컴퓨터 구조 요약 - 9. 파이프라인과 벡터 처리
9.1. 병렬 처리(Parallel Processing)
병렬 처리는 컴퓨터의 처리 속도와 처리율을 증가시키기 위해 동시 데이터 처리 기능을 제공하는 기술이다. 병렬 처리는 프로세서 내부구조, 연결 구조, 정보 흐름 등을 고려하여 다양한 방법으로 분류된다.
그 중 동시에 처리되는 명령어와 데이터 항목수에 따라 컴퓨터를 분류할 수 있다.
- 단일 명령어 흐름, 단일 데이터 흐름(SISD)
- 단일 제어 장치, 처리 장치, 메모리 장치, 순차적 명령어 실행
- 병렬 처리를 위해 다중 기능 장치, 파이프라인 처리 사용
- 단일 명령어 흐름, 다중 데이터 흐름(SIMD)
- 공통 제어 장치, 다중 처리 장치
- 처리 장치들의 동시 메모리 접근을 위해 다중 모듈을 가진 공유 메모리 장치 사용
- 다중 명령어 흐름, 단일 데이터 흐름(MISD)
- 이론적으로만 연구 되었음
- 다중 명령어 흐름, 다중 데이터 흐름(MIMD)
- 다중 처리 장치(프로세서), 다중 컴퓨팅 시스템
또한 다음과 같은 관점으로 병렬 처리를 살펴볼 수도 있다.
- 파이프라인 처리 - 산술 연산, 명령어 사이클 각 단계 중첩
- 벡터 처리 - 크기가 큰 벡터나 행렬 처리
- 배열 프로세서 - 큰 배열에 대한 계산
9.2. 파이프라인(Pipelining)
파이프라인이란 하나의 프로세스를 서로 다른 기능을 가진 여러 개의 서브프로세스로 나누어, 각 서브프로세스가 동시에 연산을 수행하는 기법이다. 각 세그멘트(segment)에서 수행된 연산 결과는 다음 세그먼트로 넘어가게 되며, 세그먼트 사이에 있는 레지스터가 중간 결과를 보관한다.
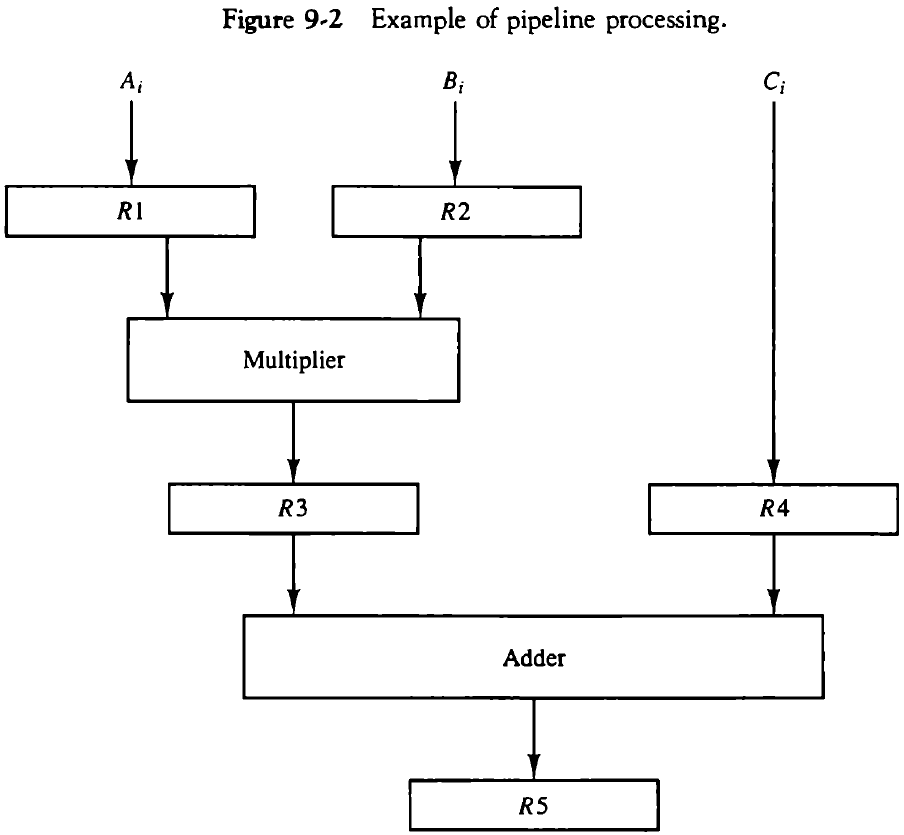

9.2.1. 일반적인 고찰(General Considerations)
