컴퓨터 구조 요약 - 13. 멀티프로세서
13.1. 멀티프로세서의 특성(Characteristics of Multiprocessors)
멀티프로세서 시스템은 메모리와 입출력 장치를 공유하는 두 개 이상의 CPU를 가진 시스템을 말한다. 이는 하나의 운영체제에 의해 프로세서와 시스템의 다른 요소들 사이의 상호동작이 제어된다.
멀티프로세서 구조로부터 얻을 수 있는 이점은 계산이 병렬 처리되어 시스템의 성능이 향상된다는 것이다. 다수의 독립적인 작업들이나, 하나의 작업이 여러 부분으로 나뉘어 병렬적으로 수행될 수 있다.
멀티프로세서는 메모리 구조에 따라서 분류가 되는데, 공유 메모리를 가진 밀착결합 멀티프로세서, 프로세서 각각 개별적인 로컬 메모리를 가지는 느슨히 결합된 멀티프로세서가 있다. 그러나 밀착결합 멀티프로세서도 캐시 메모리와 같은 로컬 메모리를 가질 수 있다.
13.2. 상호연결 구조(Interconnection Structures)
멀티프로세서 시스템을 형성하고 있는 요소들에는 CPU, IOP, 모듈로 분리된 메모리 장치가 있다.
13.2.1. 시분할 공통 버스(Time-Shared Common Bus)
다수의 프로세서가 공통의 통로를 통하여 메모리 장치에 연결된 시스템이다. 오직 하나의 프로세서만이 주어진 시간에 전송이 가능하다.
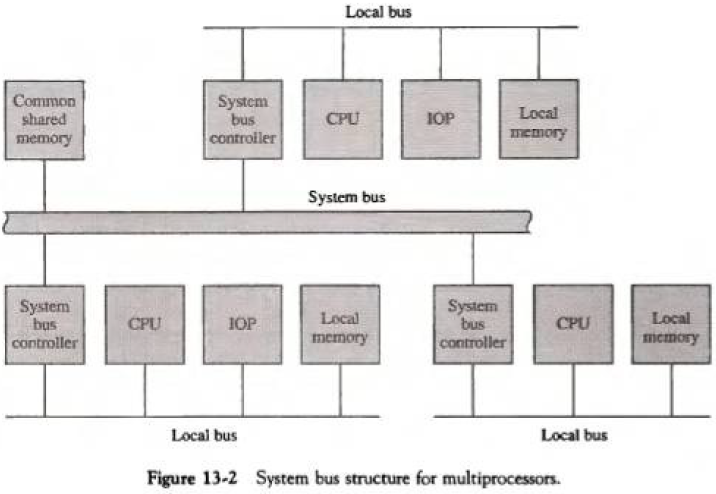
느슨히 결합된 구조같이 로컬 메모리/버스를 가지며, 메모리 하나를 공유하는 이중 버스(dual bus)도 있다.
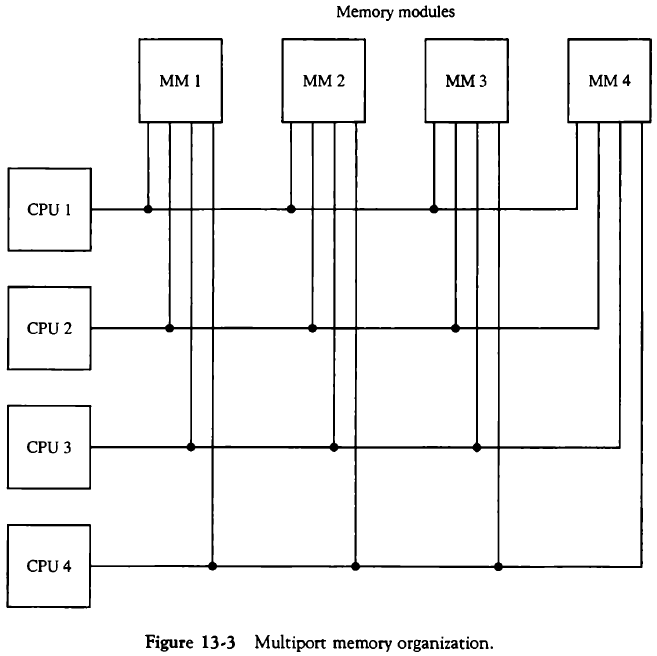
13.2.2. 다중포트 메모리(Multiport Memory)
CPU나 IOP와 각 메모리 모듈 사이에 각각의 버스를 갖고 있는 시스템이다. 다중 통로에 의해 높은 전송률을 보이나 값이 비싸다.
