 연결을 설정한다.
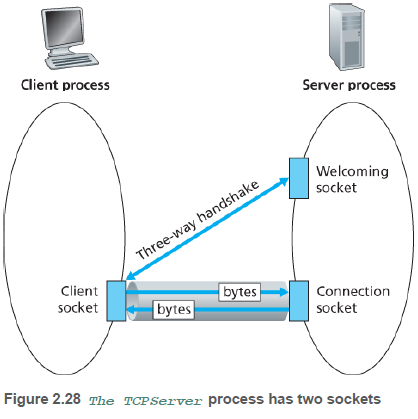
서버에 클라이언트가 세 방향 핸드셰이크를 통해 접근하면, 서버는 해당 클라이언트에 지정되는 새로운 소켓을 생성한다.
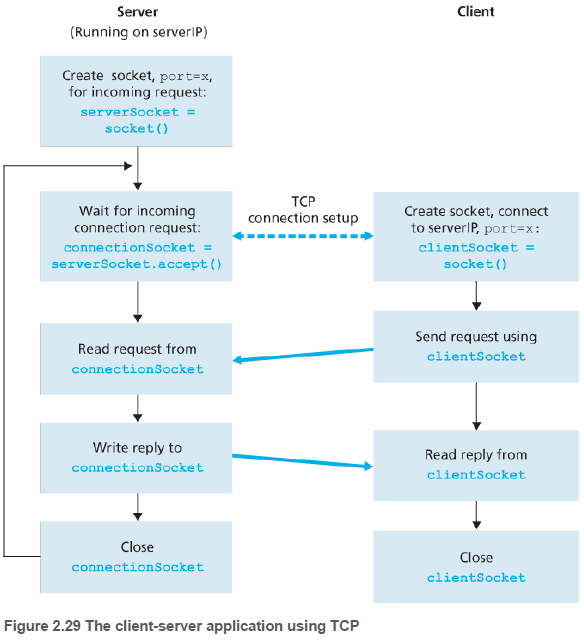
// TCPClient.py
from socket import *
serverName = 'servername'
serverPort = 12000
// SOCK_STREAM 은 TCP 소켓을 의미
clientSocket = socket(AF_INET, SOCK_STREAM)
// 데이터를 보내기 전에 TCP 연결이 설정되어야 함
clientSocket.connect((serverName, serverPort))
sentence = raw_input('Input lowercase sentence:')
// UDP 와 다르게 패킷에 목적지 주소가 필요없음, 위에서 설정됨
clientSocket.send(sentence.encode())
modifiedSentence = clientSocket.recv(1024)
print(’From Server: ’, modifiedSentence.decode())
clientSocket.close()
// TCPServer.py
from socket import *
serverPort = 12000
// 환영 소켓
serverSocket = socket(AF_INET, SOCK_STREAM)
serverSocket.bind(('', serverPort))
// TCP 연결 요청을 기다림, 최대 연결 수 1
serverSocket.listen(1)
print('The server is ready to receive')
while True:
// 클라이언트에 지정되는 소켓 생성
connectionSocket, addr = serverSocket.accept()
sentence = connectionSocket.recv(1024).decode()
capitalizedSentence = sentence.upper()
connectionSocket.send(capitalizedSentence.encode())
connectionSocket.close()
댓글남기기