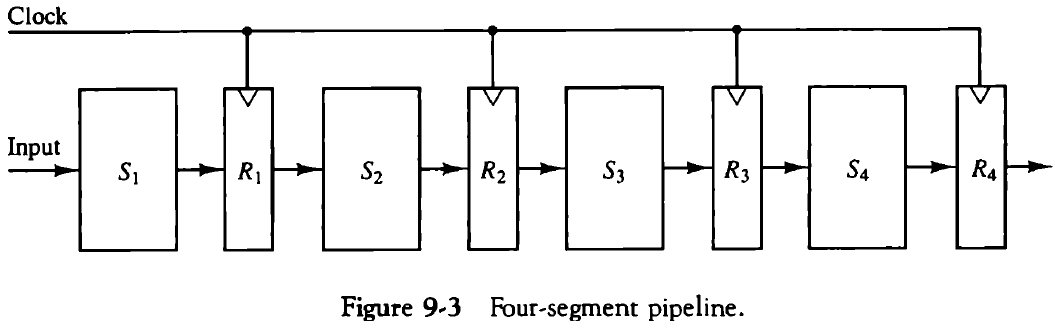
4개의 세그먼트를 가지는 파이프라인 구조가 아래 그림에 있다. 피연산자는 순서대로 세그먼트를 통과해간다. 모든 세그먼트를 지나쳐서 수행되는 전체 동작을 태스크(task)라고 정의한다.
파이프라인의 동작은 공간-시간(space-time)표에 의하여 설명되는데, 이것은 시간에 따른 세그먼트의 사용 상황을 보여준다.
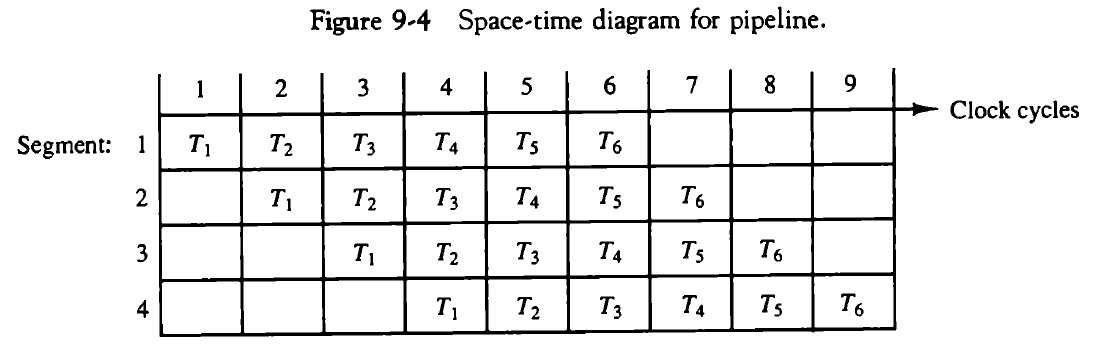
많은 세그먼트가 있더라도 일단 파이프라인이 채워진 후에는 매 클럭마다 출력을 얻을 수 있다. 이론적으로 파이프라인에 의한 최대 속도 증가율은 세그멘트 수와 같다.
하지만, 파이프라인은 최대 속도로 수행되지는 못한다. 각 세그먼트들이 수행되는 시간이 서로 다르기 때문에, 클럭 사이클이 최대 지연 시간을 갖는 세그먼트와 동일하게 결정되어야 한다.
9.3. 산술 파이프라인(Arithmetic Pipeline)
산술 연산 중 부동 소숫점 가산기를 아래와 같이 서브 프로세스로 나눌 수 있다.
- 지수의 비교
- 가수의 정렬
- 가수의 덧셈이나 뺄셈
- 결과의 정규화
9.4. 명령어 파이프라인(Instruction Pipeline)
명령어 파이프라인은 이전 명령어가 다른 세그먼트에서 실행되는 동안에 메모리의 다음 명령어를 읽어온다. 즉, 명령어의 fetch와 실행 단계가 중첩되어 동시에 수행된다. 단, 분기가 발생하면 파이프라인이 모두 비워져야하고, 분기 이후에 메모리에서 읽어온 명령어는 모두 무시되어야 한다.
일반적으로 명령어를 수행하기 위해 다음과 같은 순차적 수행이 필요하다.
- 메모리에서 명령어를 fetch 한다.
- 명령어를 디코딩한다.
- 유효 주소를 계산한다.
- 메모리에서 피연산자를 fetch 한다.