13.2.3. 크로스바 스위치(Crossbar Switch)
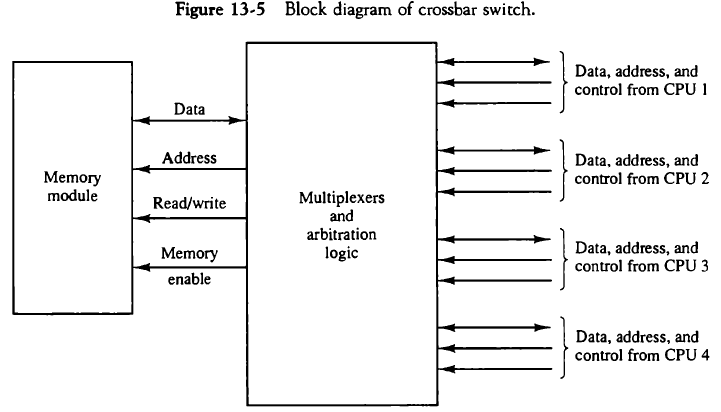
프로세서 버스와 메모리 모듈 통로간의 교차점에 다수의 크로스포인트(crosspoints)를 구성한 시스템이다.
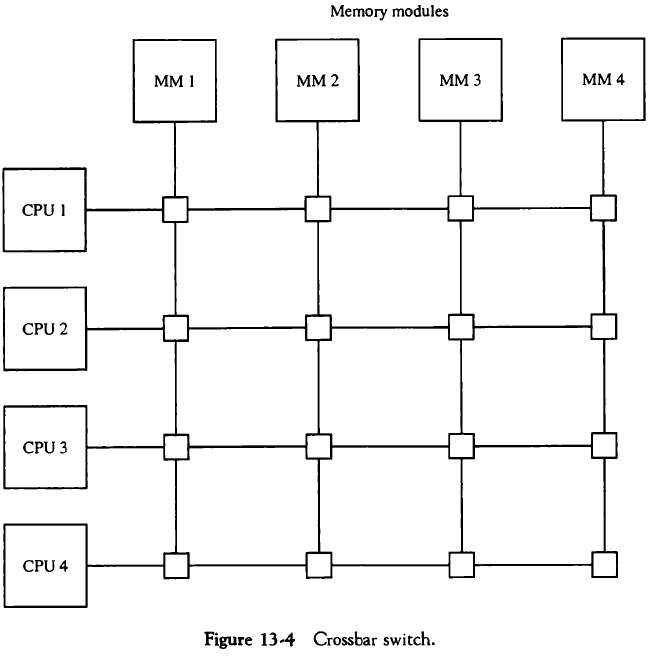
크로스포인트는 프로세서와 메모리 모듈간 통로를 결정하는 제어 논리를 가진 스위치이다. 모든 메모리 모듈로부터 동시 전송이 가능하나 스위치 하드웨어가 너무 크고 복잡하다.