- 명령어를 실행시킨다.
- 결과를 적당한 곳에 저장한다.
9.4.1. 예: 네 세그먼트 명령어 파이프라인
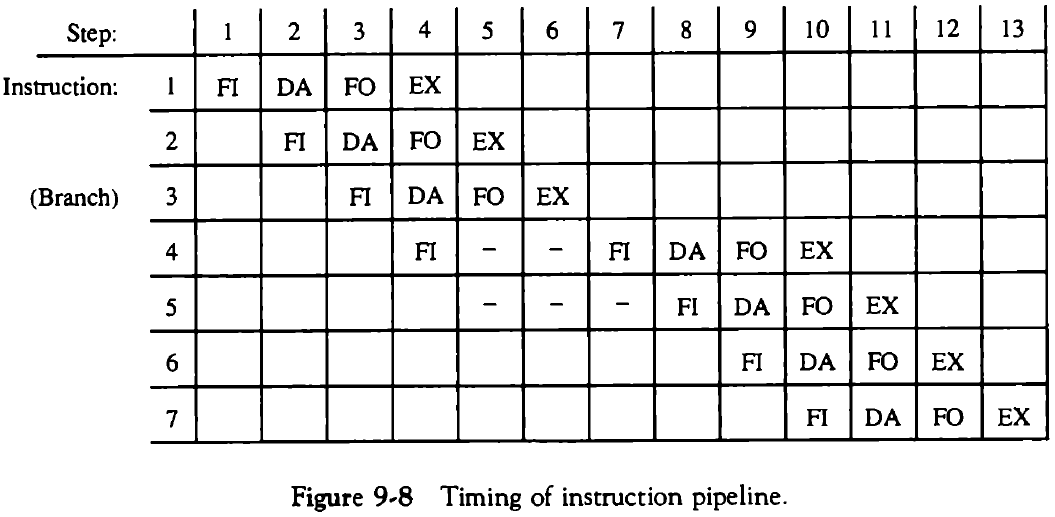
- FI는 명령어를 fetch 하는 세그먼트
- DA는 명령어를 디코드하고 유효 주소를 계산하는 세그먼트
- FO는 피연산자를 fetch 하는 세그먼트
- EX는 명령어를 실행시키는 세그먼트
일반적으로 명령어 파이프라인이 정상적인 동작에서 벗어나게 하는 원인은 다음과 같다.
- 자원 충돌 - 두 세그먼트가 동시에 메모리를 접근할 때 발생, 명령어 메모리와 데이터 메모리를 분리함으로써 대부분 해결
- 데이터 의존성 충돌 - 어떤 명령어가 이전 명령어의 결과를 기다릴 때 발생
- 분기 곤란 - 분기 명령어같이 PC 값을 변경시킬 때 발생
9.4.2. 데이터 의존성(Data Dependency)
데이터 의존성은 준비되지 않은 데이터를 기다리는 명령어가 있는 경우를 가르킨다.
가장 직접적인 해결방법은 하드웨어 인터락(hardware interlock)이다. 명령어의 피연산자가 앞서간 명령어의 목적지라면, 피연산자가 준비될 때까지 해당 명령어는 지연된다.
오퍼랜드 포워딩이라는 기법은 하드웨어로 충돌을 감지하고 별도의 통로를 통해 데이터를 세그먼트로 보낸다.
컴파일러가 데이터 충돌을 감지하고, 무동작(no-operation) 명령어를 삽입함으로써 충돌된 데이터의 참조가 지연되도록 명령어들을 재배치할 수도 있다. 이러한 방법을 지연된 로드(delayed load)라고 한다.
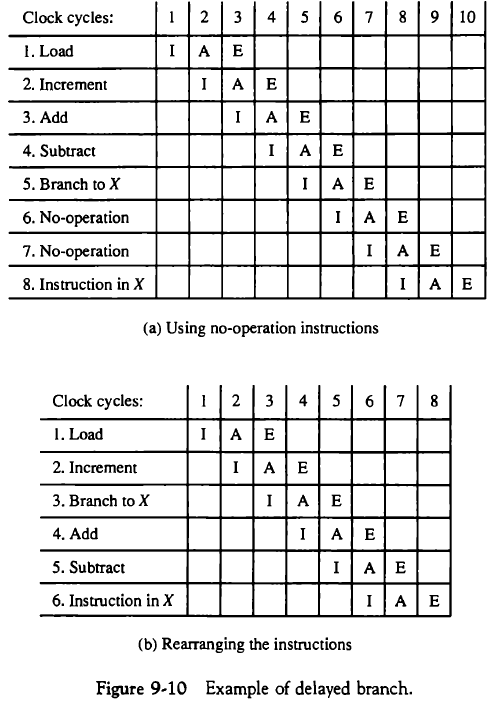
9.4.3. 분기 명령어의 처리(Handling of Branch Instructions)
분기가 발생하면 프로그램의 실행 순서가 바뀌기 때문에, 파이프라인이 전부 비워져야 한다.
조건 분기에서의 한 가지 해결 방법은, 분기 후 사용될 명령어를 같이 fetch 한 후, 분기가 수행될 때까지 저장하는 것이다. 혹은 조건문 모든 경우의 명령어를 fetch 해오는 것이다.
다른 방법으로 분기 목표 버퍼(branch target buffer, BTB)가 있다.
이는 어소시어티브(associative) 메모리(12.4절)이며, 이전에 실행된 분기 명령어, 그것의 분기 목표 명령어, 그 이후 몇 개의 명령어를 저장하고 있다.
파이프라인에서 분기 명령어가 디코드되면 버퍼에서 찾아보고, 존재한다면 바로 명령어를 사용할 수 있다.
따라서, 이전에 실행된 분기 명령어에 대해서는 파이프라인의 중단없이 진행할 수 있다.
BTB의 변형으로 루프 버퍼(loop buffer)가 있으며, 이는 파이프라인의 fetch 세그먼트에 유지되는 빠른 레지스터들이다. 버퍼는 프로그램 루프가 있는 경우에 분기를 포함한 모든 것을 저장한다. 따라서, 루프가 끝날 때까지 메모리를 참조하지 않고 루프를 수행할 수 있다.
분기 예측이라는 방법은 예측한 경로의 명령어를 미리 읽어오는데, 예측이 맞았을 경우 시간 낭비를 없앨 수 있다.
9.5. RISC Pipeline
RISC 컴퓨터는 파이프라인을 보다 효과적으로 이용할 수 있다. 명령어 집합이 단순하기 때문에 한 클럭 사이클에 수행되는 소수의 서브프로세스로 파이프라인을 구성할 수 있다. 또한 모든 피연산자가 레지스터에 있기 때문에 메모리로부터 피연산자를 읽어올 필요가 없다.
RISC 에서는 하드웨어 대신 컴파일러가 위의 문제점들을 해결하기도 한다.
9.5.1. 예: 세 세그먼트 명령어 파이프라인
9.5.1.1. 지연된 로드(Delayed Load)
컴파일러는 load 명령어 다음에 곧바로 메모리 데이터를 사용하는 명령어가 따라오면 무동작 명령어를 삽입하여 클럭 사이클을 낭비하도록 한다.
- I: 명령어의 fetch
- A: ALU의 동작
- E: 명령어의 실행
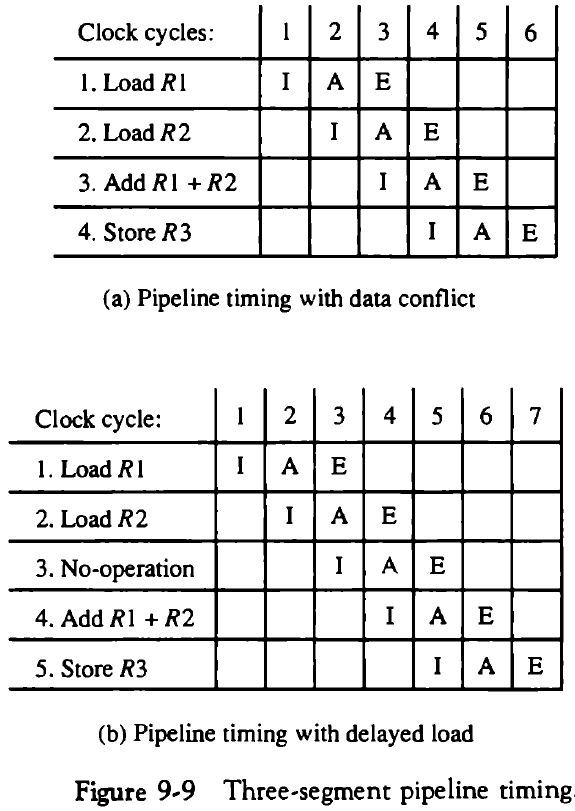
9.5.1.2. 지연된 분기(Delayed Branch)
컴파일러는 분기 명령어 전후에 있는 명령어들을 분석하여, 프로그램 결과에 영향을 주지 않으면서 분기 명령어 앞의 몇 개의 명령어들을 분기 명령어 다음으로 옮길 수 있다. 이것이 여의치 못한 경우에는 무동작 명령어를 삽입한다.