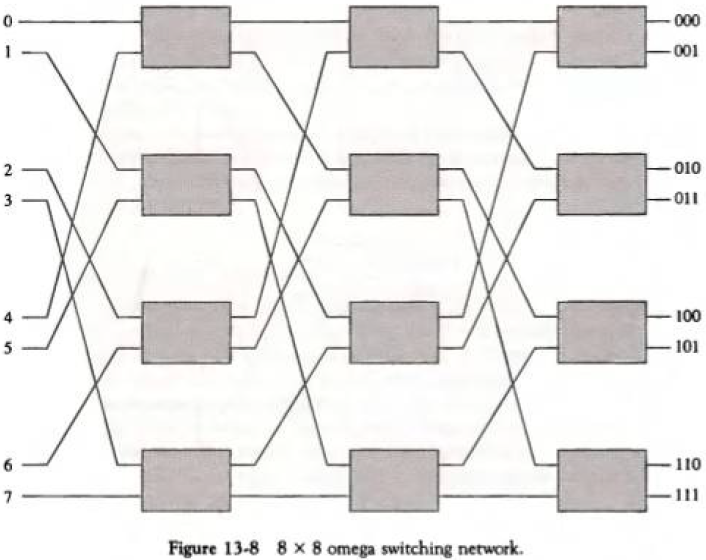
13.2.4. 다단 교환망(Multistage Switching Network)
2입력, 2출력(0, 1) 통신을 제어하는 상호교환 스위치로 이루어져있는 시스템이다. 이진수를 사용해 출발지에서 목적지까지의 경로를 결정한다.
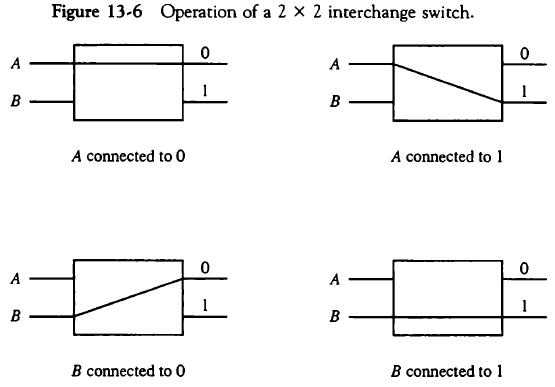
스위치가 쌓여감에 따라 경우의 수가 늘어난다. 2계층일 때 (00, 01, 10, 11)
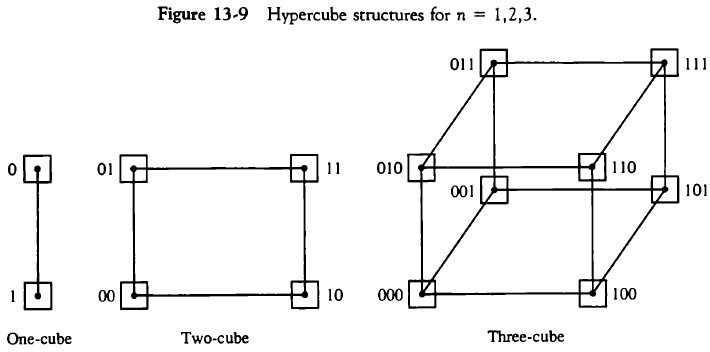
13.2.5. 하이퍼큐브 시스템(Hypercube Interconnection)
N=2n개의 프로세서가 n차원 이진 큐브 구조로 느슨히 결합된 시스템이다. 서로 이웃한 노드(CPU, IOP, 메모리)는 직접 통신 가능하나, 나머지는 다른 링크를 거쳐야 한다.
13.3. 프로세서간의 중재(Interprocessor Arbitration)
공유 메모리 멀티프로세서 시스템에서 프로세서는 시스템 버스를 통하여 공유 자원에 대한 접근을 요구한다. 이때 다른 프로세서가 동시에 시스템 버스를 요구한다면 공유 자원에 대한 충돌을 해결하기 위한 중재 동작이 수행되어야 한다.
13.3.1. 시스템 버스(System Bus)
시스템 버스는 많은 신호 라인으로 구성된다.

13.3.2. 직렬 중재 절차(Serial Arbitration Procedure)
로컬 버스와 시스템 공통 버스 사이에 놓인 시스템 버스 제어기에는 중재를 위한 논리 회로가 설계되어 있다. 이러한 중재는 버스 중재자의 데이지 체인 연결로, 우선순위를 바탕으로 이루어진다.