9.3. 벡터 처리(Vector Processing)
9.3.1. 벡터 연산(Vector Operations)
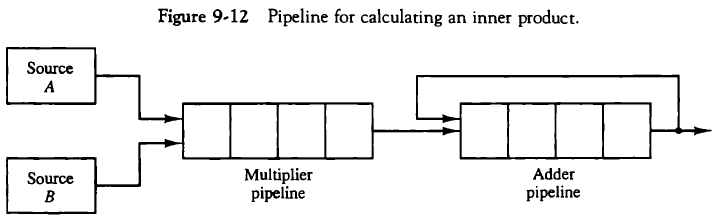
벡터는 일차원 배열에 대한 순서화된 집합이며, 방대한 수가 담긴 벡터를 빠르게 다루기 위해 벡터 프로세서가 사용된다.
길이가 100인 벡터 A, B를 더할 때, 벡터 명령어는 100번 루프를 돌며 명령어를 fecth, 실행할 필요 없이, 한 번의 명령어로 이를 수행할 수 있다. 이는 많은 수의 곱셈과 덧셈이 필요한 행렬 계산에서 특히 중요하다.

9.3.2. 행렬 곱셈(Matrix Multiplication)
9.3.3. 메모리 인터리빙(Memory Interleaving)
파이프라인이나 벡터 프로세서에서는 두 개 이상의 메모리 접근이 동시에 발생해 자원 충돌이 일어날 수 있다. 이를 해결하기 위해, 메모리를 여러 개의 모듈로 나누고 공통의 메모리 주소 버스와 데이터 버스로 연결하는 방법을 사용한다.
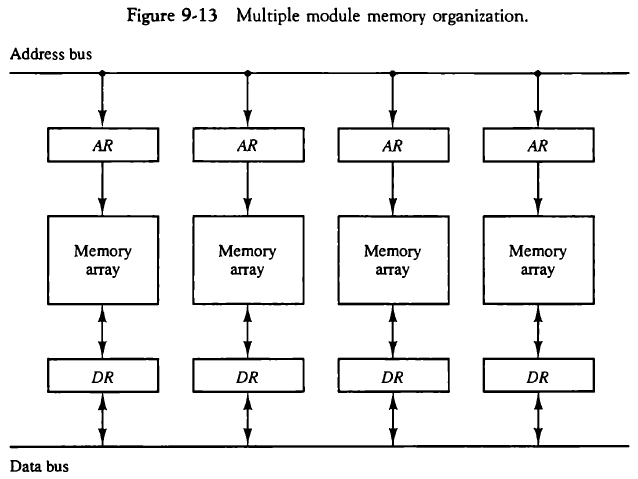
모듈로 나뉜 각 메모리에는 어드레스 레지스터와 데이터 레지스터가 붙는다. 이러한 모듈 메모리에는 인터리빙이란 기법이 적용되는데, 메모리에 있는 주소가 각 모듈에 대해 돌아가며 연속적으로 있게 하는 기법이다.
3개 모듈로 나뉘었을 때,
주소 1 -> 1번 모듈
주소 2 -> 2번 모듈
주소 3 -> 3번 모듈
주소 4 -> 1번 모듈
주소 5 -> 2번 모듈
주소 6 -> 3번 모듈
9.7. 배열 프로세서(Array Processors)
배열 프로세서는 대규모의 데이터 배열에 대한 계산을 수행하는 프로세서이다.
9.7.1. 부가 배열 프로세서(Attached Array Processor)
부가 배열 프로세서는 컴퓨터에 부착하여 수치 계산 작업에 대한 컴퓨터의 성능을 향상시킬 수 있다.
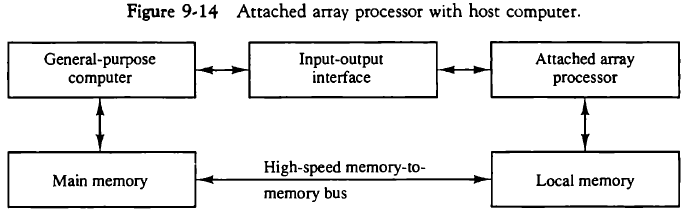
9.7.2. SIMD 배열 프로세서(SIMD Array Processor)
SIMD 배열 프로세서는 벡터나 행렬 형식 수치 계산에만 적합하기에 더이상 사용되지 않는다.
댓글남기기