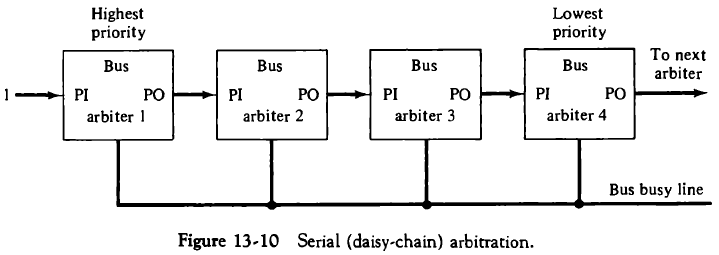
각 프로세서는 자신의 버스 조정 논리 회로를 갖고 있으며 가장 우선순위가 높은 중재자가 먼저 할당 받는다. 그리고 bus busy line을 통해 버스가 사용되고 있음을 알린다.
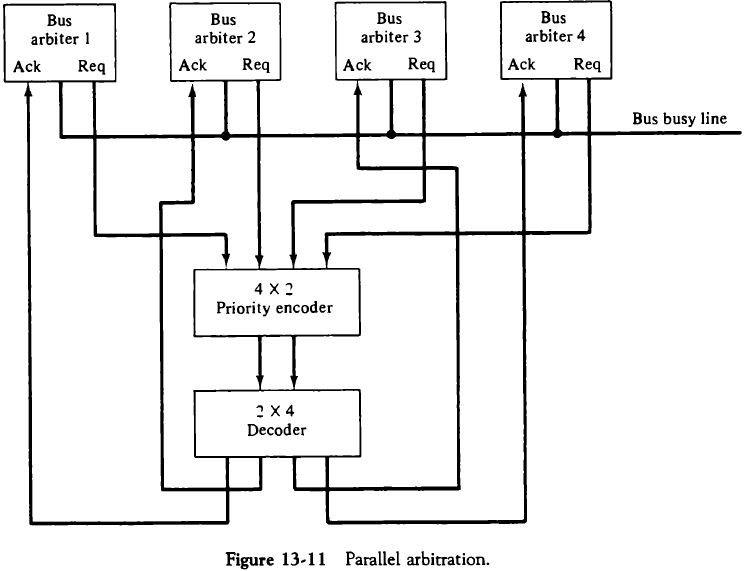
13.3.3. 병렬 중재 논리(Parallel Arbitration Logic)
버스 중재자들이 우선순위 인코더와 디코더에 연결되어 중재되는 기법이다. 버스의 요청 라인을 통해 인코더에 입력을 넣고, 우선순위에 따라 버스 승낙 입력을 통해 버스를 할당 받는다.
13.3.4. 동적 중재 알고리즘(Dynamic Arbitration Algorithms)
직렬/병렬 중재 방법은 각 장치의 우선순위가 고정되어 있다. 동적 우선순위 알고리즘은 시스템이 동작하고 있는 동안에도 장치들의 우선순위를 변경시킬 수 있다.
- 시간분할
- 버스 시간을 고정된 길이의 시간 분할으로 나누고, 라운드-로빈(round-robin) 방식으로 프로세서에게 할당한다.
- 폴링
- 모든 장치에 폴(poll)라인을 연결한다.
- 폴 라인을 통하여 버스 제어기가 각 장치의 주소를 결정하며, 주소를 통하여 버스 제어기가 순차적으로 동작한다.
- 폴링의 순서는 프로그램으로 변경 가능하다.
- LRU
- 가장 오랫동안 버스를 사용하지 않은 장치에게 가장 높은 우선순위를 부여한다.
- first-com, first-serve
- FIFO방식으로 버스 서비스를 제공한다.
- 회전 데이지 체인
- 데이지 체인의 변형으로, 버스를 사용했던 중재기는 가장 낮은 우선순위를 가지게 된다.
- 각 중재기의 우선순위는 바로 직전에 버스를 제어했던 프로세서의 중재기로부터의 거리이다.
13.4. 프로세서간 통신과 동기화(Interprocessor Communication and Synchronization)
멀티프로세서의 프로세서들은 공통의 입출력 채널을 통하여 서로 통신한다. 예를 들어, IOP에 연결된 자기 디스크 저장 장치를 통하여 시스템 프로그램을 공유할 수 있다.
공유 메모리 멀티프로세서 시스템에서는 메모리의 일부분을 모든 프로세서가 접근할 수 있도록 할당한다. 공유 메모리는 프로세서들 사이에서 오가는 메세지의 집중지 역활을 한다.
메세지를 보냈다는 신호는 소프트웨어에 의한 프로세서간 인터럽트로 구현한다. 송신 프로세서가 수신 프로세서에게 인터럽트를 보내 새로운 메세지를 보냈다고 알린다.
멀티프로세서를 위한 운영체제 구조는 세 가지 종류가 있다.
- 주종(master-slave)모드
- 주(master)가 되는 프로세서는 항상 운영체제의 기능을 수행한다.
- 나머지 프로세서에서 운영체제의 서비스가 필요하면 주 프로세서에게 인터럽트를 보낸다.
- 분리 운영체제(separate operating system) 구조
- 각 프로세서가 필요한 운영체제 루틴을 수행한다.
- 분산 운영체제(distributed operating system)
- 운영체제가 여러 프로세서에 분산되어 있다.
- 운영체제의 특정 기능은 한 순간에 하나의 프로세서에만 할당되어 수행된다.
13.4.1. 프로세서간 동기화(Interprocessor Synchronization)
동기화는 처리될 작업들간의 정확한 순서를 유지하고 공용의 기록 가능한 변수에 대해 상호배제(mutual exclusive)적 접근을 보장한다. 상호배제에 널리 사용되는 것은 이진 세마포(semaphore)이다.
멀티 프로세서 시스템에서는 두 개 이상의 프로세서에 의해서 데이터가 동시에 변화되는 것을 막기 위해, 공용 메모리나 다른 자원에 차례대로 접근할 수 있도록 하는 기법을 제공한다. 한 프로세서가 임계 프로그램 영역(critical program section)에 있을 때, 다른 프로세서가 접근하지 못하도록 한다.
임계 프로그램 영역이란 한 번 시작하면 다른 프로세서가 같은 공용 자원에 접근하기 전에 실행을 완료해야 하는 프로그램 시퀸스를 말한다. 세마포라 불리는 이진 변수는 프로세서가 임계 프로그램 영역을 실행하고 있는지의 여부를 나타낸다.
프로세서는 공용 자원을 사용하기 전에 세마포를 조사하고, 1이면 사용할 수 없다. 0이면 세마포를 1로 만들고 사용하고, 끝난 후에 0으로 세트한다.
13.5. 캐시의 일관성(Cache Coherence)
멀티프로세서에서는 동일한 내용의 정보가 여러 개의 캐시나 주기억 장치에 복사본으로 중복되어 저장될 가능성이 있다. 읽기 전용 데이터는 안전하게 복사될 수 있지만, 공통의 기록 가능한 데이터는 문제가 될 수 있다. 정확한 메모리 동작을 보장하기 위해서 여러 개의 복사본들이 모두 동일하게 유지되어 캐시의 일관성(cache coherence)를 보장해야 한다.
캐시의 일관성 문제는 소프트웨어와 하드웨어 결합에 의한 방법이나 하드웨어만의 방법으로 해결 할 수 있다.
소프트웨어에 기반을 둔 방법으로는 중앙집중식 전역표(centralized global table)이 있다. 이 표에는 메모리 블럭의 상태가 저장되는데, 각각의 블럭은 읽기전용(read-only, RO)이거나 읽기 및 쓰기(read and write, RW)로 표시된다. 모든 캐시는 RO로 표시된 블럭의 복사본만 가지며, 단 하나의 캐시만이 RW블럭에 대한 복사본을 가질 수 있다.
하드웨어만의 한 해결책은 스누피(snoopy) 캐시 제어기를 활용하고 write-through정책을 사용하는 것이다. 캐시 제어기는 CPU와 IOP로부터 나오는 모든 버스 요구를 감시한다. 캐시의 워드가 갱신될 때, 주기억 장치에서 같은 위치에 해당하는 데이터를 갱신한다.
그 후, 다른 모든 캐시에 달려 있는 로컬 스누피 제어기가 갱신된 데이터에 대한 복사본이 있는지 자신의 로컬 메모리를 검사한다. 만약 존재한다면 이를 무효라고 표시하며, 나중에 프로세서가 무효화된 데이터에 접근하게 되면 캐시 실패라고 응답받고 주기억 장치로부터 데이터를 가져온다.
댓글남기기